
Transformers의 전, 후
Seq2Seq의 LSTM을 사용한 Encoder-Decoder 구조

RNN은 긴 입력에 대한 정보를 학습시키기 어렵기 때문에 Seq2Seq에서는 LSTM을 사용한 Encoder-Decoder를 사용. 논문에서는 Encoder에 Input Sequence x를 넣으면 고정된 크기의 Representation Vector v에 모든 정보를 담아 Decoder에게 전달하는 구조. Decoder는 전달 받은 v를 기반으로 Output Sequence y를 생성함 v는 context vector라고도 불림
고정된 크기의 컨텍스트 벡터를 사용하는 것, 특히 문장이 길어지면 손실이 커지게 됨. 컨텍스트 벡터가 모든 임베딩의 평균일 때 3단어를 포함하는 문장과, 100단어를 포함하는 문장에서는 100단어를 포함하는 문장의 손실이 일어남
번역하는데 중요한 단어만 큰 비중을 줘서 성능을 높이는 Bahdanau Attention 방식이 나오게 됨
Attn: Illustrated Attention
원문 아티클 : Attn: Illustrated Attention Attn: Illustrated Attention GIFs를 활용한 기계번역(ex. 구글번역기)에서의 Attention 신경망을 활용한 기계 번역모델(NMT)이 나오기 전 수십 년 동안, 통계기반 기..
eda-ai-lab.tistory.com
매 스텝마다 Hidden State 값을 사용하는 효과

대각선이 역행하는 European Economic Area 부분과 zone enonomique europeenne과 의미적으로 유사하게 나옴
단, 단점으로 Decoder의 Hidden State를 구하기 위해 T-1 스텝의 Hidden State를 사용했어야 했고 RNN에 역행하는 연산이로 효율적이지 못함
Luong Attention
[Attention] Luong Attention 개념 정리
지난번에 Bahdanau Attention에 대한 포스팅을 작성하였으며 그 후속으로 이번에는 Luong Attention에 대한 내용을 정리하게 되었다. Bahdanau Attention에 대한 포스팅은 다음의 링크를 통해서 확인할 수 있다
hcnoh.github.io
달라진 점
- 디코더의 Hidden State Vector를 구하는 방식이 Attention Mechanism의 Computation Path가 간소화 됨
- Local Attention과 Alignment Model을 제시
- 다양한 score Funtion 제시와 비교
Attention Is All You Need
RNN과 CNN을 완전 배제하고 Attention 매커니즘에만 기반을 둔 구조
RNN은 기울기 소실이나, 특성상 병렬 처리가 불가능한 것이 문제점이었음
https://arxiv.org/pdf/1706.03762.pdf Attention is all you need 논문

Positional Encoding

Positional Encoding을 통해 문장에 연속성을 부여하는 방법을 새롭게 정의하게 됨
positional encoding이란 무엇인가
Transformer model을 살펴보면, positional encoding이 적용된다. 다음 그림은 transformer 모델에 대한 구조도 인데, positional encoding을 찾아볼 수 있다. 출처는 https://www.tensorflow.org/tutorials/text/..
skyjwoo.tistory.com
저자들이 사용한 Positional Encoding 수식

i = Encoding 차원의 Index,
D model은 모델의 임베딩 차원 수 -> Sinusoid(사인파) Embedding
import numpy as np
def positional_encoding(pos, d_model):
def cal_angle(position, i):
return position / np.power(10000, int(i) / d_model)
def get_posi_angle_vec(position):
return [cal_angle(position, i) for i in range(d_model)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(pos)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2])
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2])
return sinusoid_table
pos = 7
d_model = 4
i = 0
print("Positional Encoding 값:\n", positional_encoding(pos, d_model))
print("")
print("if pos == 0, i == 0: ", np.sin(0 / np.power(10000, 2 * i / d_model)))
print("if pos == 1, i == 0: ", np.sin(1 / np.power(10000, 2 * i / d_model)))
print("if pos == 2, i == 0: ", np.sin(2 / np.power(10000, 2 * i / d_model)))
print("if pos == 3, i == 0: ", np.sin(3 / np.power(10000, 2 * i / d_model)))
print("")
print("if pos == 0, i == 1: ", np.cos(0 / np.power(10000, 2 * i + 1 / d_model)))
print("if pos == 1, i == 1: ", np.cos(1 / np.power(10000, 2 * i + 1 / d_model)))
print("if pos == 2, i == 1: ", np.cos(2 / np.power(10000, 2 * i + 1 / d_model)))
print("if pos == 3, i == 1: ", np.cos(3 / np.power(10000, 2 * i + 1 / d_model)))
#result
Positional Encoding 값:
[[ 0. 1. 0. 1. ]
[ 0.84147098 0.99500417 0.00999983 0.9999995 ]
[ 0.90929743 0.98006658 0.01999867 0.999998 ]
[ 0.14112001 0.95533649 0.0299955 0.9999955 ]
[-0.7568025 0.92106099 0.03998933 0.999992 ]
[-0.95892427 0.87758256 0.04997917 0.9999875 ]
[-0.2794155 0.82533561 0.05996401 0.999982 ]]
if pos == 0, i == 0: 0.0
if pos == 1, i == 0: 0.8414709848078965
if pos == 2, i == 0: 0.9092974268256817
if pos == 3, i == 0: 0.1411200080598672
if pos == 0, i == 1: 1.0
if pos == 1, i == 1: 0.9950041652780258
if pos == 2, i == 1: 0.9800665778412416
if pos == 3, i == 1: 0.955336489125606Position 값이 Time-step별로 고유한 것을 볼 수 있는 시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(7, 7))
plt.imshow(positional_encoding(100, 300), cmap='Blues')
plt.show()
세로축이 Time-step, 가로축은 Word Embedding에 더해질 Position 값
저자들이 제안한 또다른 임베딩, Positional Embedding

Multi-Head Attention
Positional Embedding이 된 문장으로부터 Attention을 추출하는 부분

보라색의 구조는 Multi-Head Attention과 동일하지만 인과 관계 마스킹이라는 과정이 더 추가됩니다

Multi-Head Attention 모듈은 Linear 레이어와 Scaled Dot-Product Attention 레이어로 이루어짐
Scaled Dot-Product Attention

Transformers에서 중요한 Query, Key, Value의 의미는 현재까지도 계속 연구가 되고 있는 부분

오른쪽 그림은 전통적인 Attention으로 seq2seq 인코더-디코더 구조에서 attention이란 디코더의 포지션 i에서 바라본 인코더의 context vector ci를 해석하기위해 인코더의 각 포지션 j에 부여한 가중치 였고, 이 가중치는 디코더의 state si와 인코더의 state hj 사이의 유사도를 통해 계산되었음
디코더의 state를 Q(query), 인코더의 state를 K(key)로 추상화 되었으며 이 2개의 유사도의 dot product를 계산하여

위 식으로 attention 가중치를 삼고, 이것으로 V(value)를 재해석한 것(확률 값으로 계산)
Transformer: Attention is all you need
An Ed edition
reniew.github.io

위의 식으로 Attention 값을 나눠 주기 때문에 Scaled Dot-Product Attention으로 불리는데 이 Scale 과정은 Embedding 차원 수가 깊을수록 Dot-Product값은 커지게 되어 Softmax를 거친 후 미분 값이 작아지게 되므로, Scale 작업이 필요함
즉, Scaled Dot-Product Attention은 Additive(합 연산 기반) Attention과 Dot-Product(=Multiplicative, 곱 연산 기반) attention 중 후자를 사용한 Attention이고 차원 수가 깊어질수록 Softmax 값이 작아지는 것을 방지하기 위해 Scale 과정을 포함 한 것
import tensorflow as tf
import matplotlib.pyplot as plt
def make_dot_product_tensor(shape):
A = tf.random.uniform(shape, minval=-3, maxval=3)
B = tf.transpose(tf.random.uniform(shape, minval=-3, maxval=3), [1, 0])
return tf.tensordot(A, B, axes=1)
length = 30
big_dim = 1024.
small_dim = 10.
big_tensor = make_dot_product_tensor((length, int(big_dim)))
scaled_big_tensor = big_tensor / tf.sqrt(big_dim)
small_tensor = make_dot_product_tensor((length, int(small_dim)))
scaled_small_tensor = small_tensor / tf.sqrt(small_dim)
fig = plt.figure(figsize=(13, 6))
ax1 = fig.add_subplot(141)
ax2 = fig.add_subplot(142)
ax3 = fig.add_subplot(143)
ax4 = fig.add_subplot(144)
ax1.set_title('1) Big Tensor')
ax2.set_title('2) Big Tensor(Scaled)')
ax3.set_title('3) Small Tensor')
ax4.set_title('4) Small Tensor(Scaled)')
ax1.imshow(tf.nn.softmax(big_tensor, axis=-1).numpy(), cmap='cividis')
ax2.imshow(tf.nn.softmax(scaled_big_tensor, axis=-1).numpy(), cmap='cividis')
ax3.imshow(tf.nn.softmax(small_tensor, axis=-1).numpy(), cmap='cividis')
ax4.imshow(tf.nn.softmax(scaled_small_tensor, axis=-1).numpy(), cmap='cividis')
plt.show()
어두운 부분은 미분 값이 작기 때문에 넓은 특성을 반영할 수 없으며, 히트맵이 선명할수록 모델의 시야가 편협하게 됨
Embedding의 깊이가 깊을수록 모델 시야가 편협해지며, 2, 4번의 경우 어떤 경우에도 적용이 가능함
인과 관계 마스킹(Casuality Masking)
Seq2Seq 모델에서 Decoder는 컨테스트 벡터로 압축된 입력과 <start> 토큰만으로 첫 단어를 생성하며, 본인의 생성 단어를 포함해 두번째 단어를 생성하는 등 자기 회귀(Autoregressive)라 부름
그러나 트랜스포머는 병렬적으로 처리하기 때문에 자기 회귀 특성이 없음
이에 인과 관계 마스킹으로 목표 문장의 일부를 가려 인위적인 연속성을 학습하게 함

이러한 특성을 활용해 자기 회귀적인 문장 생성이 가능하게 됨
인과관계 마스크는 대학항을 포함하지 않는 삼각 행렬의 모양새를 갖게 되는데, 이는 Attention 값을 구하는 과정에서 마지막(첫번쨰)행이 0개 요소에 Softmax를 취하게 되므로 오류가 생길 수 있음
(대각항이란, 행렬에서 행과 열의 지표수가 같은 성분)
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
def make_dot_product_tensor(shape):
A = tf.random.uniform(shape, minval=-3, maxval=3)
B = tf.transpose(tf.random.uniform(shape, minval=-3, maxval=3), [1, 0])
return tf.tensordot(A, B, axes=1)
def generate_causality_mask(seq_len):
mask = 1 - np.cumsum(np.eye(seq_len, seq_len), 0)
return mask
sample_tensor = make_dot_product_tensor((20, 512))
sample_tensor = sample_tensor / tf.sqrt(512.)
mask = generate_causality_mask(sample_tensor.shape[0])
fig = plt.figure(figsize=(7, 7))
ax1 = fig.add_subplot(121)
ax2 = fig.add_subplot(122)
ax1.set_title('1) Causality Mask')
ax2.set_title('2) Masked Attention')
ax1.imshow((tf.ones(sample_tensor.shape) + mask).numpy(), cmap='cividis')
mask *= -1e9
ax2.imshow(tf.nn.softmax(sample_tensor + mask, axis=-1).numpy(), cmap='cividis')
plt.show()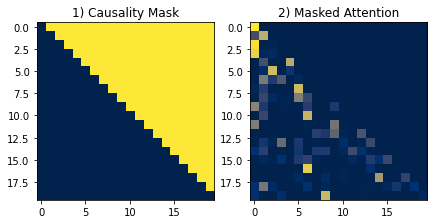
좌측이 실제 마스크 형태, 우측은 마스킹 적용된 Attention으로 마스킹은 마스킹 할 영역을 -∞로 채우고, 그 외 영역을 0으로 채운 배열을 Dot-Product된 값에 더해주는 방식으로 진행되며, 후에 Softmax는 큰 값에 높은 확률을 할당하므로 -∞로 가득찬 마스킹 영역엔 무조건 0 확률을 할당
Multi-Head Attention

바나나라는 단어가 512차원 임베딩을 가진다고 볼 경우, 64차원은 노란색, 64차원은 달콤한 맛에 대한 정보를 표현하며 기타 가격과 유통기한까지 표현될 수 있음. 저자들은 이 정보를 섞지말고 여러 Head로 나누어 처리해서 Embedding의 다양한 정보를 캐치하고자 함

Multi-Head Attention Head는 8개를 사용하며, Embedding된 10개 단어 문장의 10,512 형태를 가지면 Multi-Head Attention은 이를 10, 8, 64로 분할하여 연산하고 독립적으로 Attention 후 붙여서 10,512의 형태로 되돌려 연산함
단 이때 Head로 쪼갠 Embedding끼리 유사 특성을 가진단 보장이 없으므로 앞단에 Linear 레이어를 추가해서 데이터를 특정 분포로 매핑시켜, 적합한 공간으로 Embedding을 매핑함

비슷한 이유로 Head가 Attention한 값이 균일 분포를 가진단 보장이 없으므로 모든 Attention을 합친 후 최종 Linear 레이어를 거치면 Multi-Head Attention이 마무리됨
Position-wise Feed-Forward Networks


W는 Linear 레이어, max(0, x) 활성 함수는 ReLU를 사용함
예를 들어 10단어로 이루어진 Attention된 문장 [10, 512]를 [10, 2048] 공간으로 매핑, 활성함수를 적용 후 다시 [10, 512] 공간으로 되롤림

position마다, 개별 단어마다 적용되기 때문에 position-wise이며 두번의 linear transformation과 activation fuction Relu를 거치게 됨

포지션마다 같은 parameter W,b를 사용하지만 layer가 달라지면 다른 parameter를 사용함

Convolutional 레이어의 Weight는 [입력 차원 수 X 출력 차원 수 X 커널의 크기] 이므로 커널의 크기가 1일 경우 Linear 레이어와 동일한 크기의 Weight를 갖게 됨
구글에선 AutoML을 활용해 Evolved Transformer라는 트랜스포머 구조를 찾게됨
두 층의 레이어 중 아래층 레이어에서 차이를 보이는데 이 때 Linear 레이어를 Convolution 레이어로 표기함
Applying AutoML to Transformer Architectures
Posted by David So, Software Engineer, Google AI Since it was introduced a few years ago, Google’s Transformer architecture has been ap...
ai.googleblog.com
Additional Techniques

Layer Normalization
Layer Normalization은 데이터를 Feature 차원에서 정규화 하는 방법으로, 10단어로 Embedding된 문장에서 [10, 512]에서 512차원 Feature를 정규화하여 분포를 일정하게 맞춰주게 됨
참조링크 다양한 Normalization 방법
Introduction to Deep Learning Normalization
수 많은 정규화들을 한번 가볍게 읽어봅시다.
subinium.github.io
Batch Normalization : 정규화를 Batch 차원에서 진행
Layer Normalization : 정규화를 Feature 차원에서 진행
Residual Connection
Skip Connection이라고도 불리며, ResNet 모델에서 처음 사용됨
컴퓨터 비전에서 유명한 모델
(7) ResNet (Residual Connection)
ResNet (2015)¶ ResNet은 2015년도 ILSVRC 에서 우승을 차지한 모델입니다. 총 152개의 레이어를 가진 Ultra-deep한 네트워크입니다. Difficulty of Training Deep CNN¶ 2014년도에 CNN의 Depth와 Structure을..
itrepo.tistory.com
네트워크가 깊어질 수록 Train하는 것이 어려워지는데 이를 해결하기 위한 방법을 제시
Detailed Guide to Understand and Implement ResNets - CV-Tricks.com
ResNet is one of the most powerful deep neural networks which has achieved fantabulous performance results in the ILSVRC 2015 classification challenge. ResNet has achieved excellent generalization performance on other recognition tasks and won the first pl
cv-tricks.com
Learning Rate Schedular
트랜스포머 훈련에서 Adam Optimizer를 사용하여 Learning Rate 수식에 따라 변화하며 사용함

위 수식을 사용하면 Warmup_steps까지 lrate가 선형적으로 증가하고 이후에는 step_num에 비례해 점차 감소하게 됨
import matplotlib.pyplot as plt
import numpy as np
d_model = 512
warmup_steps = 4000
lrates = []
for step_num in range(1, 50000):
lrate = (np.power(d_model, -0.5)) * np.min(
[np.power(step_num, -0.5), step_num * np.power(warmup_steps, -1.5)])
lrates.append(lrate)
plt.figure(figsize=(6, 3))
plt.plot(lrates)
plt.show()
초반 학습이 잘되지 않은 상태에서 학습 효율이 늘어나며 학습 이후 학습의 초반과 후반은 Warmup_steps 값에 따라 결정
Weight Sharing
모델 일부 레이어가 동일한 사이즈 Weight를 가질 때 사용하는 방법으로 하나의 Weight를 두개 이상의 레이어가 동시에 사용하게 한 것
대표적으로는 언어 모델 Embedding 레이어와 최종 Linear 레이어가 동일한 사이즈의 Weight를 가짐
Transformer에서 Decoder의 Embedding 레이어와 출력층 Linear 레이어의 Weight를 공유하는 방식을 사용함
소스 Embedding과 타겟 Embedding도 논문상에서 공유했으나, 언어의 유사성에 따라 선택적으로 사용하며, 이것 까지 공유하면 총 3개의 레이어를 동일한 Weight를 사용하게 됨
또한 Linear 레이어와 Embedding 레이어 Feature 분포가 다르므로 Embedding 된 값에 d model의 제곱근 값을 곱해서 분포를 맞춤과 동시에 Positional Encoding이 Embedding값에 큰 영향 미치는 것을 방지
트랜스포머, 그 후
BERT, GPT
차이점
- GPT는 단방향 Attention을 사용하지만 BERT는 양방향 Attention을 사용
- GPT는 트랜스포머에서 디코더만 사용하고 BERT는 인코더만 사용
- GPT는 문장을 생성할 수 있고 BERT는 문장 의미를 추출하는 데 강점
Transformer-XL
문단 문맥을 파악하는 수준까지 긴 입력 길이를 처리할 수 있게 Recurrence라는 개념이 추가된 Transformer-XL이 제안되기도 함
Transformer-XL 자료정리 및 설명요약
-XLNet 1. 참고 링크 1) PR-175: XLNet: Generalized Autoregressive Pretraining for Language Understanding 동영상 정리글입니다. 2. 설명 -Transformer의 한계 1) Attention N Encoder Decoder이다, Context V..
comeng.tistory.com
Reformer
Reformer는 트랜스포머를 연산량 측면에서 혁신적으로 개선한 모델
Reformer:효율적인 트랜스포머
2020년 1월 16일 (목) 구글 AI 리서치 블로그 | 언어, 음악 또는 비디오와 같은 순차적 데이터를 이해하는 것은, 특히 광범위한 주변 환경에 의존하는 경우 어려운 작업입니다. 예를 들어, 비디오에
brunch.co.kr
더 읽어볼 참조링크
Facebook에 로그인
메뉴를 열려면 alt + / 키 조합을 누르세요
www.facebook.com
[논문리뷰] Are Sixteen Heads Really Better than One?
논문 : arxiv.org/pdf/1905.10650.pdf 깃헙: github.com/pmichel31415/are-16-heads-really-better-than-1 개요 Attention 알고리즘은 매우 강력하면고 범용적인 매커니즘으로, 뉴럴 모델이 중요한 정보 조각에 집..
littlefoxdiary.tistory.com
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| BERT Pretrain with TPU (0) | 2022.04.19 |
|---|---|
| 기계 번역의 흐름 (0) | 2022.04.08 |
| Attention translator (0) | 2022.04.04 |
| Seq2seq과 Attention (0) | 2022.03.30 |
| 워드 임베딩 (0) | 2022.03.24 |