
언어모델
단어의 시퀀스를 보고 다음 단어에 확률을 할당하는 모델

통계적 언어 모델(Statistical Language Model)
2000년대 초반까지 구글이나 네이버의 번역기로 사용 되던 통계적 언어 모델
참조링크 https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/09/16/LM/
등장한 적 없는 단어나 문장에 대해선 모델링 할 수 없었던던 치명적인 단점
신경망 언어 모델(Neural Network Language Model)
통계적 언어 모델의 단점을 개선하여 나온 모델
참조링크 https://wikidocs.net/45609
임베딩 벡터를 사용하여 단어 유사도를 계산하고 희소 문제(sparsity problem)를 해결
희소문제는 한번도 관측하지 못한 데이터에 대해 0 확률을 부여하는 문제
예측에 정해진 개수의 단어만 참고한다는 단점 여전히 존재
Sequence to Sequence

단고정된 크기의 Weight를 Linear로 처리하는 방식은 유연성의 한계가 존재하였고, 단어 개수에 무관하게 처리할 수 있는 네트워크를 위해 RNN을 고안하게 됨
고정된 크기의 Weight가 선언되지만 입력을 순차적으로 누적하면서 유동적인 크기의 입력을 처리
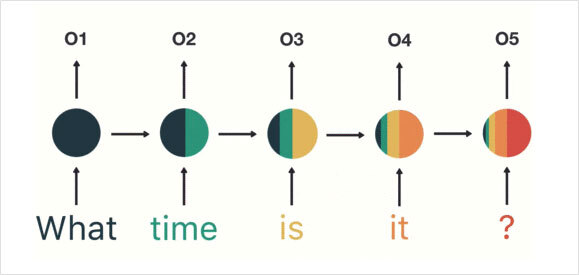
여전히 존재하는 문제점
1. 하나의 Weight에 입력을 누적하다보니 입력이 길어질 경우 이전 입력에 대한 정보가 소실되는 기울기 소실(Vanishing Gradient)문제로 초기의 남색 부분의 정보가 끝으로 갈수록 희석됨
이러한 문제는 Long Short-Term Memory가 등장하며 해결 참조링크 https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
2. 번역에 사용하기 어려운 문제점
한국어와 영어를 번역할 경우 어순에 따라 차이가 있고 번역의 길이도 같다는 보장이 없기 때문에 문장의 전체를 보고나서 생성하는 구조가 필요했고, 이에 따라 Seq2Seq 구조가 나오게 됨
참조링크 https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf
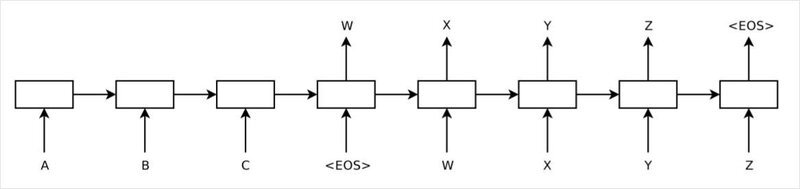
참조링크 https://reniew.github.io/35/
Seq2Seq 구현
import tensorflow as tf
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units):
super(Encoder, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.lstm = tf.keras.layers.LSTM(enc_units) # return_sequences 매개변수를 기본값 False로 전달
def call(self, x):
print("입력 Shape:", x.shape)
x = self.embedding(x)
print("Embedding Layer를 거친 Shape:", x.shape)
output = self.lstm(x)
print("LSTM Layer의 Output Shape:", output.shape)
return outputEncoder 클래스의 반환 값은 곧 컨텍스트 벡터가 됨
vocab_size = 30000
emb_size = 256
lstm_size = 512
batch_size = 1
sample_seq_len = 3
encoder = Encoder(vocab_size, emb_size, lstm_size)
sample_input = tf.zeros((batch_size, sample_seq_len))
sample_output = encoder(sample_input) # 컨텍스트 벡터로 사용할 인코더 LSTM의 최종 State값
#result
입력 Shape: (1, 3)
Embedding Layer를 거친 Shape: (1, 3, 256)
LSTM Layer의 Output Shape: (1, 512)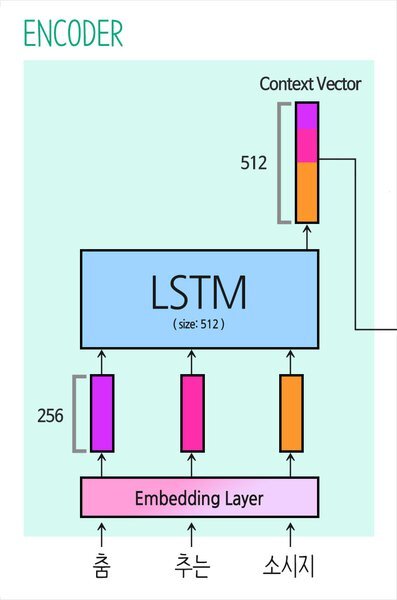
Encoder 클래스의 반환 값을 Decoder에게 전달
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, dec_units):
super(Decoder, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.lstm = tf.keras.layers.LSTM(dec_units, return_sequences=True)
self.fc = tf.keras.layers.Dense(vocab_size)
self.softmax = tf.keras.layers.Softmax(axis=-1)
def call(self, x, context_v): # 디코더의 입력 x와 인코더의 컨텍스트 벡터를 인자로 받는다.
print("입력 Shape:", x.shape)
x = self.embedding(x)
print("Embedding Layer를 거친 shape:", x.shape)
context_v = tf.repeat(tf.expand_dims(context_v, axis=1),
repeats=x.shape[1], axis=1)
x = tf.concat([x, context_v], axis=-1) # 컨텍스트 벡터를 concat
print("Context Vector가 더해진 shape:", x.shape)
x = self.lstm(x)
print("LSTM Layer의 Output Shape:", x.shape)
output = self.fc(x)
print("Decoder last output shape:", output.shape)
return self.softmax(output)print("Vocab Size: {0}".format(vocab_size))
print("Embedidng Size: {0}".format(emb_size))
print("LSTM Size: {0}".format(lstm_size))
print("Batch Size: {0}".format(batch_size))
print("Sample Sequence Length: {0}\n".format(sample_seq_len))
#result
Vocab Size: 30000
Embedidng Size: 256
LSTM Size: 512
Batch Size: 1
Sample Sequence Length: 3decoder = Decoder(vocab_size, emb_size, lstm_size)
sample_input = tf.zeros((batch_size, sample_seq_len))
dec_output = decoder(sample_input, sample_output) # Decoder.call(x, context_v) 을 호출
입력 Shape: (1, 3)
Embedding Layer를 거친 Shape: (1, 3, 256)
Context Vector가 더해진 Shape: (1, 3, 768)
LSTM Layer의 Output Shape: (1, 3, 512)
Decoder 최종 Output Shape: (1, 3, 30000)

Seq2Seq의 완성
Bahdanau Attention
Seq2Seq은 컨텍스트 벡터가 고정된 길이로 정보를 압축하면 손실을 야기한다고 말하며 Encoder 최종 State값만을 사용하는 기존 방식이 아닌, 매 스텝 Hidden State를 활용해 컨텍스트 벡터를 구축하는 Attention 매커니즘 제안
원본 참조 : https://arxiv.org/pdf/1409.0473.pdf
정리 글 : https://lovit.github.io/machine%20learning/2019/03/17/attention_in_nlp/
Attention을 활용하면 Attention Map의 시각화를 통해 안정성을 점검하고 의도와 다르게 작동할 경우 원인을 찾아낼 수 있음
seq2seq과 attn-seq2seq 다른점

유일한 차이는 c에 붙은 첨자 i의 차이

Bahdanau 논문 원문의 3. LEARNING TO ALIGN AND TRANSLATE 내용의 그림으로 Xj입력, Yi가 출력이 되는 인코더 디코더 부분의 도식, i는 디코더, j는 인코더 인덱스
나는 밥을 먹었다 -> I ate lunch로 번역할 경우, 두개의 어순이 다른데 이때 디코더가 현재 시점 i에서 인코더의 어느 부분 j가 중요한지 따질 때 사용하는 것이 attention
위 식에서는 aij가 그 가중치 역할을 수행함

참조링크 https://eda-ai-lab.tistory.com/157

스코어 함수의 구현
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W_decoder = tf.keras.layers.Dense(units)
self.W_encoder = tf.keras.layers.Dense(units)
self.W_encoder = tf.keras.layers.Dense(1)
def call(self, H_encoder, H_decoder):
print("[ H_encoder ] Shape:", H_encoder.shape)
H_encoder = self.W_encoder(H_encoder)
print("[ W_encoder X H_encoder ] Shape:", H_encoder.shape)
print("\n[ H_decoder ] Shape:", H_decoder.shape)
H_decoder = tf.expand_dims(H_decoder, 1)
H_decoder = self.W_decoder(H_decoder)
print("[ W_decoder X H_decoder ] Shape:", H_decoder.shape)
score = self.W_combine(tf.nn.tanh(H_decoder + H_encoder))
print("[ Score_alignment ] Shape:", score.shape)
attention_weights = tf.nn.softmax(Score, axis=1)
print("\n최종 Weight:\n", attention_weights.numpy())
context_vector = attention_weights * H_decoder
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
W_size = 100
print("Hidden State를 {0} 차원으로 Mapping\n".format(W_size))
attention = BahdanauAttention(W_size)
enc_state = tf.random.uniform((1, 10, 512))
dec_state = tf.random.uniform((1, 512))
_ = attention(enc_state, dec_state)
#result
Hidden State를 100차원으로 Mapping
[ H_encoder ] Shape: (1, 10, 512)
[ W_encoder X H_encoder ] Shape: (1, 10, 100)
[ H_decoder ] Shape: (1, 512)
[ W_decoder X H_decoder ] Shape: (1, 1, 100)
[ Score_alignment ] Shape: (1, 10, 1)
최종 Weight:
[[[0.05483533]
[0.07792971]
[0.09162702]
[0.05546886]
[0.1851147 ]
[0.12055066]
[0.07256519]
[0.13603026]
[0.07749002]
[0.12838824]]]Encoder의 모든 스텝의 Hidden State를 100차원 벡터 공간으로 매핑(1, 10, 100)하고 Decoder의 현재 스텝 Hidden State 또한 100차원 벡터 공간으로 매핑(1, 1, 100) 후, 두 State의 합으로 정의된 Score (1, 10, 1)를 구하는 코드
시각화

Luong Attention
정리글 https://hcnoh.github.io/2019-01-01-luong-attention
논문 원본 https://arxiv.org/pdf/1508.04025.pdf
주요 score 함수 : Dot, General, Concat, Location

General의 구현
class LuongAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(LuongAttention, self).__init__()
self.W_combine = tf.keras.layers.Dense(units)
def call(self, H_encoder, H_decoder):
print("[ H_encoder ] Shape:", H_encoder.shape)
WH = self.W_combine(H_encoder)
print("[ W_encoder X H_encoder ] Shape:", WH.shape)
H_decoder = tf.expand_dims(H_decoder, 1)
alignment = tf.matmul(WH, tf.transpose(H_decoder, [0, 2, 1]))
print("[ Score_alignment ] Shape:", alignment.shape)
attention_weights = tf.nn.softmax(alignment, axis=1)
print("\n최종 Weight:\n", attention_weights.numpy())
attention_weights = tf.squeeze(attention_weights, axis=-1)
context_vector = tf.matmul(attention_weights, H_encoder)
return context_vector, attention_weights
emb_dim = 512
attention = LuongAttention(emb_dim)
enc_state = tf.random_uniform((1, 10, emb_dim))
dec_state = tf.random.uniform((1, emb_dim))
_ = attention(enc_state, dec_state)
GNMT(Google`s Neural Machine Translation System)
8개 층을 쌓은 Encoder-Decoder와 Residual Connection이 특징
Bahdanau Attention 차용
트랜스포머가 나오기 직전 모델
참조링크 https://norman3.github.io/papers/docs/google_neural_machine_translation.html
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| Attention to Transformers (0) | 2022.04.04 |
|---|---|
| Attention translator (0) | 2022.04.04 |
| 워드 임베딩 (0) | 2022.03.24 |
| 로이터 뉴스 분류 (0) | 2022.03.23 |
| 텍스트의 벡터화 (0) | 2022.03.21 |