
벡터화
Bag of words / DTM(Document-Term Matrix)
Bag of words를 사용하여 문서 간 유사도를 비교한 행렬을 만들면 이를 DTM(문서 단어 행렬)이라고 함
예시문장)
- 문서1 : you know I want your love
- 문서2 : I like you
- 문서3 : what should I do
불필요 단어 제거하거나 표현은 다르나 같은 뜻의 단어를 통합하는 전처리를 진행함
이는 단어 카운트에 기반한 방법론이기 때문

DTM의 행은 문서, 열은 단어를 표시하는 벡터가 되며, 이때 대부분의 값이 0이 되는 특징이 있는데 이를 희소 벡터(sparse vector)라고 함. 문서나 단어수가 많아질수록 0값이 많아지게 됨
또한 위 행렬에서는 단어 갯수에 대한 카운트가 없이 중복이 없게 만들어졌으며 이를 단어장(vocabulary)로 표현
TF-IDF
단어마다 주요 가중치르 다르게 주는 방법
DTM과 차이는 있지만 문서 벡터 크기가 단어장의 크기인 V, 문서와 단어벡터 둘다 여전히 희소 벡터로 존재
원-핫 인코딩(one-hot encoding)
모든 단어의 관계를 독립적으로 정의하는 방법
예시 단어)
- 문서 1 : 강아지, 고양이, 강아지
- 문서 2 : 애교, 고양이
- 문서 3 : 컴퓨터, 노트북
예시 vocabulary)
- 강아지 : 1번
- 고양이 : 2번
- 컴퓨터 : 3번
- 애교 : 4번
- 노트북 : 5번
예시 one-hot-encoding
- 강아지 : [1, 0, 0, 0, 0]
- 고양이 : [0, 1, 0, 0, 0]
- 애교 : [0, 0, 1, 0, 0]
- 컴퓨터 : [0, 0, 0, 1, 0]
- 노트북 : [0, 0, 0, 0, 1]
원-핫 인코딩 구현
전처리
한글과 공백을 제외하고 문자를 제거할 땐 정규표현식을 사용
자음의 범위 ㄱ~ㅎ
모음의 범위 ㅏ ~ ㅣ
글자의 범위 가~힣
import re
from konlpy.tag import Okt
from collections import Counter
text = "임금님 귀는 당나귀 귀! 임금님 귀는 당나귀 귀! 실컷~ 소리치고 나니 속이 확 뚫려 살 것 같았어."
reg = re.compile("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]")
text = reg.sub('', text)
print(text)
#result
임금님 귀는 당나귀 귀 임금님 귀는 당나귀 귀 실컷 소리치고 나니 속이 확 뚫려 살 것 같았어
토큰화
단어장을 구성하기 위한 원소, 토큰을 정하는 과정
okt=Okt()
tokens = okt.morphs(text)
print(tokens)
#result
['임금님', '귀', '는', '당나귀', '귀', '임금님', '귀', '는', '당나귀', '귀', '실컷', '소리', '치고', '나니', '속이', '확', '뚫려', '살', '것', '같았어']
단어장 만들기
파이썬의 Counter 활용
# return {키 : 빈도수}
vocab = Counter(tokens)
print(vocab)
Counter({'귀': 4, '임금님': 2, '는': 2, '당나귀': 2, '실컷': 1, '소리': 1, '치고': 1, '나니': 1, '속이': 1, '확': 1, '뚫려': 1, '살': 1, '것': 1, '같았어': 1})
vocab['임금님']
#result
2
# 빈도 수 기준 word vocab
vocab_size = 5
vocab = vocab.most_common(vocab_size)
print(vocab)
[('귀', 4), ('임금님', 2), ('는', 2), ('당나귀', 2), ('실컷', 1)]
# word to index
word_index = {word[0] : index+1 for index, word in enumerate(vocab)}
print(word_index)
#result
{'귀': 1, '임금님': 2, '는': 3, '당나귀': 4, '실컷': 5}
원-핫 벡터 만들기
수작업
def one_hot_encoding(word, word2index):
one_hot_vector = [0]*(len(word2index))
index = word2index[word]
one_hot_vector[index-1] = 1
return one_hot_vector
one_hot_encoding("임금님", word2idx)
#result
[0, 1, 0, 0, 0]케라스
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
text = [['강아지', '고양이', '강아지'],['애교', '고양이'], ['컴퓨터', '노트북']]
tokenizer = Tokenizer()
tokenizer.fit_on_texts(text)
print(tokenizer.word_index) # 각 단어에 대한 인코딩 결과 출력.
#result
{'강아지': 1, '고양이': 2, '애교': 3, '컴퓨터': 4, '노트북': 5}
# +1 for special token
vocab_size = len(tokenizer.word_index) + 1
sub_text = ['강아지', '고양이', '강아지', '컴퓨터']
encoded = t.texts_to_sequences([sub_text])
print(encoded)
#result
[[1, 2, 1, 4]]
one_hot = to_categorical(encoded, num_classes = vocab_size)
print(one_hot)
[[[0. 1. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0.]]]
워드 임베딩
문제점 - 1 희소벡터
단어장 크기가 3만이라면 1개의 값을 제외한 29,999개의 원소가 0값
문제점 - 2 차원의저주

차원이 커지면서 정보의 밀도가 작아짐
참고자료 http://thesciencelife.com/archives/1001
문제점 3 - 벡터간 유사도
원-핫 벡터는 유사도를 반영할 수 없음

단어 벡터간 유사도를 구할 수 없으면 처음 보는 문장에 유연하게 대처할 수 없음
이를 계기로 나오게 된 워드 임베딩, 임베딩 벡터
워드 임베딩
단어를 벡터로 바꿀 때 벡터의 길이를 정한 상태에서 벡터화하므로 일반적으로 벡터의 길이가 단어장 크기보다 작기 때문에 밀집 벡터(Dense vector) 가 형성 됨
0이나 1 위주의 희소벡터와는 다르게 대부분 0값이 아니며, 다양한 숫자값을 가지고 있음

비슷한 의미를 가진 두 단어의 내적이 클수록 잘 변환된 벡터로 판단할 수 있음
인공신경망 활용 시 단어 적합성이나 유사도를 계싼하며 벡터의 값을 바꿔나감
핵심은
- 단어를 길이가 짧은 밀집 벡터로 표현
- 이 밀집 벡터는 단어가 갖는 의미나 단어 간의 관계 의미를 내포하고 있음
- 훈련 데이터로부터 모델을 학습하는 과정에서 얻어짐
워드 임베딩 모델은 최초에 나왔을 때 학습 속도가 지나치게 느리다는 단점이 있었으나 구글이 이 방법을 개선한 Word2Vec을 제안함. 이 이후로 FastText나 Glove등의 임베딩 방법이 추가로 제안됨
Word2Vec 분포가설
분포가설
Word2Vec의 핵심아이디어로 비슷한 문맥에서 같이 등장하는 경향이 있는 단어들은 비슷한 의미를 가지게 됨
CBoW 와 Skip-gram
CBoW(Continuous Bag of words)
CBoW는 중간에 있는 단어를 예측하는 방법으로
예시문장) I like natural language processing이 있을 때 다른 단어들로부터 natural을 예측하는 것
이 때 natural을 중심단어(center word), 예측에 사용되는 단어를 주변 단어(context word)로 표현
중심 단어 예측을 위해 앞 뒤로 몇개 단어를 볼지 결정하는 범위를 윈도우(window)라고 함
윈도우가 1이고, 중심단어가 language라면 natural 과 processing을 참고함

윈도우 크기를 정하면 윈도우를 움직여서 주변단어와 중심단어를 바꿔가며 데이터셋을 만들 수 있음
위 그림은 윈도우 크기가 1개 일 때 샘플 문장에 대해 데이터셋 만드는 과정
- ((like), I), ((I, natural), like), ((like, language), natural), ((natural, processing), language), ((language), processing)

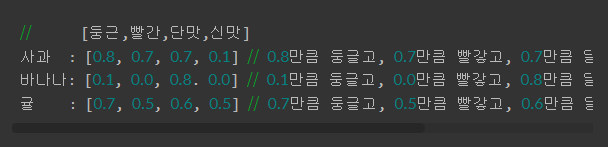
원-핫 벡터로 변환된 다수 주변단어를 활용해 원-핫 벡터로 변환된 중심 단어를 예측할 때의 CBoW 메커니즘
윈도우 크기가 m 일때 2m개의 주변 단어를 이용해 1개의 중심 단어를 예측하는 과정에서 두개의 가중치 행렬을 학습
얕은 신경망(shallow Neural Network)으로서의 학습
은닉층의 크기가 N 일 때

원핫벡터와 가중치 행렬의 곱은 가중치 행렬의 i 위치에 있는 행을 그대로 가져오는 것과 동일

룩업 테이블을 거쳐 생긴 2m개의 주변 단어 벡터들은 각 N의 크기를 가지며 CBoW는 이 벡터를 모두 합하거나 평균을 구한 값을 최종 은닉층의 결과로 함, Word2Vec에선 은닉층에서 활성화 함수는 편향을 더하는 연산은 하지 않음
단순히 가중치 행렬과 곱셉만을 수행하기 때문에 기존 신경망 은닉층과 구분지어 투사층(projection layer)라고 하기도 함
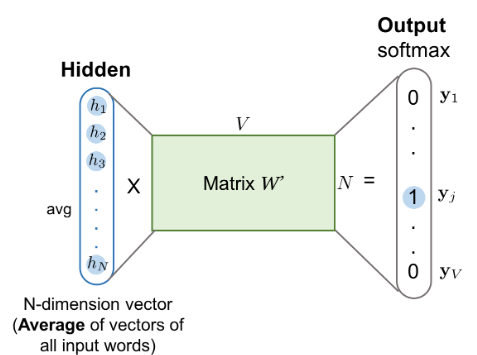
은닉층에서 생성된 N 차원 벡터는 두번째 가중치 행렬과 곱하게 됨 (N x V) 곱셈 결과 벡터 차원은 V, 출력층은 활성화 함수로 소프트 맥스 함수를 사용하므로 V차원 벡터는 활성화 함수를 거쳐 차원의 총합이 1이 되는 벡터로 변경
CBoW는 이 출력층 벡터를 중심 단어의 원-핫 벡터와의 손실(loss)를 최소화 하도록 학습함
학습 이후 어느 가중치 행렬을 임베딩 벡터로 사용할지 결정하며 때로는 첫 가중치 행렬과 두번째 가중치 행렬의 평균치를 임베딩 벡터로 선택하기도 함
Skip-gram, Negative Sampling
skip-gram
중심 단어로부터 주변 단어를 예측하는 것(CBoW와 반대)

skip-gram 기준의 데이터셋
- 아래 데이터셋의 형식은 (중심 단어, 주변 단어)임을 가정합니다.
- (i, like) (like, I), (like, natural), (natural, like), (natural, language), (language, natural), (language, processing), (processing, language)

중심단어로부터 주변단어를 예측하는 것, 이로 인해 은닉층에서 다수의 벡터의 덧셈과 평균을을 구하는 과정이 없어진 점을 제외하면 CBoW와 매커니즘은 비슷하며 학습 후 가중치 행렬로부터 임베딩 벡터를 얻을 수 있음
네거티브 샘플링(negative sampling)
Word2Vec을 사용할 땐 대체로 SGNS(Skip-Gram with Negative Sampling)을 사용함
Skip-gram은 출력층에서 소프트 맥스 함수를 통과한 V 차원 벡터와 레이블에 해당하는 V 차원의 주변 단어의 원-핫 벡터와의 오차를 구하고, 역전파를 통해 모든 단어에 대한 임베딩 벡터를 조정함
단어장 크기가 클수록 작업이 느리며 output을 위한 소프트 맥스 함수 분모항이 수백만에 달하게 됨
이 과정에서 관계 없는 단어들의 임베딩 값을 굳이 업데이트 할 필요가 없으므로 기존 다중 클래스 분류 문제를 시그모이드 함수를 사용한 이진 분류 문제로 바꾸게 됨
skip-gram
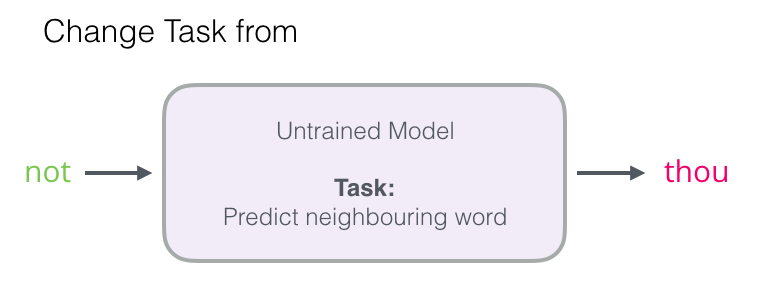
negative-sampling

중심 단어와 주변 단어를 입력값으로 받아 두 단어가 이웃인지 여부를 이진 분류로 변환
- 예문 : Thou shalt not make a machine in the likeness of a human mind
윈도우 크기가 2일 때 슬라이딩 윈도우를 통해 만들어지는 skip-gram

주변단어 인 경우, 아닌 경우에 대한 라벨링



Word2Vec 실습
import nltk
nltk.download('abc')
nltk.download('punkt')
from nltk.corpus import abc
corpus = abc.sents()
print(corpus[:3])
#result
[['PM', 'denies', 'knowledge', 'of', 'AWB', 'kickbacks', 'The', 'Prime', 'Minister', 'has', 'denied', 'he', 'knew', 'AWB', 'was', 'paying', 'kickbacks', 'to', 'Iraq', 'despite', 'writing', 'to', 'the', 'wheat', 'exporter', 'asking', 'to', 'be', 'kept', 'fully', 'informed', 'on', 'Iraq', 'wheat', 'sales', '.'], ['Letters', 'from', 'John', 'Howard', 'and', 'Deputy', 'Prime', 'Minister', 'Mark', 'Vaile', 'to', 'AWB', 'have', 'been', 'released', 'by', 'the', 'Cole', 'inquiry', 'into', 'the', 'oil', 'for', 'food', 'program', '.'], ['In', 'one', 'of', 'the', 'letters', 'Mr', 'Howard', 'asks', 'AWB', 'managing', 'director', 'Andrew', 'Lindberg', 'to', 'remain', 'in', 'close', 'contact', 'with', 'the', 'Government', 'on', 'Iraq', 'wheat', 'sales', '.']]
print('코퍼스의 크기 :',len(corpus))
#result
코퍼스의 크기 : 29059
from gensim.models import Word2Vec
#vector size = 학습 후 임베딩 벡터 차원
#window = 컨텍스트 윈도우 크기
#min_count = 단어 최소 빈도수 제한(빈도 적은 단어 학습 X)
#workers = 학습을 위한 프로세스 수
#sg = 0은 CBoW, 1은 Skip-gram
model = Word2Vec(sentences = corpus, vector_size = 100, window = 5, min_count = 5, workers = 4, sg = 0)man과 유사한 단어
model_result = model.wv.most_similar("man")
print(model_result)모델의 저장과 로드
from gensim.models import KeyedVectors
model.wv.save_word2vec_format('~/aiffel/word_embedding/w2v')
loaded_model = KeyedVectors.load_word2vec_format("~/aiffel/word_embedding/w2v")
model_result = loaded_model.most_similar("man")
print(model_result)
[('woman', 0.9233373999595642), ('skull', 0.911032497882843), ('Bang', 0.9056490063667297), ('asteroid', 0.9051957130432129), ('third', 0.9020178318023682), ('baby', 0.8993921279907227), ('dog', 0.8985978364944458), ('bought', 0.8975234031677246), ('rally', 0.8912491798400879), ('disc', 0.8888981342315674)]
Word2Vec의 OOV 문제
# 에러 발생
loaded_model.most_similar('overacting')
#result
KeyError: "Key 'overacting' not present"loaded_model.most_similar('memorry')
#result
KeyError: "Key 'memorry' not present"
임베딩 벡터 시각화
저장된 모델 로드하기
Gensim: topic modelling for humans
Efficient topic modelling in Python
radimrehurek.com
Embedding projector - visualization of high-dimensional data
Visualize high dimensional data.
projector.tensorflow.org

좌측 Load 버튼을 누르면
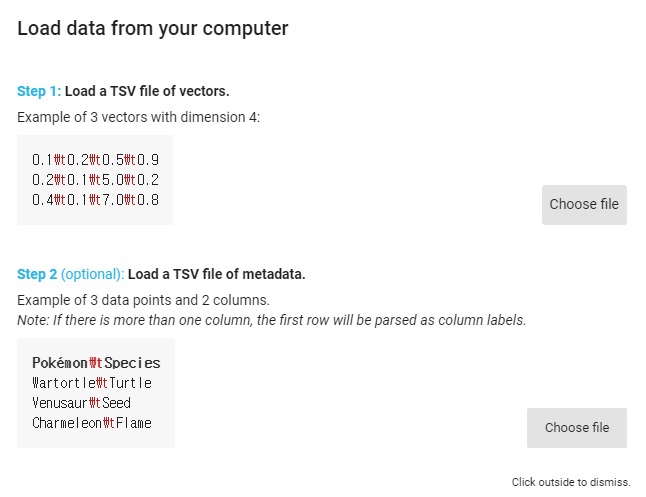
step1에 벡터값이 저장된 tsv파일 업로드, step2에는 메타 데이터 tsv 파일을 업로드
1에 w2v_tensor.tsv, 2에 w2v_metadata.tsv 파일 업로드

우측의 Search 버튼 또는 그래프 포인트를 클릭하는 등 측정 매트릭을 다양하게 선택해서 임베딩 벡터 군집을 확인할 수 있음
FastText
Word2Vec 이후 등장한 워드 임베딩으로 매커니즘은 Word2Vec을 따르고 있지만 문자 단위 n-gram(character-level n-gram) 표현을 학습한다는 점이 다름
Word2Vec은 단어를 더 이상 분리할 수 없는 단위로 구분하며
FastText는 단어 내부의 내부 단어(subwords)들을 학습하는 아이디어
FastText의 n-gram에서 n은 단어들이 얼마나 분리되는지 결정하는 하이퍼파라미터로 n을 3으로 잡은 트라이그램의 경우, 단어 partial을 par,art,rti,tia,ial로 분리하고 벡터로 변환함

실제 사용시 n의 최솟값 최대값 범위를 정할 수 있는데 gensim 패키지는 기본값이 3, 6으로 설정되어 있음

단어들 각각에 대해 Word2Vec을 수행하여 벡터화 후, 총합을 해당 단어의 벡터로 취합

FastText의 학습 방법
네거티브 샘플링을 사용하여 학습하며, Word2Vec과 다른점은 학습과정에서 중심 단어에 속한 문자 단위 n-gram 단어 벡터를 모두 업데이트 하는 것
OOV와 오타 대응
FastText는 Word2Vec과 달리 OOV와 오타에 대해 Robust한 특징이 있음
from gensim.models import FastText
fasttext_model = FastText(corpus, window=5, min_count=5, workers=4, sg=1)
fasttext_model.wv.most_similar('overacting')
#result
[('extracting', 0.9400394558906555),
('overwhelming', 0.9384993314743042),
('mounting', 0.9356904029846191),
('emptying', 0.9348322153091431),
('fluctuating', 0.934314489364624),
('malting', 0.9340718984603882),
('declining', 0.9333873987197876),
('lifting', 0.9308417439460754),
('shooting', 0.9302120208740234),
('resolving', 0.9290695786476135)]단어장에 단어가 없어도 임베딩 벡터값을 계산하여 유사 단어 10개를 출력
[('memory', 0.9473720192909241),
('mechanisms', 0.8755784630775452),
('mechanism', 0.8716992139816284),
('basic', 0.8588584661483765),
('musical', 0.8570638298988342),
('technical', 0.8537068963050842),
('mechanical', 0.8496874570846558),
('intelligence', 0.8436625599861145),
('technological', 0.8417373895645142),
('mess', 0.8400978446006775)]
한국어 FastText
한국어에선 다른 특징의 n-gram
음절 단위 FastText
n=3일 때
- <텐서, 텐서플, 서플로, 플로우, 로우>, <텐서플로우>
한국어에서 FastText가 자소를 각 문자로 간주한 경우 잘 동작하는 것으로 알려짐
자소 단위 FastText
n=3일 때 텐서플로우 문자
<ㅌㅔ,ㅌㅔㄴ,ㅔㄴㅅ,ㄴㅅㅓ,ㅅㅓ_, ...중략... >
참조링크 https://brunch.co.kr/@learning/8
성능이 좋지만 프랑스 같은 고유명사의 경우 어휘를 분해하더라도 도움이 되지 않거나 성능 저하를 일으키기도 함
GloVe
글로브(Global Vectors for Word Representation, GloVe)는 스탠포드 대학에서 개발한 워드 임베딩 방법론으로
카운트 기반과 예측 기반 두가지 방법을 모두 사용함
카운트 기반은 단어 빈도를 수치화한 방법 DTM에 대해 차원 축소 후 밀집 표현으로 임베딩 하는 방법(LSA)
잠재 의미 분석(LSA, Latent Semantic Analysis)
참조링크 https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/04/06/pcasvdlsa/
행렬 A에 대해 특이값 분해를 했을 때 다시 복원할 수 있는 특이값 분해는 this SVD, compact SVD
LSA는 DTM에 특잇값 분해를 사용해서 잠재된 의미를 이끌어내는 방법론
LSA에 대조되는 방법으로 예측 기반 방법인 Word2Vec
GloVe 연구진은 LSA의 통계 기반 정보와 Word2Vec의 벡터간 유사도 구하는 능력을 모두 활용하여 임베딩 하는 방법을 제시했는데 그게 GloVe지만 성능이 완전히 뛰어나다고 평가되지는 않음
윈도우 기반 동시 등장 행렬(Window based Co-occurrence Matrix)
3개의 예시 문장)
- I like deep learning.
- I like NLP.
- I enjoy flying.
동시 등장 행렬(co--occurence Matrix)

열은 전체 단어장의 단어로 구성하고 i 단어의 window size 내에서 k 단어가 등장한 횟수를 i행 k열에 기재한 행렬
transpose해도 동일한 행렬이 된다는 특징
동시 등장 확률(Co-occurrence Probability)
동시 등장 확률 P(k|i)는 동시 등장 행렬에서 특정 단어 i의 전체 횟수를 카운트 하고 i가 등장했을 때 k 단어가 등장한 횟수를 카운트하여 계산한 조건부 확률임. i는 중심 단어(center word), k는 주변단어(context word)

위 표를 통해서 ice가 등장 했을 때 solid가 등장할 확률은 large이나, steam 이후 solid가 등장할 확률은 small

GloVe의 손실 함수 설계
동시 등장 확률을 이용해 손실함수를 설계함. 코퍼스 전체 통계 정보를 활용하는 카운트 기반 방법론을 사용하며 손실 함수를 통해 모델을 학습시키는 예측 기반의 방법론을 사용
전체 코퍼스에서 동시 등장 빈도의 로그값과 중심 단어 벡터와 주변 단어 벡터의 내적값의 차이가 최소화되도록 두 벡터의 값을 학습하는 것

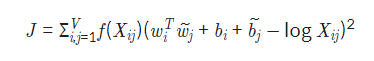
우측항을 보면 중심 단어와 주변 단어 벡터의 내적이 동시 등장 빈도의 로그값과 차이를 줄이도록 설계되었음
동시 등장 행렬에서 동시 등장 빈도 값 F(Xik)은 낮은 경우 도움이 되지 않는 정보로 판단하여 가중치 함수를 도입함

F(Xik) 값이 작으면 함수 값이 작아지고, 값이 클수록 커지지만 지나치게 커지지 않도록 최댓값이 1로 정해짐
It is 같은 불용어 동시 등장 빈도수가 높을 때 지나친 가중치를 주지 않기 위함
pre-trained GloVe 모델 실습
GloVe는 15년도 1.2버전 이후 관리되지 않고 있음
pretrained model로 사용 가능
- Common Crawl (42B tokens, 1.9M vocab, uncased, 300d vectors, 1.75 GB download)
- Common Crawl (840B tokens, 2.2M vocab, cased, 300d vectors, 2.03 GB download)
- Wikipedia 2014 + Gigaword 5 (6B tokens, 400K vocab, uncased, 300d vectors, 822 MB download)
- Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased, 200d vectors, 1.42 GB download)
import gensim.downloader as api
glove_model = api.load("glove-wiki-gigaword-50") # glove vectors 다운로드
glove_model.most_similar("dog") # 'dog'과 비슷한 단어 찾기
#result
[('cat', 0.9218004941940308),
('dogs', 0.8513158559799194),
('horse', 0.7907583713531494),
('puppy', 0.7754920721054077),
('pet', 0.7724708318710327),
('rabbit', 0.7720814347267151),
('pig', 0.7490062117576599),
('snake', 0.7399188876152039),
('baby', 0.7395570278167725),
('bite', 0.7387937307357788)]
glove_model.most_similar('overacting')
#result
[('impudence', 0.7842012047767639),
('puerile', 0.7816032767295837),
('winningly', 0.7644237875938416),
('grossness', 0.7576098442077637),
('deconstructions', 0.748936653137207),
('over-the-top', 0.7460805773735046),
('buffoonery', 0.746045708656311),
('impetuosity', 0.7415392398834229),
('sophomoric', 0.736961841583252),
('zaniness', 0.7353197336196899)]OOV 에러
glove_model.most_similar('memoryy')
#result
KeyError: "Key 'memoryy' not present"
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| Attention translator (0) | 2022.04.04 |
|---|---|
| Seq2seq과 Attention (0) | 2022.03.30 |
| 로이터 뉴스 분류 (0) | 2022.03.23 |
| 텍스트의 벡터화 (0) | 2022.03.21 |
| -45일차- 감성분류 with sentencepiece (0) | 2022.03.16 |