
Chat bot
대화형 챗봇
자연스럽게 대화가 가능한 챗봇
- 비용: 매우높음
- 전문성: 매우높음
- 시간: 매우높음

트리형 챗봇
정해진 트리구조에 따라 답변을 얻는 형태(객관식 문제 풀이와 비슷)
- 비용: 매우 낮음
- 전문성: 낮음
- 시간: 보통

추천형 챗봇
사전에 정의된 답변의 리스트를 알고리즘 결과에 따라 우선순위별로 보여주는 챗봇
- 비용: 보통
- 전문성: 보통
- 시간: 많음

시나리오형 챗봇
정해진 시나리오를 수행하는 챗봇
- 비용: 보통
- 전문성: 보통
- 시간: 보통
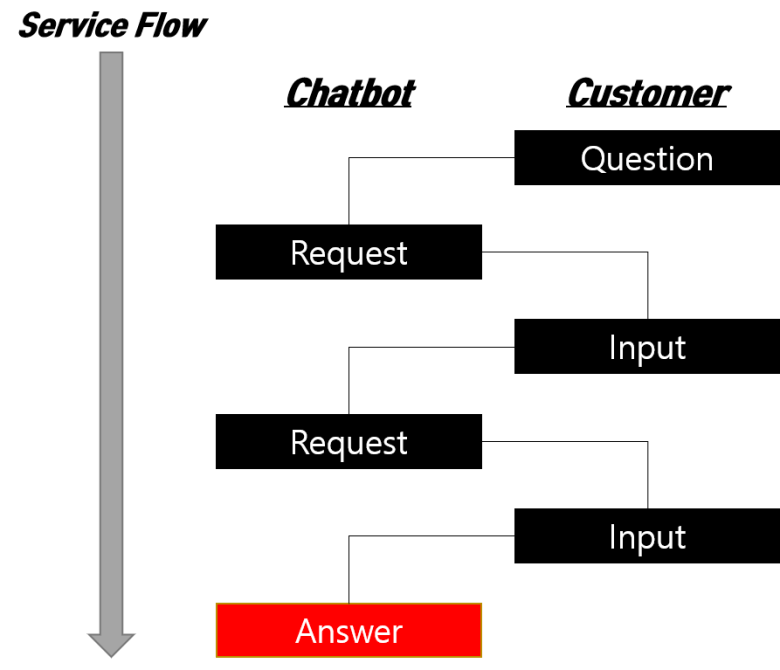
결합형 챗봇
비즈니스 목적에 따라 챗봇 유형들의 결합 설계

인공지능 챗봇(Chatbot), 챗봇 역사의 모든 것
엄청난 기대에 대비해 저조한 성적을 거둔 챗봇. 이제, 마케팅 챗봇 개발자는 유저 적용, 사용 사례, 기술적 제한에 대해 걱정할 필요 없습니다. 그저 올바른 시장 진입 전략으로 올바른 문제를
blog.performars.com
인코더 디코더

인코더는 입력을, 디코더는 상응하는 출력 문장을 생성
훈련 데이터셋의 구성
(번역 시)
- 입력 : '저는 학생입니다'
- 출력 : 'I am a student'
(질문-답변 시)
- 입력 : '오늘의 날씨는 어때?'
- 출력 : '오늘은 매우 화창한 날씨야'
트랜스포머의 인코더 디코더





Positional Encoding을 사용하는 점이 기존 RNN과 대비되는 큰 특징
문장을 한번에 입력받으므로 문장의 몇번째 어순인지에 대한 정보를 입력


d_model은 임베딩 벡터의 차원, pos는 입력 문장에서의 임베딩 벡터의 위치, i는 벡터내 차원의 인덱스
임베딩 행렬과 포지셔널 행렬을 더하여 각 단어 벡터에 위치정보를 더함
트랜스포머의 어텐션
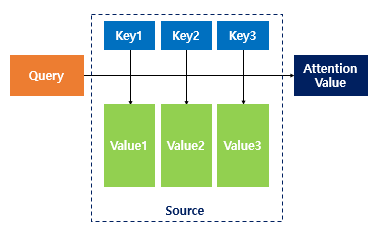
어텐션 함수는 주어진 쿼리에 대해서 키와 유사도를 각각 구함
이 유사도를 키와 맵핑되어 있는 각 값을 반영하고 유사도가 반영된 값을 모두 더해서 뭉치면 어텐션 값(Attention Value)
트랜스포머에서 사용된 어텐션

1. 인코더 셀프 어텐션
2. 디코더 셀프어텐션
3. 인코더-디코더 어텐션

트랜스포머에 어텐션 함수에 사용되는 쿼리, 키, 밸류는 기본적으로 단어 정보를 함축한 벡터
이는 임베딩 벡터와는 다른 트랜스포머의 여러 연산을 거친 단어벡터
- 인코더 셀프 어텐션 : 인코더의 입력으로 들어간 문장 내 단어들이 서로 유사도를 구함
- 디코더 셀프 어텐션 : 단어를 1개씩 생성하는 디코더가 이미 생성된 앞 단어들과의 유사도를 구함
- 인코더-디코더 어텐션 : 디코더가 잘 예측하기 위해 인코더에 입력된 단어들과 유사도를 구함
셀프 어텐션(Self Attention)
유사도를 구하는 대상이 현재 문장 내의 단어들로 서로 유사도를 구하는 경우

스케일드 닷 프로덕트 어텐션
유사도를 구하는 수식

Q, K, V는 각 쿼리, 키, 밸류의 뜻
어텐션 함수는 주어진 쿼리에 대해 모든 키와의 유사도를 구하며, 이 유사도를 키와 매핑된 값에 반영
유사도가 반영된 값을 모두 더하고 뭉쳐주면 어텐션 값
- Q, K, V는 단어 벡터를 행으로 하는 문장 행렬
- 벡터의 내적(dot product)는 벡터의 유사도 의미
- 특정 값을 분모로 사용하는 것은 값의 크기를 조절하는 스케일링 때문

초록색 행렬은 결국 각 단어 벡터의 유사도가 모두 기록된 유사도 행렬
이 유사도 값에 대해서 스케일링 할 경우, 행렬 전체를 특정 값으로 나누고 유사도를 0과 1사이의 Normalize 해주기 위해 소프트 맥수 함수를 사용 후 문장 행렬 V와 곱하면 어텐션 값


이 수식은 내적을 통해 단어 벡터간 유사도를 구하고 특정 값을 분모로 나누어 Q와 K의 유사도를 구했다고 해서
스케일드 닷 프로덕트 어텐션이라고 불림
어텐션 병렬 수행
트랜스포머에서는 num_heads라는 변수로 기계가 몇개의 머리를 사용할지 결정하는 파라미터가 존재

입력받은 문장 행렬을 num_head 수만큼 쪼개서 어텐션 수행 뒤 다시 concatenate 실행

num heads의 값이 8일 때 병렬로 수행되는 어텐션의 예제로, 8개의 heads가 다른 관점에서 어텐션을 수행하여 여러 정보를 캐치할 수 있게 됨
예를들어 it_이 animal이라고 보는관점, street라고 보는 관점이 모두 존재
이를 멀티 헤드 어텐션이라고 부름
마스킹
특정 값들을 가려서 실제 연산에 방해가 되지 않도록 하는 기법
패딩 마스킹(Padding Masking)
padding token을 이용한 방법

룩 어헤드 마스킹(Look-ahead masking)
자신보다 다음에 나올 단어를 참고하지 않도록 가리는 기법

위 그림에서 빨간색으로 색칠된 부분이 마스킹을 표현이며, 실제 어텐션 연산에서도 가리는 역할을해서 이전 단어들로만 유사도를 구할 수 있습니다
행은 query, 열은 key로 표현된 행렬.
인코더

하나의 인코더 층은 2개의 서브층으로 나누어 짐(셀프 어텐션, 피드 포워드 신경망)

디코더
디코더 층

첫번째는 셀프 어텐션, 두번째는 인코더-디코더 어텐션, 세번째는 피드포워드 신경망
인코더-디코더 어텐션은 셀프 어텐션과 달리 Query가 디코더의 벡터인 반면에 Key와 Value가 인코더의 벡터라는 특징이 있음
이 부분이 인코더가 입력문장으로부터 정보를 디코더에 전달하는 과정

인코더 셀프 어텐션처럼 디코더 셀프 어텐션, 인코더-디코더 어텐션 두개의 어텐션 모두 스케일드 닷 프로덕트 어텐션을 멀티 헤드 어텐션으로 병렬 수행
교사강요란?
테스트 과정에서 t 시점의 출력이 t+1 시점의 입력으로 사용되는 RNN 모델을 훈련시킬 때 사용하는 훈련 기법
모델이 t 시점에서 예측한 값을 t+1 시점에 입력으로 사용하지 않고 t 시점의 레이블, 즉 실제 알고 있는 정답을 t+1 시점의 입력으로 사용
훈련과정에서 이전 시점의 출력을 다음 시점의 입력으로 사용하면서 훈련 시킬 수도 있지만 한 번 잘못예측하면 뒤에 예측까지 영향을 미쳐 훈련 시간이 느려지게 됨
자기회귀 모델
이전 자신의 출력이 현재 자신의 상태를 결정하는 모델을 자기회귀 모델(auto-regressive model,AR)이라고 하며
RNN과 트랜스포머 디코더 또한 자기회귀 모델
예제는 깃허브 코드로 갈음합니다
GitHub - dlfrnaos19/rock_scissors_paper_classifier: task 1
task 1. Contribute to dlfrnaos19/rock_scissors_paper_classifier development by creating an account on GitHub.
github.com
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| -35일차- QnA 봇 만들기 (0) | 2022.02.17 |
|---|---|
| -34일차- Likelihood(MLE, MAP) (0) | 2022.02.16 |
| -32일차- 활성화함수 (0) | 2022.02.14 |
| -31일차- 정규화와 정칙화 (0) | 2022.02.11 |
| -30일차- 시계열 예측 ARIMA (0) | 2022.02.10 |