
KorQuAD, BERT, Pretrained Model
KorQuAD(The Korean Question Answering Dataset)
미국 스탠퍼드 대학에서 구축한 대용량 데이터셋인 SQuAD를 벤치마킹한 것
KorQuAD
What is KorQuAD 2.0? KorQuAD 2.0은 KorQuAD 1.0에서 질문답변 20,000+ 쌍을 포함하여 총 100,000+ 쌍으로 구성된 한국어 Machine Reading Comprehension 데이터셋 입니다. KorQuAD 1.0과는 다르게 1~2 문단이 아닌 Wikipedia artic
korquad.github.io
- 총 100000+ 쌍으로 구성된 한국어 Machine Reading Comprehension 데이터셋
- wikipedia article 전체에서 답을 찾아야 함
- 문서들의 길이가 길어 탐색시간이 길어질 수 있음
- HTML tag등 문서 구조에 대한 이해도 필요
- 총 102960개의 질의응답, Training 83,486, Dev set 10165
BERT
BERT Tokenizer
보통은 WordPiece 모델 사용이 일반적이나, 여기에서는 SentencePiece 모델을 이용해
Subword 기반 텍스트 전처리 진행
SentencePiece내에 Wordpiece모델을 통합하여 제공하여 유용함
BERT 모델 구조
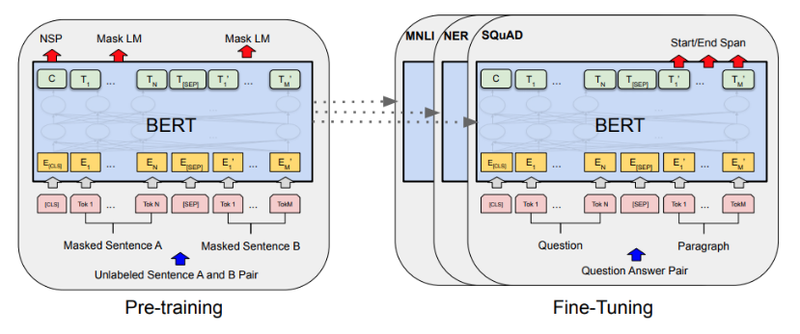
기존 트랜스포머는 Encoder Decoder 구조로 번역기 모델 형태 구현에 적당했으나
여기에서는 Transformer Encoder 구조만을 활용, Layer는 12개 이상으로 정함
Mask LM
입력 데이터가 나는 <mask> 먹었다 일 때 BERT 모델이 <mask>가 밥을 임을 맞출 수 있도록 하는 모델
이전 Next Token Prediction Language Model과 대비시켜 다음 빈칸에 알맞는 말 문제를 엄청 푸는 언어모델
Next Sentence Prediction
나는 밥을 먹었다. <SEP> 그래서 지금 배가 부르다
가 주어졌을 때 <SEP> 경계로 좌우 두 문장이 순서대로 이어지는 문장이 맞는지 맞추는 문제
첫번째 바이트에서 NSP 결과값을 리턴
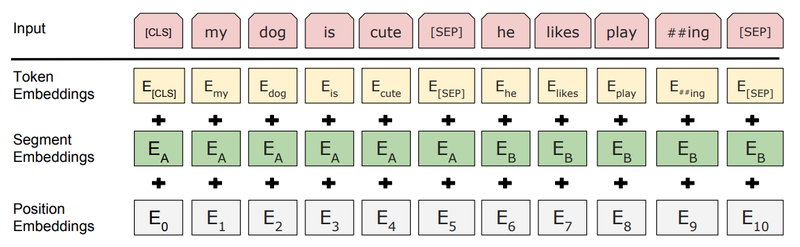
모델에 입력되는 것은 Token , Segment, Position Embedding 3가지가 더해져서 입력되며, 그 이후
layer normalization, dropout이 추가적용
Token Embedding
BERT의 텍스트의 tokenizer로 Word Piece model이라는 subword tokenizer를 사용
문자 단위 임베딩이 기본이지만 자주 등장하는 긴 길이 subword도 하나의 단위로 만들고, 자주 등장하지 않는 단어는 다시 subword 단위로 만드는데, 이는 OOV(out-of-vocabulary)처리되는 것을 방지하는 장점
Segment embedding
기존 Transformer에 없던 임베딩으로 각 단어가 어느 문장에 포함되는지 역할을 규정함
단어가 Question인지 Context 문장에 속하는지 구분이 필요한 경우에 이 임베딩이 유용하게 사용됨
Position Embedding
이 임베딩은 기존 Transformer와 동일
모델 사용 예제
GitHub - dlfrnaos19/rock_scissors_paper_classifier: task 1
task 1. Contribute to dlfrnaos19/rock_scissors_paper_classifier development by creating an account on GitHub.
github.com
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| -38일차- 추천 시스템 활용 (0) | 2022.02.22 |
|---|---|
| -37일차- 추천시스템 (0) | 2022.02.21 |
| -34일차- Likelihood(MLE, MAP) (0) | 2022.02.16 |
| -33일차- 트랜스포머로 대화형 챗봇 만들기 (0) | 2022.02.15 |
| -32일차- 활성화함수 (0) | 2022.02.14 |