
번역 흐름
규칙 기반 기계 번역(RBMT, Rule-Based Machine Translation)
참조링크 https://m.blog.naver.com/newheater/221763031420
[역사 속 사진] 1954년 1월 7일, 기계 번역의 역사를 만든 '조지타운-IBM 실험' 시연
지금은 스마트폰의 앱으로도 세계의 다양한 언어를 실시간으로 자동 번역하는 세상이 되었습니다. 인류 역...
blog.naver.com
- 규칙에 없는 문장이 들어올 경우 번역이 불가능
- 모든 규칙을 정의하기가 사실상 불가능
- 유연성이 떨어짐
통계적 기계 번역(SMT, Statistical Machine Translation)
참조링크 https://wikidocs.net/21687
2) 통계적 언어 모델(Statistical Language Model, SLM)
언어 모델의 전통적인 접근 방법인 통계적 언어 모델을 소개합니다. 통계적 언어 모델이 통계적인 접근 방법으로 어떻게 언어를 모델링 하는지 배워보겠습니다. 통계적 언어 모델( ...
wikidocs.net
- 규칙 기반 모델에 비해 개발 비용이 저렴함
- 데이터가 많을 수록 유연한 문장 생성이 가능
- 데이터에 문장이 나온 적이 없으면 번역 불가능
- 어순에 대한 고려가 없어 어색한 문장 생길 수도 있음
- 희소문제, 올바른 문장이지만 확률을 0으로 정의하게 됨
SMT의 동작은 문장의 자연스러움과, 문법 구조를 고려해야 하기 때문에 단순히 확률 적인 계산으로만 문장을 생성할 수 없음. 이에 따라 원문과 번역문간의 단어 매핑 관계를 추가로 고려하는데 이때 관계를 정렬(Alignment)이라고 함
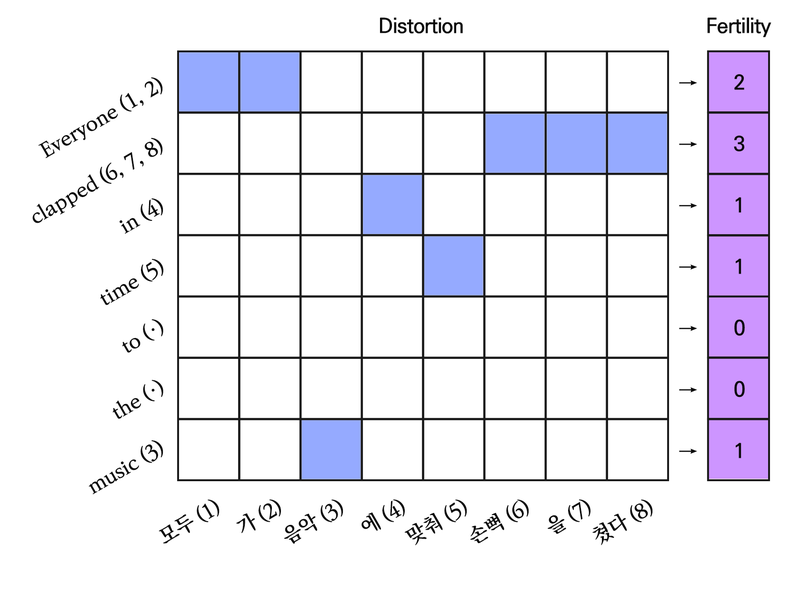
정렬의 종류
퍼틸리티
원문의 각 단어가 번역 후에 몇 개의 단어로 나타나는지 의미하는 값으로, 위의 예에서 Everyone의 퍼틸리티는 2, Clapped의 퍼틸리티는 3
번역에 직접 등장하진 않지만 p(n|w)로 정의됨
왜곡
원문의 단어가 번역문에서 존재하는 위치를 나타내는 값으로 위 예에서 Clapped는 손뼉(6) 을 (7) 쳤다(8)로 번역되어 Clapped의 왜곡은 (6,7,8)로 나타남
p(t|s, l)로 정의되며 t=번역문에서 단어의 위치, s=원문에서 단어의 위치, l은 번역문의 길이
Greedy Decoding
def generate_text(model, tokenizer, init_sentence="<start>", max_len=20):
test_input = tokenizer.texts_to_sequences([init_sentence])
test_tensor = tf.convert_to_tensor(test_input, dtype=tf.int64)
end_token = tokenizer.word_index["<end>"]
while True:
predict = model(test_tensor)
predict_word = tf.argmax(tf.nn.softmax(predict, axis=-1), axis=-1)[:, -1]
test_tensor = tf.concat([test_tensor, tf.expand_dims(predict_word, axis=0)], axis=-1)
if predict_word.numpy()[0] == end_token: break
if test_tensor.shape[1] >= max_len: break
generated = ""
for word_index in test_tensor[0].numpy():
generated += tokenizer.index_word[word_index] + " "
return generated
# 단어 예측 포인트
predict_word = tf.argmax(tf.nn.softmax(predict, axis=-1), axis=-1)[:, -1]가장 높은 확률을 갖는 단어가 다음 단어로 결정 되는 순간으로, 탐욕 알고리즘이 사용됨, Greedy Decoding
[알고리즘] Greedy Algorithm (탐욕 알고리즘)
탐욕 알고리즘 정의 : 미리 정한 기준에 따라서 매번 가장 좋아 보이는 답을 선택하는 알고리즘 동적 계획법과 마찬가지로 최적화 문제를 푸는데 사용한다. 근시안적으로 해를 구할 당시에 가
janghw.tistory.com

일반적인 경우 잘 작동하지만 have가 마시다라는 뜻으로 사용되는 데이터가 적다면 greedy 알고리즘은 가지다로 밖에 번역할 수 없음
Beam Search
지금 상황에서 가장 높은 확률을 갖는 Top-k 문장만 남김
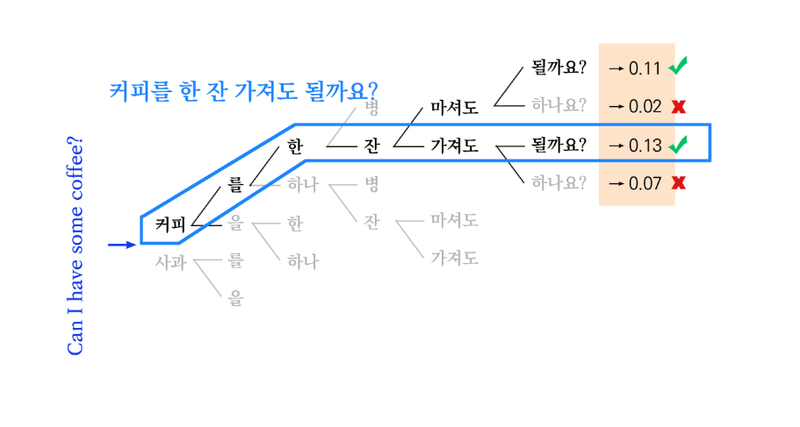
상위 몇 개의 문장을 기억할지 = Beam Size( 또는 Beam Width)
Beam Size를 키울수록 성능이 좋지만 그만큼 연산량이 증가하게 됨
대체로 5나 10을 사용하나 스스로 찾아보는 노력이 필요함
import math
import numpy as np
def beam_search_decoder(prob, beam_size):
sequences = [[[], 1.0]] # 생성된 문장과 점수를 저장
for tok in prob:
all_candidates = []
for seq, score in sequences:
for idx, p in enumerate(tok): # 각 단어의 확률을 총점에 누적 곱
candidate = [seq + [idx], score * -math.log(-(p-1))]
all_candidates.append(candidate)
ordered = sorted(all_candidates,
key=lambda tup:tup[1],
reverse=True) # 총점 순 정렬
sequences = ordered[:beam_size] # Beam Size에 해당하는 문장만 저장
return sequences
vocab = {
0: "<pad>",
1: "까요?",
2: "커피",
3: "마셔",
4: "가져",
5: "될",
6: "를",
7: "한",
8: "잔",
9: "도",
}
prob_seq = [[0.01, 0.01, 0.60, 0.32, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01],
[0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.75, 0.01, 0.01, 0.17],
[0.01, 0.01, 0.01, 0.35, 0.48, 0.10, 0.01, 0.01, 0.01, 0.01],
[0.24, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.68],
[0.01, 0.01, 0.12, 0.01, 0.01, 0.80, 0.01, 0.01, 0.01, 0.01],
[0.01, 0.81, 0.01, 0.01, 0.01, 0.01, 0.11, 0.01, 0.01, 0.01],
[0.70, 0.22, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01],
[0.91, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01],
[0.91, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01],
[0.91, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01]]
prob_seq = np.array(prob_seq)
beam_size = 3
result = beam_search_decoder(prob_seq, beam_size)
for seq, score in result:
sentence = ""
for word in seq:
sentence += vocab[word] + " "
print(sentence, "// Score: %.4f" % score)
커피 를 가져 도 될 까요? <pad> <pad> <pad> <pad> // Score: 42.5243
커피 를 마셔 도 될 까요? <pad> <pad> <pad> <pad> // Score: 28.0135
마셔 를 가져 도 될 까요? <pad> <pad> <pad> <pad> // Score: 17.8983좋은 번역을 고르는 방법일 뿐 학습에 적용할 수는 없음
Sampling
언어 모델이 반복적으로 다음 단어에 대한 확률 분포를 생성하는데 이때 그 확률 분포를 기반으로 랜덤하게 단어를 뽑는 방법
실제 서비스에는 거의 사용하지 않지만 모델 학습시에 사용되는 경우가 있음. BackTranslation이 대표적 사례
Data Augmentation
개념 참조 사이트
12. Data Preprocessing & Augmentation
Augmentation은 원래 데이터를 부풀려서 성능을 더 좋게 만든다는 뜻이다. 대표적인 케이스가 VGG모델에서 많이 사용하고 벤치마킹하였다. VGG-D모델에서 256*256 데이터를 넣어주는 것보다 똑같은 사
nittaku.tistory.com
Lexical Substitution(어휘 대체 방법)
동의어 기반 대체
Thesaurus란 어떤 단어의 동의어나 유의어를 집중적으로 구축해놓은 사전으로 대표적으로 WordNet이 있음
시소러스를 활용한 단어 의미 파악 - Natural Language Processing with PyTorch
그림을 보면 'bank'라는 단어에 대해 명사noun일 때의 의미 10개, 동사verb일 때의 의미 8개를 정의했습니다. 명사 'bank#2'의 경우에는 여러 다른 표현(depository finaancial institution#1, banking concern#1)들도 같
kh-kim.gitbook.io
한국어 버전으로 부산대학교의 KorLex, 카이스트의 Korean Word Net(KWN)이 있음
사용 예시

Embedding 활용
Pre-training Word Embedding을 활용하는 것
Embedding의 유사도를 기반으로 단어를 대체함
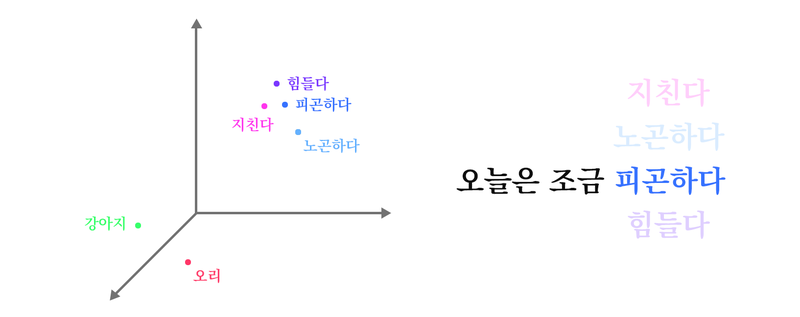
gensim의 most_simillar()
TF-IDF

TF-IDF는 여러 문서를 기반으로 단어마다 중요도를 부여하는 알고리즘
TF-IDF가 값을 갖는 단어들은 핵심 단어가 아니므로 다른 단어로 대체해도 문맥이 크게 변하지 않는 방법을 사용
Back Translation
Back Translation 정리
: 번역기 성능 영혼까지 끌어모으기
dev-sngwn.github.io
Synthetic Source Sentence

Source - Target 병렬 말뭉치가 있을 때 S-T 학습한 모델 A, T-S 학습한 모델 B를 통해서 서로 반대 방향에 대한 언어 데이터를 생성하여 병렬쌍으로 활용함
이때 문장 생성하는 기법 중 가장 효과를 보인 것이 Beam + Noise 기법
back translation은 데이터수와 관련없이 효과를 볼 수 있음
Random Noise Injection
오타 추가
사람들이 주로 사용하는 QWERTY 키보드상에서 키의 거리를 기반으로 노이즈를 추가하는 방법
공백 추가
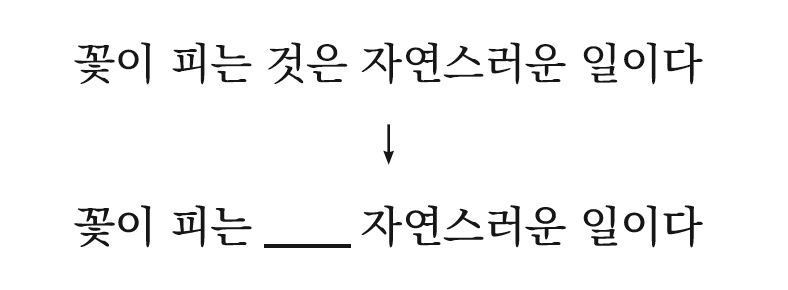
_ 토큰을 활용하는 방법으로 Placeholder Token(공백 토큰)을 사용하며 문장 일부 단어를 공백 토큰으로 치환해서 학습 과적합을 방지하는 효과를 봄
유의어 추가
주어진 문장에서 불용어(Stop word)가 아닌 단어를 랜덤하게 뽑은 후 해당 단어와 유사한 단어를 골라 문장에 삽입

Lexical Substitution 비슷하지만 원본 단어의 손실이 없음
기계 번역의 평가
BLEU(Bilingual Evaluation Understudy) Score로 기계가 실제 번역을 얼마나 재현했는지에 대한 평가
- n-gram을 통해 순서쌍이 얼마나 겹치는지 측정
- 문장 길이에 대한 과적합 보정
- 같은 단어가 연속적으로 나올 때 과적합 보정
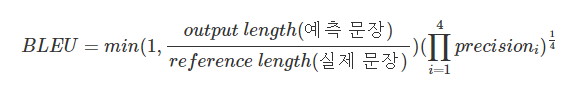
BLEU Score
BLEU BLEU(Bilingual Evaluation Understudy)score란 성과지표로 데이터의 X가 순서정보를 가진 단어들(문장)로 이루어져 있고, y 또한 단어들의 시리즈(문장)로 이루어진 경우에 사용되며, 번역을 하는 모델에
donghwa-kim.github.io
3) BLEU Score(Bilingual Evaluation Understudy Score)
앞서 언어 모델(Language Model)의 성능 측정을 위한 평가 방법으로 펄플렉서티(perplexity, PPL)를 소개한 바 있습니다. 기계 번역기에도 PPL을 평가 ...
wikidocs.net
참조 GLUE
GLUE: 벤치마크를 통해 BERT 이해하기 - Programador | Huffon Blog
본 글은 Chris McCormick과 Nick Ryan이 공동으로 작성한 GLUE Explained: Understanding BERT Through Benchmarks를 저자의 허락을 받아 한국어로 옮긴 글입니다. 잦은 의역이 있으니 원문을 살려서 읽고자 하신 분들
huffon.github.io
챗봇과 번역기
[번역] 챗봇을 위한 딥러닝 1. 개요
[번역] 챗봇을 위한 딥러닝 - 개요 본 포스팅은 번역글입니다. 의역이 많이 포함되어 있을 수 있습니다. 원문: Deep Learning For Chatbots, Part 1 - Introduction 대화형 에이전트 또는 다이얼로그 시스템이라
norux.me
- 만드는 방법에 따라 검색 기반 모델, 생성 모델이 있음
- Open Domain은 어떤 토픽이든 오고 갈 수 있는 대화, 다양한 주제를 주고 받음
- Closed Domain은 한정된 분야에 대해서만 대화를 주고 받으며, 주제를 벗어나면 답변 생성이 불가함
질문하는 언어를 Source언어, 답변하는 언어를 Target언어라고 한다면 번역하는 행위를 곧 질문하는 방법으로 바꿀 수 있음

Encoder는 Source 문장을 읽고 이해한 내용을 고차원 문맥 벡터로 압축하며, Decoder는 Encoder가 만든 문맥 벡터를 바탕으로 Target 문장을 생성함
챗봇 고려사항
200ms
대화가 자연스럽게 느껴지는 마지노선 시간으로 0.2초 이내 답변이 나와야 함
모델 외에도 사용되는 시간이 필요한 만큼 각 모듈마다 제한 시간이 더 짧음
시공간에 대한 질문
오늘이 무슨 요일인지에 대한 내용은 같은 질문이더라도 답변이 항상 달라져야하는 부분
페르소나
인격의 일관성(Coherent Personality)에 관한 내용으로 다양한 사람들의 데이터를 모아서 사용할 수 밖에 없기 때문에 모델의 인격이 일관성을 갖기가 어려움
챗봇UX 4편, 챗봇이 다른 서비스와 다른 점, 페르소나 | 단비Ai 도큐먼트
챗봇에게 페르소나를 부여하세요! Edit me --> Edit 사회적인 인터렉션을 통한 관계 형성 챗봇시대를 함께 열어가는 여러분, 안녕하세요! 챗봇과 같은 인간의 언어로 대화하는 대화형 인터페이스를
doc.danbee.ai
대화의 일관성
너무 뜬금 없는 대답을 막아 대화의 일관성을 유지하려는 시도가 있음
참조링크 https://arxiv.org/pdf/1606.01541.pdf
기존의 Source 질문 Target 답변 방식으로 매핑하는 훈련법은 정답을 맞히게만 학습하기 때문에 문제가 발생함
모든 질문에 대해 "무슨말인지 모르겠어요"가 존재하기 때문

저자들이 정의한 좋은 대화
- 상대방이 답변하기 좋으며
- 새로운 정보를 담고
- 일관성이 있는 말
을 보상으로 이를 최대화하는 방향으로 학습을 진행함
대화에서 [q1, a1, q2, a2, ...] 가 이어질 때 a2는 a1,q2를 보고 문장을 생성하는데 모르겠어요의 경우 모든 질문에 해당될 확률이 높은 문장이므로, a2를 보고 q2를 유추할 수 있는지를 보상으로 추가하여 일관성 있는 대화를 생성하는 방향으로 학습이 진행되게끔 만들었음
대표 챗봇
Meena
구글의 챗봇으로 GPT-2보다 2배가량 큰 모델이며, 9배 많은 데이터로 학습한 모델로 모델 구조는 Evolved Transformer를 사용했으며, 대화 평가 지표인 SSA를 제안함
무슨 대화든 할 수 있는 에이전트를 향하여
2020년 1월 28일(화) 구글 AI 리서치 블로그 | 최신 대화형 에이전트(챗봇)는 고도로 전문화된 경향이 있습니다. 사용자가 예상 사용량을 너무 많이 벗어나지 않는 한 성능이 우수합니다. 광범위한
brunch.co.kr
SSA는 Hi 대화로 시작하여 이후 챗봇이 생성한 발언에 대해 구체적인지 합리적인지 T/F로 평가함
Blender
Facebook의 모델이며, 모델에 페르소나를 부여하는 시도, 자체적인 평가 지표 ACUTE-Eval을 제안함
[논문리뷰] 블렌더(Blender) - Facebook AI의 오픈 도메인 챗봇
BLENDER > 페이스북 AI에서 발표한 오픈 도메인 챗봇 모델 > 대화에 적절히 개입하고, 지식과 강세, 페르소나를 나타내면서 멀티턴 대화에서 일관적인 성격을 유지하는 것에 초점 > 90M, 2.7B, 9.4B 개의
littlefoxdiary.tistory.com
ACUTE-Eval은 생성된 두 개의 긴 대화를 보고 어떤 대화가 더 사람 같은지와 어떤 챗봇과 대화하고 싶은지 양자택일 평가함
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| NLP Framework (0) | 2022.04.20 |
|---|---|
| BERT Pretrain with TPU (0) | 2022.04.19 |
| Attention to Transformers (0) | 2022.04.04 |
| Attention translator (0) | 2022.04.04 |
| Seq2seq과 Attention (0) | 2022.03.30 |