
추천시스템이란?
사용자에게 관련된 아이템을 추천해 주는 것

추천 로직에서 범주형 데이터로 다루기
영화와 유저 데이터는 이산적이고, 범주형 데이터임
숫자 벡터로 변환 뒤 유사도를 계산
범주형 데이터들을 숫자로 이루어진 벡터로 변환 후 거리를 계산하여 유사도 계산
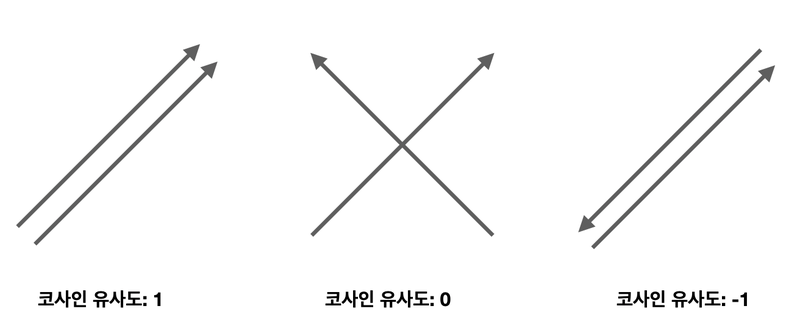
코사인 유사도
두 벡터의 방향이 이루는 각에 코사인을 취해 구하는 유사도로 방향이 동일할 경우 1, 90도 각을 이루면 0,
180도면 -1의 값을 갖게 됨
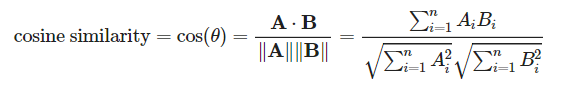
from numpy import dot
from numpy.linalg import norm
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))
cos_sim(t1, t2)
#result
0.7745966692414834
사이킷런 활용
from sklearn.metrics.pairwise import cosine_similarity
t1 = np.array([[1, 1, 1]])
t2 = np.array([[2, 0, 1]])
cosine_similarity(t1,t2)
#result
array([[0.77459667]])
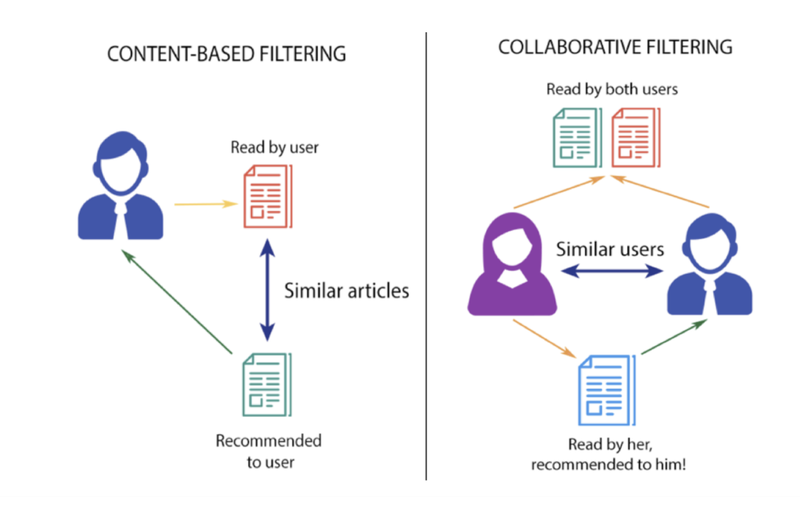
추천 시스템의 종류
콘텐츠 기반 필터링(Content Based Filtering)
협업 필터링(Collaborative Filtering)
- 사용자 기반
- 아이템 기반
- 잠재요인 협업 필터링(latent factor collaborative filtering) -> 행렬 인수분해(matrix factorization)
딥러닝 적용 or Hybrid 방식
콘텐츠 기반 필터링
# movie_dataset.csv 다운
!wget https://aiffelstaticprd.blob.core.windows.net/media/documents/movie_dataset.csv
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import os
csv_path = os.getenv('HOME')+'/aiffel/movie_recommendation/movie_dataset.csv'
df = pd.read_csv(csv_path)
df.columns
#result
Index(['index', 'budget', 'genres', 'homepage', 'id', 'keywords',
'original_language', 'original_title', 'overview', 'popularity',
'production_companies', 'production_countries', 'release_date',
'revenue', 'runtime', 'spoken_languages', 'status', 'tagline', 'title',
'vote_average', 'vote_count', 'cast', 'crew', 'director'],
dtype='object')features = ['keywords','cast','genres','director']
def combine_features(row):
return row['keywords']+" "+row['cast']+" "+row['genres']+" "+row['director']
for feature in features:
df[feature] = df[feature].fillna('')
df["combined_features"] = df.apply(combine_features,axis=1)
df["combined_features"]
#result
0 culture clash future space war space colony so...
1 ocean drug abuse exotic island east india trad...
2 spy based on novel secret agent sequel mi6 Dan...
3 dc comics crime fighter terrorist secret ident...
4 based on novel mars medallion space travel pri...
...
4798 united states\u2013mexico barrier legs arms pa...
4799 Edward Burns Kerry Bish\u00e9 Marsha Dietlein...
4800 date love at first sight narration investigati...
4801 Daniel Henney Eliza Coupe Bill Paxton Alan Ru...
4802 obsession camcorder crush dream girl Drew Barr...
Name: combined_features, Length: 4803, dtype: object벡터화 및 코사인 유사도 계산
cv = CountVectorizer()
count_matrix = cv.fit_transform(df["combined_features"])
print(type(count_matrix))
print(count_matrix.shape)
print(count_matrix)
#result
<class 'scipy.sparse.csr.csr_matrix'>
(4803, 14845)
(0, 3115) 1
(0, 2616) 1
(0, 4886) 1
(0, 12386) 2
(0, 14235) 1
(0, 2755) 1
...CSR Matrix는 Sparse한 matrix에서 0이 아닌 유효한 데이터로 채워지는 데이터의 값과 좌표 정보로 구성하여
메모리 사용은 최소로, Sparse한 matrix와 동일한 행렬을 표현하는 데이터구조
4803개의 영화 vertorize 후, 코사인 유사도 계산
cosine_sim = cosine_similarity(count_matrix)
print(cosine_sim)
print(cosine_sim.shape)
#result
[[1. 0.10540926 0.12038585 ... 0. 0. 0. ]
[0.10540926 1. 0.0761387 ... 0.03651484 0. 0. ]
[0.12038585 0.0761387 1. ... 0. 0.11145564 0. ]
...
[0. 0.03651484 0. ... 1. 0. 0.04264014]
[0. 0. 0.11145564 ... 0. 1. 0. ]
[0. 0. 0. ... 0.04264014 0. 1. ]]
(4803, 4803)코사인 유사도로 계산된 가장 비슷한 영화를 3편 선별
def get_title_from_index(index):
return df[df.index == index]["title"].values[0]
def get_index_from_title(title):
return df[df.title == title]["index"].values[0]
movie_user_likes = "Avatar"
movie_index = get_index_from_title(movie_user_likes)
similar_movies = list(enumerate(cosine_sim[movie_index]))
sorted_similar_movies = sorted(similar_movies,key=lambda x:x[1],reverse=True)[1:]
i=0
print(movie_user_likes+"와 비슷한 영화 3편은 "+"\n")
for item in sorted_similar_movies:
print(get_title_from_index(item[0]))
i=i+1
if i==3:
break
#result
Avatar와 비슷한 영화 3편은
Guardians of the Galaxy
Aliens
Star Wars: Clone Wars: Volume 1
협업 필터링
협업 필터링(Collaborative Filtering)은 과거의 사용자 행동 양식 데이터를 기반으로 추천하는 방식
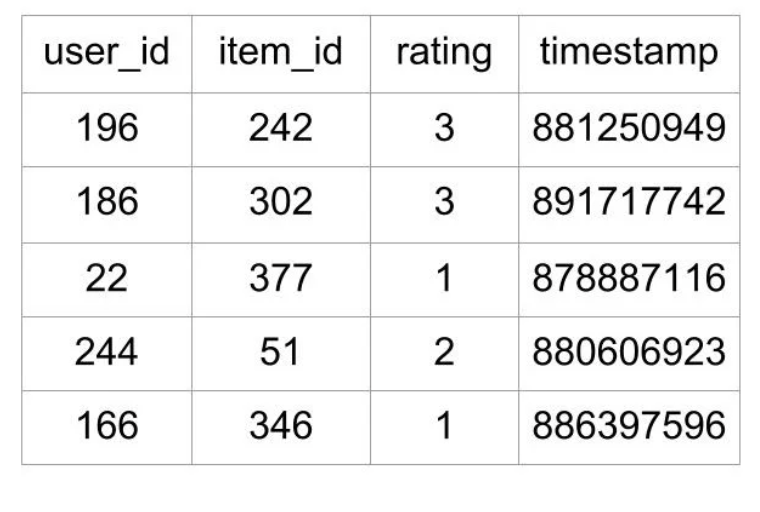
위 형식의 데이터가 있을 경우, 사용자와 아이템 간 interaction matrix로 변환함 이를 평점 행렬이라 함

이러한 행렬을 데이터로 만들면 희소한(sparse)한 행렬이 만들어짐
협업 필터링의 종류
- 사용자 기반 : 유사도 계산
- 아이템 기반 : 유사도 계산
- 잠재요인(latent factor) 방식 : 행렬 인수분해를 이용한 잠재요인 분석(최근 사례가 많음)
사용자 기반
사용자와 비슷한 고객들이 상품을 구매한 것에 대한 추천
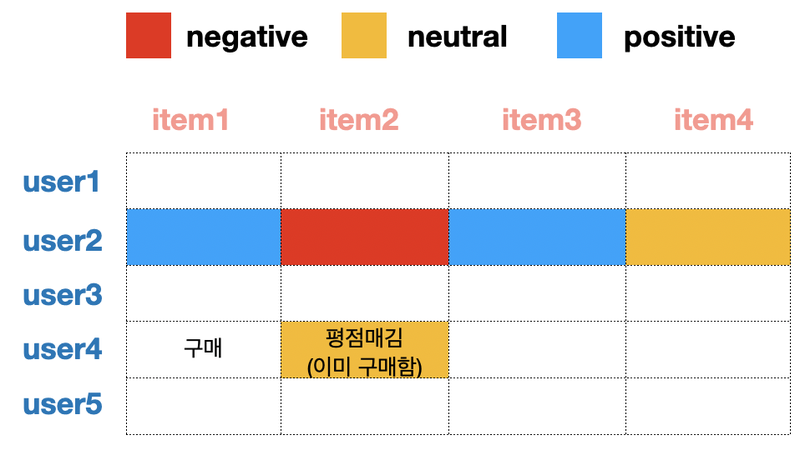
User2가 User4와 비슷한 고객일 때 User2가 선호한 제품인 item3을 User4에게 추천하는 방식
아이템 기반
아이템 간 유사도를 측정하여 아이템 추천, 아이템 기반 방식이 정확도가 더 높다고 알려져 있음
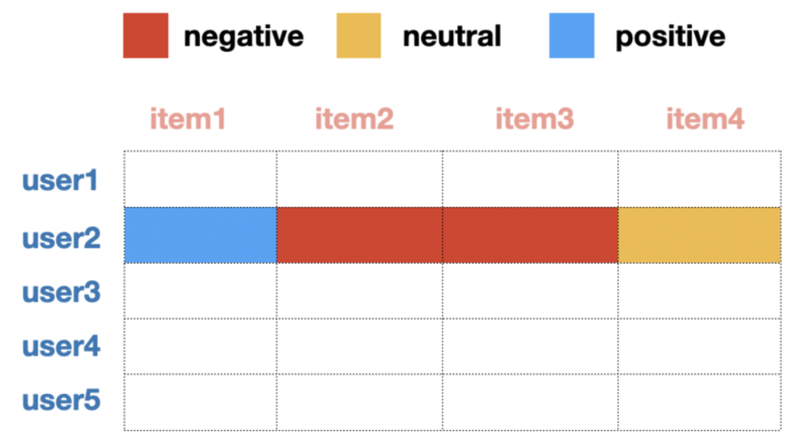
아이템에 대한 다른 User들의 선호도 조사
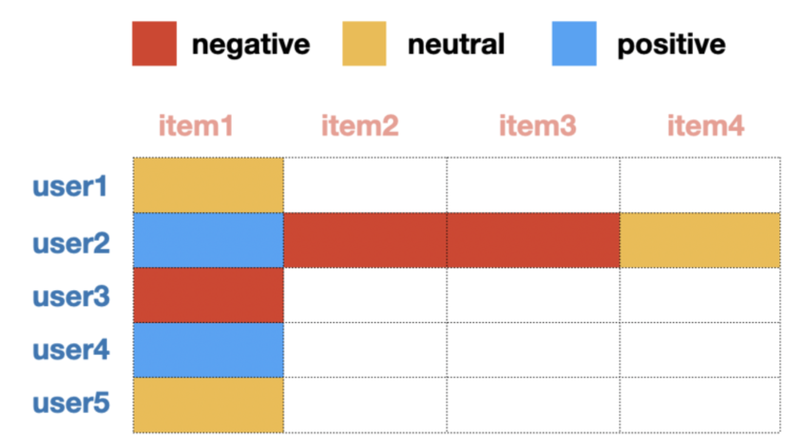
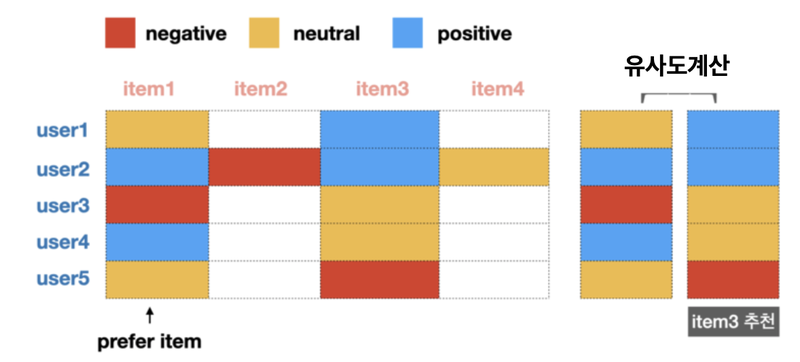
행렬 인수분해
행렬 인수 분해의 종류
- SVD(Singular Vector Decomposition
- ALS(Alternating Least Squares)
- NMF(Non-Negative Factorization)
행렬 인수분해는 인수분해와 비슷함
30 = 6 * 5, = 3 * 10 = 1 * 30 등으로 표현이 가능
SVD
특이값 분해로, M * N 형태 행렬 A를 다음과 같은 형태로 분해하여 표현
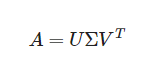
SVD의 참조
특이값 분해(SVD) - 공돌이의 수학정리노트
angeloyeo.github.io
[선형대수학 #4] 특이값 분해(Singular Value Decomposition, SVD)의 활용
활용도 측면에서 선형대수학의 꽃이라 할 수 있는 특이값 분해(Singular Value Decomposition, SVD)에 대한 내용입니다. 보통은 복소수 공간을 포함하여 정의하는 것이 일반적이지만 이 글에서는 실수(real
darkpgmr.tistory.com
핵심은 특이값 크기에 따라 A 정보량이 결정되기 때문에 값이 큰 몇개 특이값을 가지고 충분히 유용한 정보 유지가 가능
SVD 실습
numpy 참조
numpy.linalg.svd — NumPy v1.22 Manual
If True (default), u and vh have the shapes (..., M, M) and (..., N, N), respectively. Otherwise, the shapes are (..., M, K) and (..., K, N), respectively, where K = min(M, N).
numpy.org
import numpy as np
from numpy.linalg import svd
np.random.seed(30)
A = np.random.randint(0, 100, size=(4, 4))
A
#result
array([[37, 37, 45, 45],
[12, 23, 2, 53],
[17, 46, 3, 41],
[ 7, 65, 49, 45]])
svd(A)
#result
(array([[-0.54937068, -0.2803037 , -0.76767503, -0.1740596 ],
[-0.3581157 , 0.69569442, -0.13554741, 0.60777407],
[-0.41727183, 0.47142296, 0.28991733, -0.72082768],
[-0.6291496 , -0.46389601, 0.55520257, 0.28411509]]),
array([142.88131188, 39.87683209, 28.97701433, 14.97002405]),
array([[-0.25280963, -0.62046326, -0.4025583 , -0.6237463 ],
[ 0.06881225, -0.07117038, -0.8159854 , 0.56953268],
[-0.73215039, 0.61782756, -0.23266002, -0.16767299],
[-0.62873522, -0.47775436, 0.34348792, 0.50838848]]))
U, Sigma, VT = svd(A)
print('U matrix: {}\n'.format(U.shape),U)
print('Sigma: {}\n'.format(Sigma.shape),Sigma)
print('V Transpose matrix: {}\n'.format(VT.shape),VT)
#result
U matrix: (4, 4)
[[-0.54937068 -0.2803037 -0.76767503 -0.1740596 ]
[-0.3581157 0.69569442 -0.13554741 0.60777407]
[-0.41727183 0.47142296 0.28991733 -0.72082768]
[-0.6291496 -0.46389601 0.55520257 0.28411509]]
Sigma: (4,)
[142.88131188 39.87683209 28.97701433 14.97002405]
V Transpose matrix: (4, 4)
[[-0.25280963 -0.62046326 -0.4025583 -0.6237463 ]
[ 0.06881225 -0.07117038 -0.8159854 0.56953268]
[-0.73215039 0.61782756 -0.23266002 -0.16767299]
[-0.62873522 -0.47775436 0.34348792 0.50838848]]
Sigma_mat = np.diag(Sigma)
A_ = np.dot(np.dot(U, Sigma_mat), VT)
A_
#result
array([[37., 37., 45., 45.],
[12., 23., 2., 53.],
[17., 46., 3., 41.],
[ 7., 65., 49., 45.]])복원된 내용이 같음
Truncated SVD
SVD의 일종으로 다른말로 LSA(Latent semantic analysis)잠재의미분석 이라고도 함, 완벽히 같은 행렬이 나오지 않음
sklearn.decomposition.TruncatedSVD
Examples using sklearn.decomposition.TruncatedSVD: Hashing feature transformation using Totally Random Trees Hashing feature transformation using Totally Random Trees, Manifold learning on handwrit...
scikit-learn.org
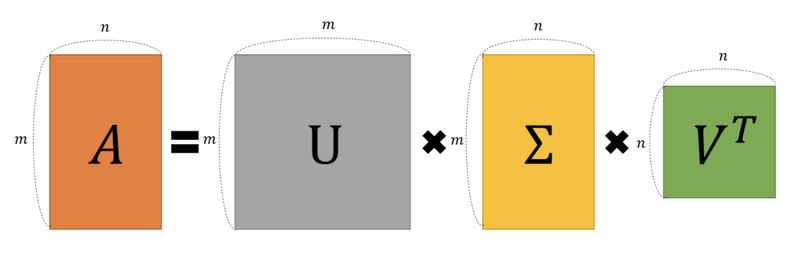
특이값 분해를 평가행렬에 적용한 잠재요인 분석 도식화
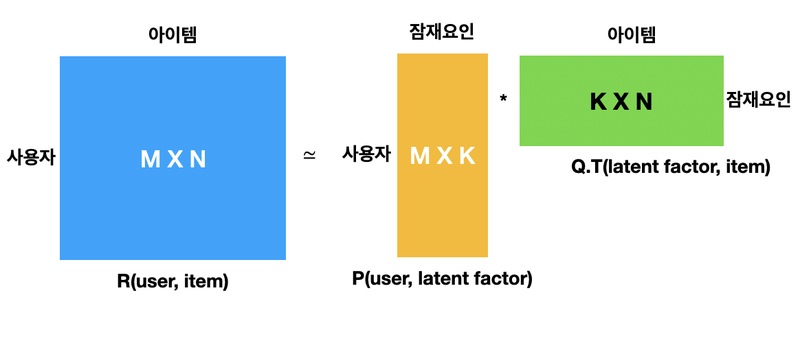
- R: 사용자와 아이템 사이의 행렬
- P: 사용자와 잠재요인 사이의 행렬
- Q: 아이템과 잠재요인 사이의 행렬 -> 전치 행렬 형태로 나타냄
사용자가 아이템에 대해 평점을 매기는 요인이 많으므로, 이런 요인들을 그냥 잠재요인으로 취급한 뒤
SVD 기법으로 분해 후 합치는 방법으로 이를 벡터화하여 추천
실제 추천 시스템
실제 유튜브와 넷플릭스 같은 곳은 더 많은 요소를 고려하게 됨
시청시간, 웹사이트 보낸 시간, 사이트 유입, 등 모든 Digital Footprint를 기록
CTR(Click Through Rate)
클릭률은 주요 마케팅 지표로 작용
Clickthrough rate (CTR): Definition - Google Ads Help
A ratio showing how often people who see your ad or free product listing end up clicking it. Clickthrough rate (CTR) can be used to gauge how well your keywords and ads, and free listings, are performing. CTR is the number of clicks that your ad receives d
support.google.com
데이터를 기반으로 사용자에게 적절한 제품을 추천하는 것, 그리고 구매로 이어지는 것은 매출과 직결되는 문제로
좋은 추천 시스템을 위해 어떤 데이터를 쓸지에 대한 고민, 사용자와 연관있고 구매와 직결되는 각종 데이터를 수집하고
정렬하여 순위를 매긴 후 평가하는 작업을 반복하여 추천시스템을 완성해야함
넷플릭스
왓차
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| -39일차- 멀티태스킹 (0) | 2022.02.23 |
|---|---|
| -38일차- 추천 시스템 활용 (0) | 2022.02.22 |
| -35일차- QnA 봇 만들기 (0) | 2022.02.17 |
| -34일차- Likelihood(MLE, MAP) (0) | 2022.02.16 |
| -33일차- 트랜스포머로 대화형 챗봇 만들기 (0) | 2022.02.15 |