
멀티태스킹
컴퓨팅 자원을 최적화 하는 법, 병렬 컴퓨팅, 분산 컴퓨팅 등의 개념
Difference Between Concurrency and Parallelism (with Comparison Chart) - Tech Differences
The crucial difference between concurrency and parallelism is that concurrency is about dealing with a lot of things at same time (gives the illusion of simultaneity) or handling concurrent events essentially hiding latency while parallelism is about doing
techdifferences.com
동시성과 병렬성의 주요 차이점
동시성은 여러 작업을 동시에 실행하고 관리하는 행위인 반면 병렬 처리는 다양한 작업을 동시에 실행하는 행위
병렬 처리는 다중 프로세서 시스템과 같은 다중 CPU를 사용하고 이러한 처리 장치 또는 CPU에서 서로 다른 프로세스를 작동하여 얻을 수 있음
동시성은 CPU에서 프로세스의 인터리빙 작업, 특히 컨텍스트 스위칭에 의해 달성됨
단일 처리 장치를 사용하여 동시성을 구현할 수 있지만 병렬 처리의 경우에는 불가능하므로 여러 처리 장치가 필요



동기(Synchronous), 비동기(Asynchronous)

- 동기 : 어떤일이 순차적으로 실행됨
- 비동기 : 비순차적으로 실행됨
I/O Bound vs CPU Bound
- I/O 바운드 : 입력과 출력에서의 데이터(파일)처리에 시간이 소요될 때
- CPU 바운드 : 복잡한 수식 계산이나 그래픽 작업과 같은 많은 계산이 필요할 때
What do the terms "CPU bound" and "I/O bound" mean?
What do the terms "CPU bound" and "I/O bound" mean?
stackoverflow.com
프로세스
하나의 프로그램을 실행할 때 운영체제는 한 프로세스를 생성함
프로세스는 운영체제의 커널에서 시스템 자원(CPU, 메모리, 디스크)및 자료구조를 이용함
import os
# process ID
print("process ID:", os.getpid())
# user ID
print("user ID:", os.getuid())
# group ID
print("group ID:", os.getgid())
# 현재 작업중인 디렉토리
print("current Directory:", os.getcwd())
#result
process ID: 16
user ID: 0
group ID: 0
current Directory: /aiffel
스레드


프로파일링(Profiling)
코드에서 시스템의 어느 부분이 느린지, 어디서 RAM을 많이 사용하고 있는지 확인할 때 사용하는 기법
import timeit
def f1():
s = set(range(100))
def f2():
l = list(range(100))
def f3():
t = tuple(range(100))
def f4():
s = str(range(100))
def f5():
s = set()
for i in range(100):
s.add(i)
def f6():
l = []
for i in range(100):
l.append(i)
def f7():
s_comp = {i for i in range(100)}
def f8():
l_comp = [i for i in range(100)]
if __name__ == "__main__":
t1 = timeit.Timer("f1()", "from __main__ import f1")
t2 = timeit.Timer("f2()", "from __main__ import f2")
t3 = timeit.Timer("f3()", "from __main__ import f3")
t4 = timeit.Timer("f4()", "from __main__ import f4")
t5 = timeit.Timer("f5()", "from __main__ import f5")
t6 = timeit.Timer("f6()", "from __main__ import f6")
t7 = timeit.Timer("f7()", "from __main__ import f7")
t8 = timeit.Timer("f8()", "from __main__ import f8")
print("set :", t1.timeit(), '[ms]')
print("list :", t2.timeit(), '[ms]')
print("tuple :", t3.timeit(), '[ms]')
print("string :", t4.timeit(), '[ms]')
print("set_add :", t5.timeit(), '[ms]')
print("list_append :", t6.timeit(), '[ms]')
print("set_comprehension :", t5.timeit(), '[ms]')
print("list_comprehension:", t6.timeit(), '[ms]')#result
set : 1.6251983839993045 [ms]
list : 0.7775054279991309 [ms]
tuple : 0.7847412840001198 [ms]
string : 0.3994056020001153 [ms]
set_add : 5.637236673001098 [ms]
list_append : 5.063371555999765 [ms]
set_comprehension : 5.654992277000929 [ms]
list_comprehension: 5.063802713000769 [ms]위에 예시는 가장 단순한 예시이며
프로파일링은 코드의 병목을 찾아내고 성능을 측정해주는 도구로서 cProfile, profile등의 도구가 있음
파이썬 프로파일러 — Python 3.10.2 문서
파이썬 프로파일러 소스 코드: Lib/profile.py 및 Lib/pstats.py 프로파일러 소개 cProfile과 profile은 파이썬 프로그램의 결정론적 프로파일링 (deterministic profiling)을 제공합니다. 프로파일 (profile)은 프로그
docs.python.org
line profiler를 사용하여 파이썬의 각 라인이 어떻게 돌아가는지를 알아보자.
intro
frhyme.github.io
Scale Up, Scale out
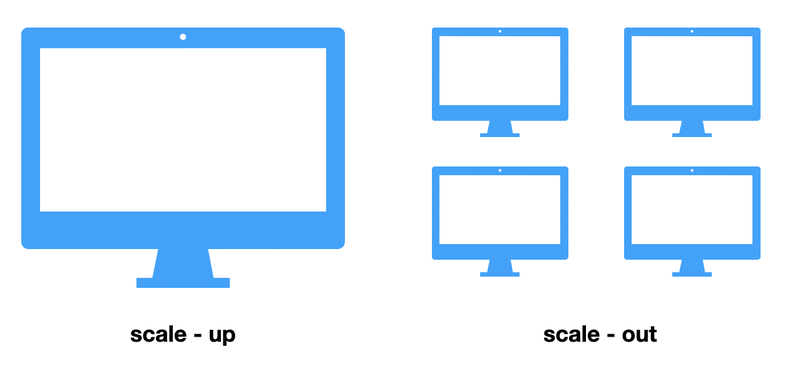
다중 서버 환경에서 Session은 어떻게 공유하고 관리할까? - 1편 (Scale-Up / Scale-Out이란?)
개요 지난 시간 세션과 쿠키를 이용한 로그인에 대해 알아보았습니다. 이러한 개념을 바탕으로 로그인 기능 개발을 들어가기 전에 생각해볼 문제가 생겼습니다. 현재 프로젝트의 사용자가 많
hyuntaeknote.tistory.com
- Scale-Up 단일 서버의 성능을 증가시켜 더 많은 요청을 처리하는 방법
- Scale-out 동일 사양의 새로운 서버를 추가하여 성능을 증가시키는 방법
멀티 태스킹 예제
threading — Thread-based parallelism — Python 3.7.12 documentation
threading — Thread-based parallelism Source code: Lib/threading.py This module constructs higher-level threading interfaces on top of the lower level _thread module. See also the queue module. Changed in version 3.7: This module used to be optional, it i
docs.python.org
스레드 사용 예제(스레드 상속시 스레드 할당된 모습)
from threading import *
class Delivery:
def run(self):
print("delivering")
work1 = Delivery()
print(work1.run)
class Delivery(Thread):
def run(self):
print("delivering")
work2 = Delivery()
print(work2.run)
#result
<bound method Delivery.run of <__main__.Delivery object at 0x7faefc693730>>
<bound method Delivery.run of <Delivery(Thread-14, initial)>>
스레드 사용한 예제(스레드 가동 및 종료)
from threading import *
from time import sleep
Stopped = False
def worker(work, sleep_sec):
while not Stopped:
print('do ', work)
sleep(sleep_sec)
print('retired..')
t = Thread(target=worker, args=('Overwork', 3))
t.start()
# 이 코드 블럭을 실행하기 전까지는 일꾼 스레드는 종료하지 않습니다.
Stopped = True
t.join()
print('worker is gone.')
멀티프로세스
multiprocessing — Process-based parallelism — Python 3.7.12 documentation
multiprocessing is a package that supports spawning processes using an API similar to the threading module. The multiprocessing package offers both local and remote concurrency, effectively side-stepping the Global Interpreter Lock by using subprocesses in
docs.python.org
import multiprocessing as mp
def delivery():
print('delivering...')
p = mp.Process(target=delivery, args=())
p.start()
# 사용 메서드
p = mp.Process(target=delivery, args=())
p.start() # 프로세스 시작
p.join() # 실제 종료까지 기다림 (필요시에만 사용)
p.terminate() # 프로세스 종료
스레드/프로세스 풀 사용하기
풀은 스레드나 프로세스로 가득찬 풀장과 같은 것
- Queue를 사용해 만드는 방법
queue — A synchronized queue class — Python 3.7.12 documentation
queue — A synchronized queue class Source code: Lib/queue.py The queue module implements multi-producer, multi-consumer queues. It is especially useful in threaded programming when information must be exchanged safely between multiple threads. The Queue
docs.python.org
- concurrent.futures 라이브러리 ThreadPoolExecutor, ProcessPoolExecutor 클래스 사용하기
concurrent.futures 모듈
- Executor
- ThreadPoolExecutor
- ProcessPoolExecutor
- Future
ThreadPoolExecutor
with 컨텍스트 관리자와 같은방법으로 멀티프로세스 또한 같은 방법으로 사용 가능
from concurrent.futures import ThreadPoolExecutor
class Delivery:
def run(self):
print("delivering")
w = Delivery()
with ThreadPoolExecutor() as executor:
future = executor.submit(w.run)
#result
delivering
multiprocessing.Pool
multiprocessing.Pool.map을 통해 프로세스에 특정 함수를 매핑해서 병렬처리 구현하는 방법
from multiprocessing import Pool
from os import getpid
def double(i):
print("I'm processing ", getpid()) # pool 안에서 이 메소드가 실행될 때 pid를 확인해 봅시다.
return i * 2
with Pool() as pool:
result = pool.map(double, [1, 2, 3, 4, 5])
print(result)
#result
I'm processing 134
I'm processing 135
I'm processing 134
I'm processing 135
I'm processing 134
[2, 4, 6, 8, 10]
futures 모듈
concurrent.futures — 병렬 작업 실행하기 — Python 3.7.12 문서
소스 코드: Lib/concurrent/futures/thread.py와 Lib/concurrent/futures/process.py concurrent.futures 모듈은 비동기적으로 콜러블을 실행하는 고수준 인터페이스를 제공합니다. 비동기 실행은 (ThreadPoolExecutor를 사용
docs.python.org
import math
import concurrent
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()소수판별함수를 구성하는 예제로
프로파일링 위한 시간 계산, 단일처리와 단일처리 프로파일링을 위한 시간 계산 코드 추가
import time
def main():
print("병렬처리 시작")
start = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
end = time.time()
print("병렬처리 수행 시각", end-start, 's')
print("단일처리 시작")
start = time.time()
for number, prime in zip(PRIMES, map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
end = time.time()
print("단일처리 수행 시각", end-start, 's')
#result
병렬처리 시작
112272535095293 is prime: True
112582705942171 is prime: True
112272535095293 is prime: True
115280095190773 is prime: True
115797848077099 is prime: True
1099726899285419 is prime: False
병렬처리 수행 시각 1.9609129428863525 s
단일처리 시작
do Overwork
112272535095293 is prime: True
112582705942171 is prime: True
112272535095293 is prime: True
115280095190773 is prime: True
115797848077099 is prime: True
1099726899285419 is prime: False
단일처리 수행 시각 2.851389169692993 s
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| -41일차- 뉴스기사 크롤링과 분류 (0) | 2022.02.25 |
|---|---|
| -40일차- OCR(Optical Character Recognition) (0) | 2022.02.24 |
| -38일차- 추천 시스템 활용 (0) | 2022.02.22 |
| -37일차- 추천시스템 (0) | 2022.02.21 |
| -35일차- QnA 봇 만들기 (0) | 2022.02.17 |