
Activation function
모델의 표현력을 향상시켜주는 활성화 함수
f(x)=xw1+b1 이러한 식이 있을 때 , x^5, sin(x) 등으로 표현되는 데이터를 학습할 수가 없음
수학적으로 말하면 선형함수(직선)는 비선형함수(곡선)을 표현할 수 없음여기에서 딥러닝 모델의 parameter(w,b)들은 입력값 x와 선형관계 이므로 비선형 데이터를 표현하기 위해딥러닝 모델도 비선형성을 지니고 있어야 하는데 이떄 쓰이는 것이 활성화 함수
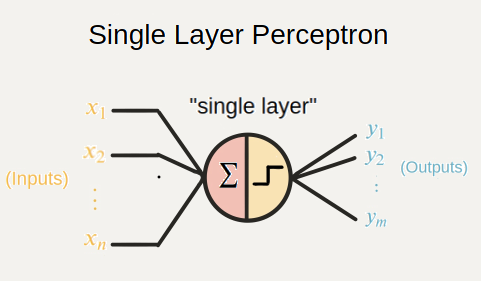
퍼셉트론
이미 잘짜인 머신이라 할 수 있는 동물의 학습 방법의 모방.동물의 신경세포와 유사하게 설계해 나온 것이 최초의 퍼셉트론
History of the Perceptron
Threshold Step Sigmoid Piecewise Linear Gaussian
home.csulb.edu
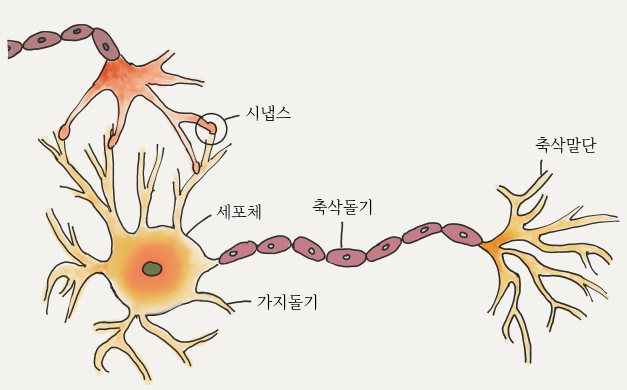
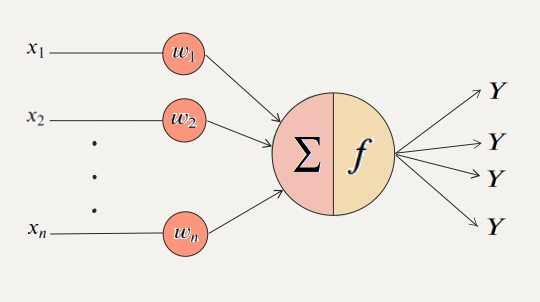
이 간단한 모델이 복잡한 신경세포와 동일하게 작동되는 것은 아니지만, 퍼셉트론을 다양한 구조로 연결하고
가중치와 편향값을 적절히 조정해주는 과정이 학습이며, 학습을 통해 기계는 동물과 비슷한 일을 처리함
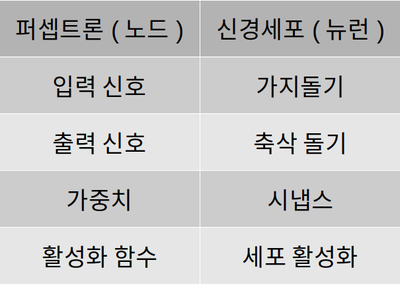
활성화함수는 신경세포의 세포체의 역할을 하며, 들어온 신호가 임계점을 넘으면 출력하고, 넘지 못하면 무시함
선형
선형 변환이란 선형이라는 규칙을 지키며 V 공간상의 벡터를 W 공간상의 벡터로 바꾸는 역할
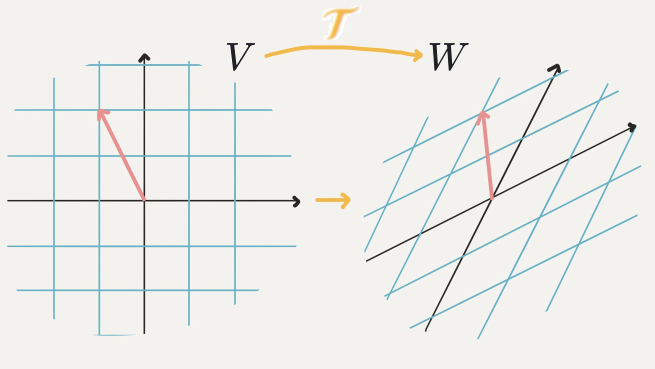
선형 변환의 정의
V와 W가 벡터공간이고, 둘 모두 실수집합상에 있을때, 함수 T : V - W가 다음 두 조건을 만족
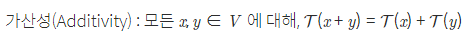

이때 함수 T는 선형변환(linear transformation), T는 선형이다라고 하기도 함
T가 선형일때 가지는 성질


비선형
선형이 아닌 함수
비선형 표현이 왜 필요한지에 대한 설명
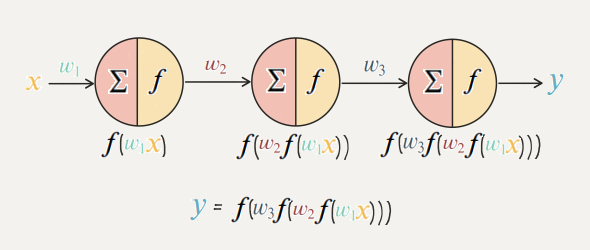

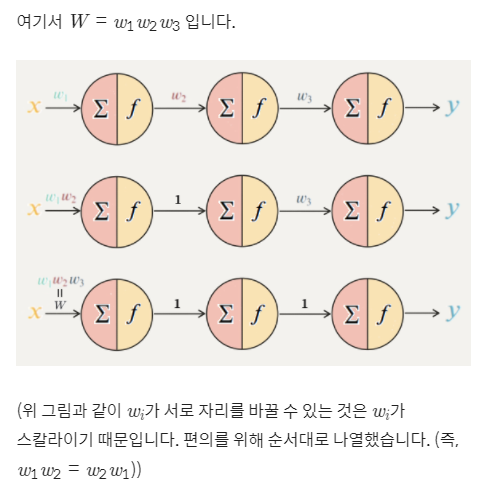

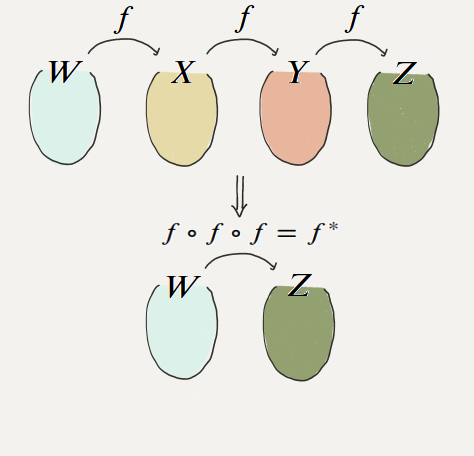
선형 변환의 합성함수에 관한 정리

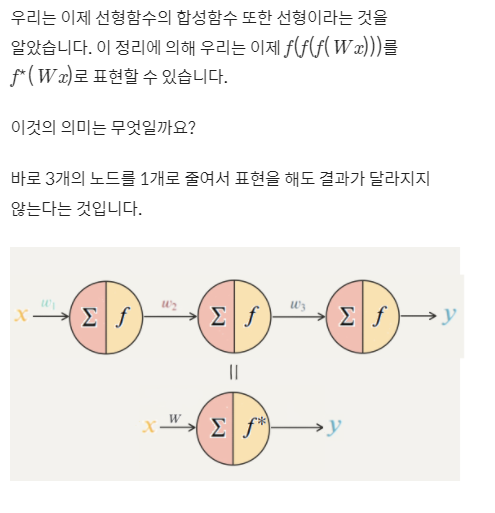
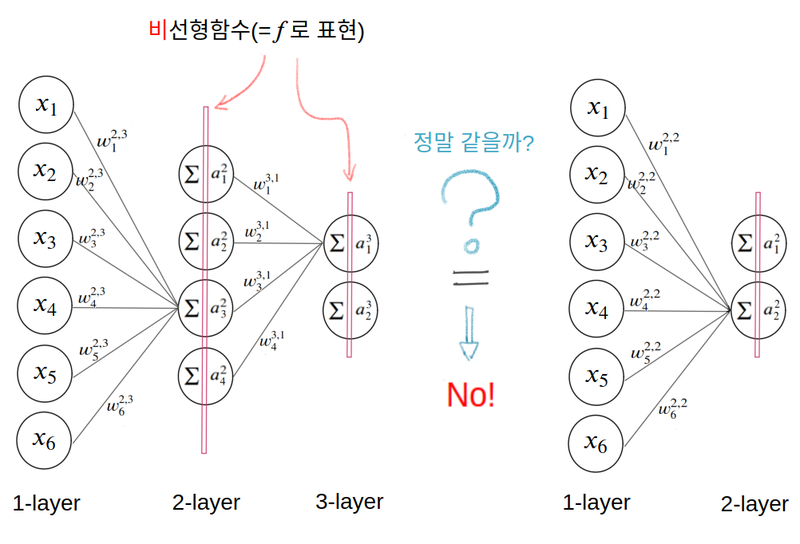
결국 선형 활성화 함수만 사용한다면 노드의 개수를 많이 붙여도 하나의 노드를 사용하는 것과 동일
활성화 함수가 선형일 때 모델의 표현력은 증가하지 않음
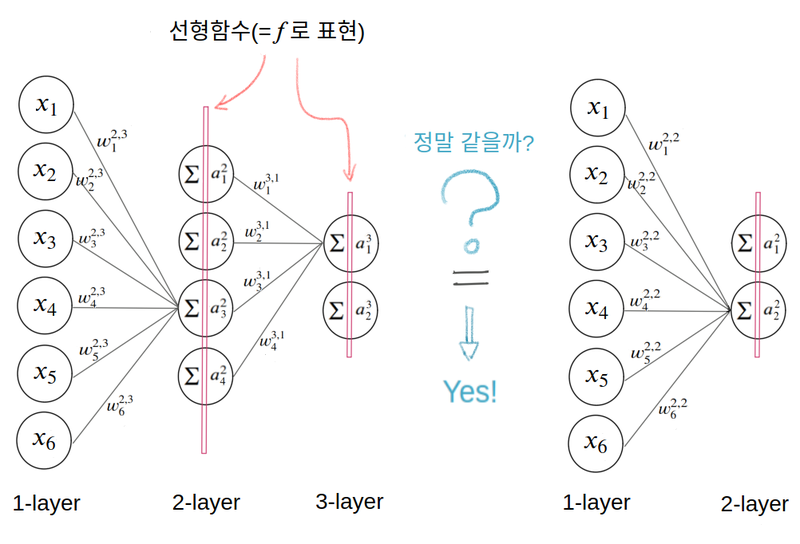
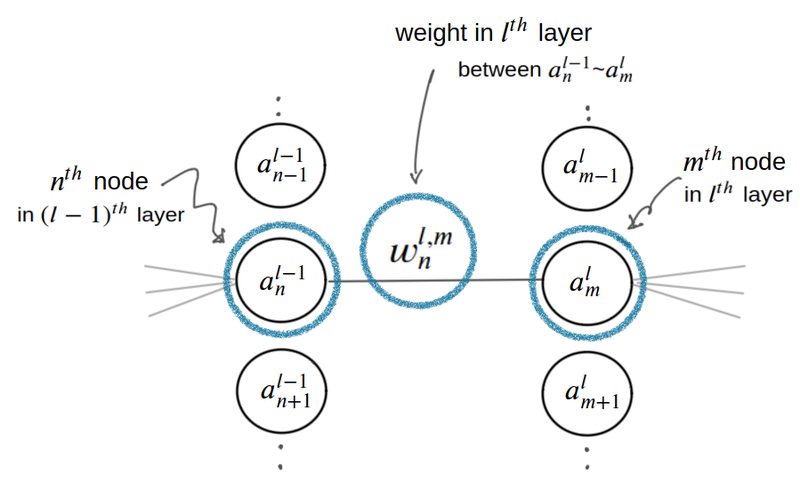


오른쪽 레이어에 대한 계산


비선형함수를 사용할 경우
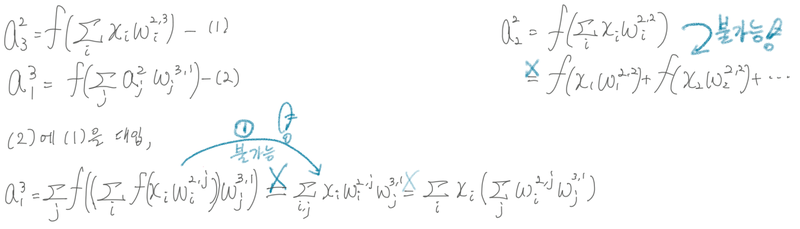
활성화 함수의 종류
이진 계단 함수 예제
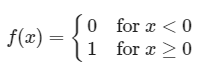
def binary_step(x, threshold=0):
return 0 if x<threshold else 1
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
def plot_and_visulize(image_url, function, derivative=False):
X = [-10 + x/100 for x in range(2000)]
y = [function(y) for y in X]
plt.figure(figsize=(12,12))
# 함수 그래프
plt.subplot(3,2,1)
plt.title('function')
plt.plot(X,y)
# 함수의 미분 그래프
plt.subplot(3,2,2)
plt.title('derivative')
if derivative:
dev_y = [derivative(y) for y in X]
plt.plot(X,dev_y)
# 무작위 샘플들 분포
samples = np.random.rand(1000)
samples -= np.mean(samples)
plt.subplot(3,2,3)
plt.title('samples')
plt.hist(samples,100)
# 활성화 함수를 통과한 샘플들 분포
act_values = [function(y) for y in samples]
plt.subplot(3,2,4)
plt.title('activation values')
plt.hist(act_values,100)
# 원본 이미지
image = np.array(Image.open(image_url), dtype=np.float64)[:,:,0]/255. # 구분을 위해 gray-scale해서 확인
image -= np.median(image)
plt.subplot(3,2,5)
plt.title('origin image')
plt.imshow(image, cmap='gray')
# 활성화 함수를 통과한 이미지
activation_image = np.zeros(image.shape)
h, w = image.shape
for i in range(w):
for j in range(h):
activation_image[j][i] += function(image[j][i])
plt.subplot(3,2,6)
plt.title('activation results')
plt.imshow(activation_image, cmap='gray')
return plt
import os
img_path = os.getenv('HOME')+'/aiffel/activation/jindo_dog.jpg'
ax = plot_and_visulize(img_path, binary_step)
ax.show()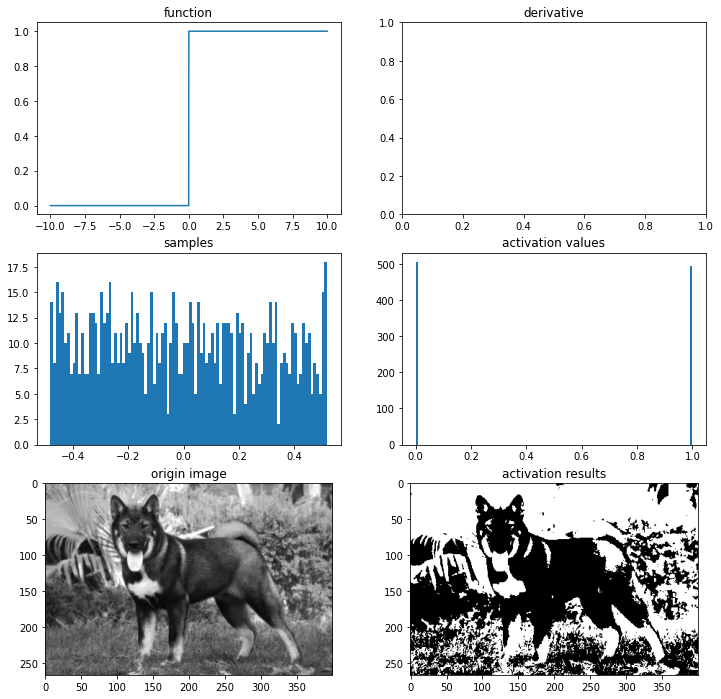
초기의 신경망에서 자주 사용됨
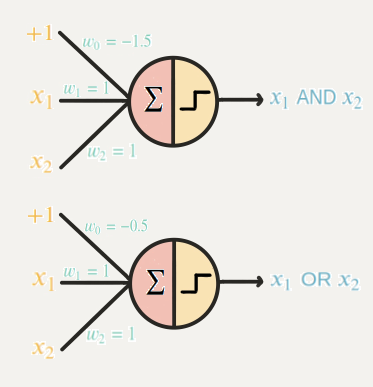
# 퍼셉트론
class Perceptron(object):
def __init__(self, input_size, activation_ftn, threshold=0, learning_rate=0.01):
self.weights = np.random.randn(input_size)
self.bias = np.random.randn(1)
self.activation_ftn = np.vectorize(activation_ftn)
self.learning_rate = learning_rate
self.threshold = threshold
def train(self, training_inputs, labels, epochs=100, verbose=1):
'''
verbose : 1-매 에포크 결과 출력,
0-마지막 결과만 출력
'''
for epoch in range(epochs):
for inputs, label in zip(training_inputs, labels):
prediction = self.__call__(inputs)
self.weights += self.learning_rate * (label - prediction) * inputs
self.bias += self.learning_rate * (label - prediction)
if verbose == 1:
pred = self.__call__(training_inputs)
accuracy = np.sum(pred==labels)/len(pred)
print(f'{epoch}th epoch, accuracy : {accuracy}')
if verbose == 0:
pred = self.__call__(training_inputs)
accuracy = np.sum(pred==labels)/len(pred)
print(f'{epoch}th epoch, accuracy : {accuracy}')
def get_weights(self):
return self.weights, self.bias
def __call__(self, inputs):
summation = np.dot(inputs, self.weights) + self.bias
return self.activation_ftn(summation, self.threshold)
def scatter_plot(plt, X, y, threshold = 0, three_d=False):
ax = plt
if not three_d:
area1 = np.ma.masked_where(y <= threshold, y)
area2 = np.ma.masked_where(y > threshold, y+1)
ax.scatter(X[:,0], X[:,1], s = area1*10, label='True')
ax.scatter(X[:,0], X[:,1], s = area2*10, label='False')
ax.legend()
else:
area1 = np.ma.masked_where(y <= threshold, y)
area2 = np.ma.masked_where(y > threshold, y+1)
ax.scatter(X[:,0], X[:,1], y-threshold, s = area1, label='True')
ax.scatter(X[:,0], X[:,1], y-threshold, s = area2, label='False')
ax.scatter(X[:,0], X[:,1], 0, s = 0.05, label='zero', c='gray')
ax.legend()
return ax
# AND gate, OR gate
X = np.array([[0,0], [1,0], [0,1], [1,1]])
plt.figure(figsize=(10,5))
# OR gate
or_y = np.array([x1 | x2 for x1,x2 in X])
ax1 = plt.subplot(1,2,1)
ax1.set_title('OR gate ' + str(or_y))
ax1 = scatter_plot(ax1, X, or_y)
# AND gate
and_y = np.array([x1 & x2 for x1,x2 in X])
ax2 = plt.subplot(1,2,2)
ax2.set_title('AND gate ' + str(and_y))
ax2 = scatter_plot(ax2, X, and_y)
plt.show()
이진계단 함수의 임계점이 0일때 위 gate들은 단층 퍼셉트론으로 구현가능
# OR gate
or_p = Perceptron(input_size=2, activation_ftn=binary_step)
or_p.train(X, or_y, epochs=1000, verbose=0)
print(or_p.get_weights()) # 가중치와 편향값은 훈련마다 달라질 수 있습니다.
# AND gate
and_p = Perceptron(input_size=2, activation_ftn=binary_step)
and_p.train(X, and_y, epochs=1000, verbose=0)
print(and_p.get_weights()) # 가중치와 편향값은 훈련마다 달라질 수 있습니다.
#result
999th epoch, accuracy : 1.0
(array([0.01336009, 1.14617223]), array([-0.00692935]))
999th epoch, accuracy : 1.0
(array([0.10808756, 0.76883274]), array([-0.78157952]))
from itertools import product
# 그래프로 그려보기
test_X = np.array([[x/100,y/100] for (x,y) in product(range(101),range(101))])
pred_or_y = or_p(test_X)
pred_and_y = and_p(test_X)
plt.figure(figsize=(10,10))
ax1 = plt.subplot(2,2,1)
ax1.set_title('predict OR gate')
ax1 = scatter_plot(ax1, test_X, pred_or_y)
ax2 = plt.subplot(2,2,2, projection='3d')
ax2.set_title('predict OR gate 3D')
ax2 = scatter_plot(ax2, test_X, pred_or_y, three_d=True)
ax3 = plt.subplot(2,2,3)
ax3.set_title('predict AND gate')
ax3 = scatter_plot(ax3, test_X, pred_and_y)
ax4 = plt.subplot(2,2,4, projection='3d')
ax4.set_title('predict AND gate 3D')
ax4 = scatter_plot(ax4, test_X, pred_and_y, three_d=True)
plt.show()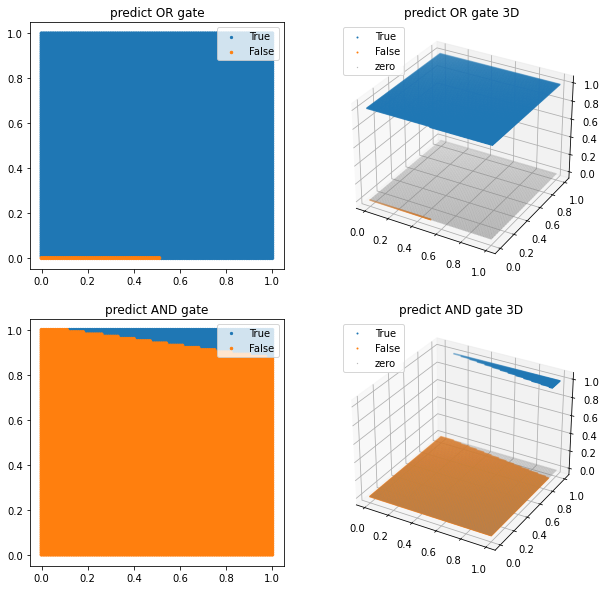
단층 퍼셉트론 모델의 추론결과, 4개의 점으로 표현되었던 것에 비해 아래에는 x와 y축을 100등분한 결과를
모델에 대입해서 True와 False의 경계선이 선형적으로 드러나도록 그려짐
이진 계단 함수의 한계
1) XOR gate 구현이 불가
# XOR gate
threshold = 0
X = np.array([[0,0], [1,0], [0,1], [1,1]])
plt.figure(figsize=(5,5))
xor_y = np.array([x1 ^ x2 for x1,x2 in X])
plt.title('XOR gate '+ str(xor_y))
plt = scatter_plot(plt, X, xor_y)
plt.show()
# XOR gate가 풀릴까?
xor_p = Perceptron(input_size=2, activation_ftn=binary_step, threshold=threshold)
xor_p.train(X, xor_y, epochs=1000, verbose=0)
print(xor_p.get_weights())
# 그래프로 그려보기
test_X = np.array([[x/100,y/100] for (x,y) in product(range(101),range(101))])
pred_xor_y = xor_p(test_X)
plt.figure(figsize=(10,5))
ax1 = plt.subplot(1,2,1)
ax1.set_title('predict XOR gate?')
ax1 = scatter_plot(ax1, test_X, pred_xor_y)
ax2 = plt.subplot(1,2,2, projection='3d')
ax2.set_title('predict XOR gate 3D?')
ax2 = scatter_plot(ax2, test_X, pred_xor_y, three_d=True)
plt.show()
#result
999th epoch, accuracy : 0.25
(array([-0.01605413, -0.01319012]), array([0.00888562]))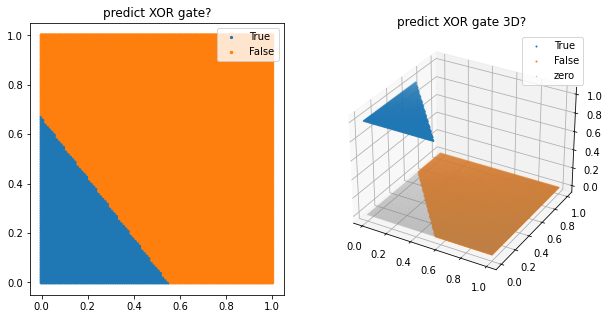
이를 해결하기위해 다층 퍼셉트론을 활용
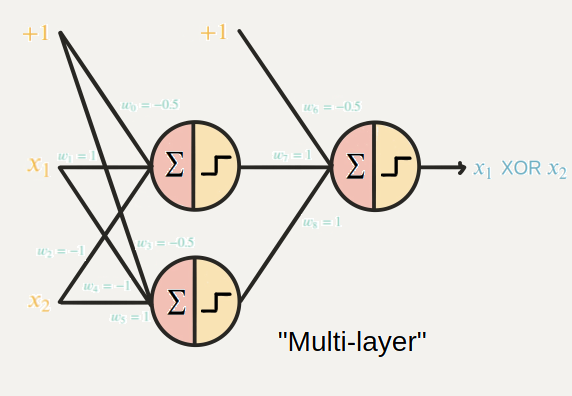
2) 역전파 알고리즘 사용 불가
0은 미분이 안될뿐더러 0인 부분 제외하고 미분해도 미분값이 0이 나오므로, 가중치가 업데이트 되지 않음
이는 비효율적인 업데이트 방법을 사용해야한다는 뜻
선형 활성화 함수
이진 계단 함수와 다르게 다중 출력이 가능
import os
img_path = os.getenv('HOME')+'/aiffel/activation/jindo_dog.jpg'
# 선형 함수
def linear(x):
return x
def dev_linear(x):
return 1
# 시각화
ax = plot_and_visulize(img_path, linear, dev_linear)
ax.show()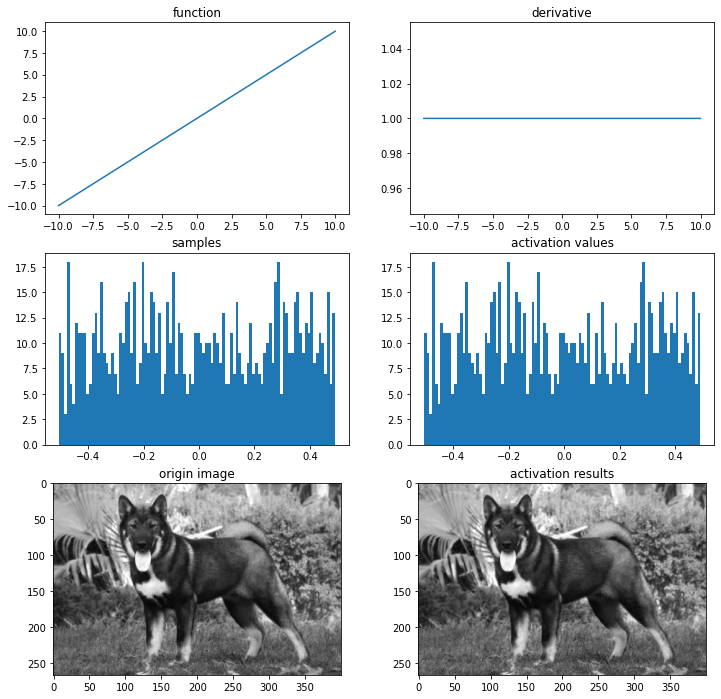
선형 활성화 함수 모델은 선형적으로 구분 가능한 문제를 해결 가능
# AND gate, OR gate
threshold = 0
X = np.array([[0,0], [1,0], [0,1], [1,1]])
plt.figure(figsize=(10,5))
# OR gate
or_y = np.array([x1 | x2 for x1,x2 in X])
ax1 = plt.subplot(1,2,1)
ax1.set_title('OR gate ' + str(or_y))
ax1 = scatter_plot(ax1, X, or_y)
# AND gate
and_y = np.array([x1 & x2 for x1,x2 in X])
ax2 = plt.subplot(1,2,2)
ax2.set_title('AND gate ' + str(and_y))
ax2 = scatter_plot(ax2, X, and_y)
plt.show()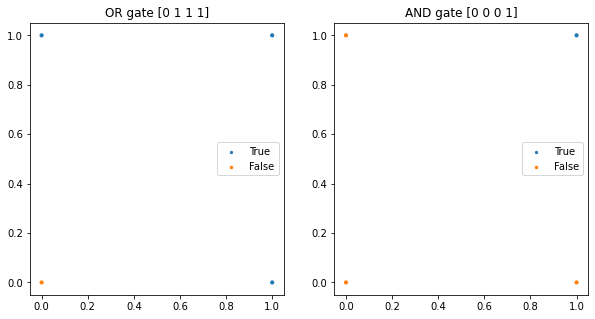
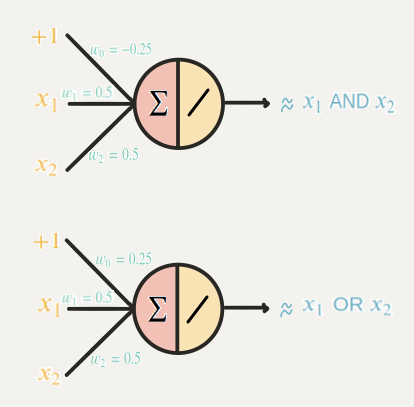
선형 활성화 함수를 사용한 단층 퍼셉트론을 이용, gate 구현
import tensorflow as tf
# OR gate model
or_linear_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(2,), dtype='float64'),
tf.keras.layers.Dense(1, activation='linear')
])
or_linear_model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), metrics=['accuracy'])
or_linear_model.summary()
# AND gate model
and_linear_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(2,), dtype='float64'),
tf.keras.layers.Dense(1, activation='linear')
])
and_linear_model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), metrics=['accuracy'])
and_linear_model.summary()
or_linear_model.fit(X, or_y, epochs=1000, verbose=0)
and_linear_model.fit(X, and_y, epochs=1000, verbose=0)
# 그래프로 그려보기
test_X = np.array([[x/100,y/100] for (x,y) in product(range(101),range(101))])
pred_or_y = or_linear_model(test_X)
pred_and_y = and_linear_model(test_X)
plt.figure(figsize=(10,10))
ax1 = plt.subplot(2,2,1)
ax1.set_title('predict OR gate')
ax1 = scatter_plot(ax1, test_X, pred_or_y, threshold=0.5)
ax2 = plt.subplot(2,2,2, projection='3d')
ax2.set_title('predict OR gate 3D')
ax2 = scatter_plot(ax2, test_X, pred_or_y, threshold=0.5, three_d=True)
ax3 = plt.subplot(2,2,3)
ax3.set_title('predict AND gate')
ax3 = scatter_plot(ax3, test_X, pred_and_y, threshold=0.5)
ax4 = plt.subplot(2,2,4, projection='3d')
ax4.set_title('predict AND gate 3D')
ax4 = scatter_plot(ax4, test_X, pred_and_y, threshold=0.5, three_d=True)
plt.show()
XOR gate가 구현이 가능한지 확인
# XOR gate
xor_linear_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(2,), dtype='float64'),
tf.keras.layers.Dense(1, activation='linear')
])
xor_linear_model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), metrics=['accuracy'])
xor_linear_model.fit(X, xor_y, epochs=1000, verbose=0)
# 그래프로 그려보기
test_X = np.array([[x/100,y/100] for (x,y) in product(range(101),range(101))])
pred_xor_y = xor_linear_model(test_X)
plt.figure(figsize=(10,5))
ax1 = plt.subplot(1,2,1)
ax1.set_title('predict XOR gate')
ax1 = scatter_plot(ax1, test_X, pred_xor_y, threshold=0.5)
ax2 = plt.subplot(1,2,2, projection='3d')
ax2.set_title('predict XOR gate 3D')
ax2 = scatter_plot(ax2, test_X, pred_xor_y, threshold=0.5, three_d=True)
plt.show()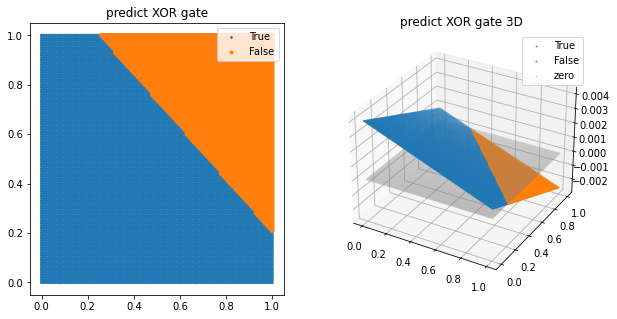
선 하나로 나눌 수 없음
비선형 활성화 함수
시그모이드 / 로지스틱

import os
img_path = os.getenv('HOME')+'/aiffel/activation/jindo_dog.jpg'
# 시그모이드 함수
def sigmoid(x):
return 1/(1+np.exp(-x).astype(np.float64))
def dev_sigmoid(x):
return sigmoid(x)*(1-sigmoid(x))
# 시각화
ax = plot_and_visulize(img_path, sigmoid, dev_sigmoid)
ax.show()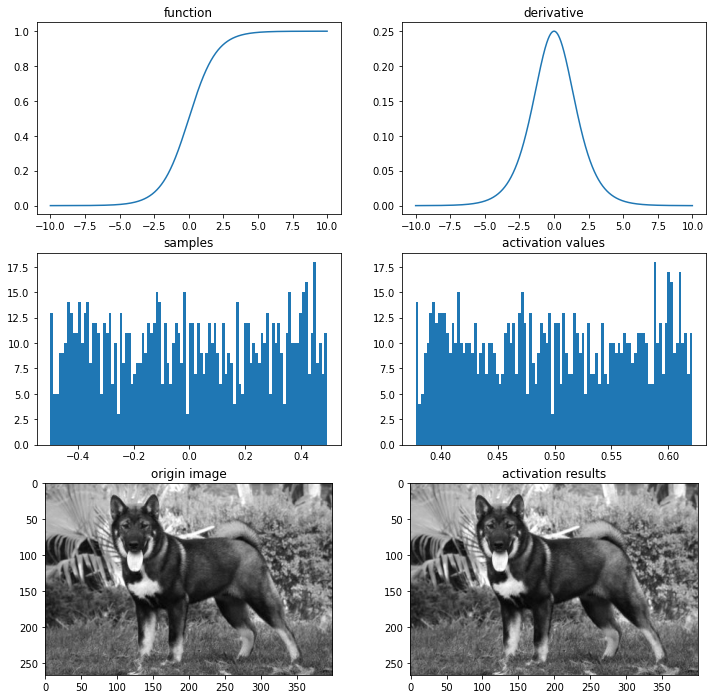

# 수치 미분
def num_derivative(x, function):
h = 1e-15 # 이 값을 바꾸어 가며 그래프를 확인해 보세요
numerator = function(x+h)-function(x)
return numerator/h
# 두 그래프의 차이
diff_X = [-5+x/100 for x in range(1001)]
dev_y = np.array([dev_sigmoid(x) for x in diff_X])
num_dev_y = np.array([num_derivative(x, sigmoid) for x in diff_X])
diff_y = dev_y - num_dev_y
plt.plot(diff_X, num_dev_y, label='numerical')
plt.plot(diff_X, dev_y, label='analytic')
plt.plot(diff_X, diff_y, label='differnce')
plt.legend()
plt.show()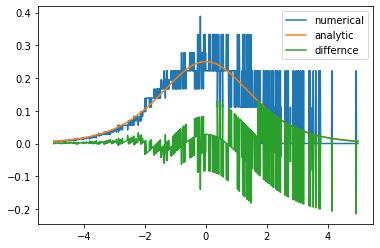
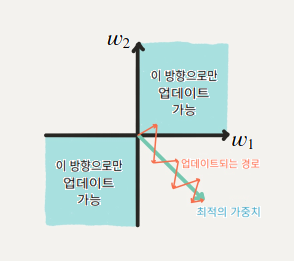
시그모이드 함수의 단점
1.시그모이드 함수는 0또는 1에서 포화가 됨(saturate)
이는 그래디언트가 0과 가까워 지게됨
역전파에서 0과 가까워진 그래디언트는 0에 근접하게되어 가중치 업데이트가 일어나지 않음
2.시그모이드 함수의 출력은 0이 중심이 아님
이로 말미암아 훈련의 시간이 오래 걸리게 됨

# OR gate
or_sigmoid_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(2,)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
or_sigmoid_model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), metrics=['accuracy'])
or_sigmoid_model.fit(X, or_y, epochs=1000, verbose=0)
# AND gate
and_sigmoid_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(2,)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
and_sigmoid_model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), metrics=['accuracy'])
and_sigmoid_model.fit(X, and_y, epochs=1000, verbose=0)
# XOR gate
xor_sigmoid_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(2,)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
xor_sigmoid_model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), metrics=['accuracy'])
xor_sigmoid_model.fit(X, xor_y, epochs=1000, verbose=0)
# 그래프로 그려보기
test_X = np.array([[x/100,y/100] for (x,y) in product(range(101),range(101))])
pred_or_y = or_sigmoid_model(test_X)
pred_and_y = and_sigmoid_model(test_X)
pred_xor_y = xor_sigmoid_model(test_X)
plt.figure(figsize=(10,15))
ax1 = plt.subplot(3,2,1)
ax1.set_title('predict OR gate')
ax1 = scatter_plot(ax1, test_X, pred_or_y, threshold=0.5)
ax2 = plt.subplot(3,2,2, projection='3d')
ax2.set_title('predict OR gate 3D')
ax2 = scatter_plot(ax2, test_X, pred_or_y, threshold=0.5, three_d=True)
ax3 = plt.subplot(3,2,3)
ax3.set_title('predict AND gate')
ax3 = scatter_plot(ax3, test_X, pred_and_y, threshold=0.5)
ax4 = plt.subplot(3,2,4, projection='3d')
ax4.set_title('predict AND gate 3D')
ax4 = scatter_plot(ax4, test_X, pred_and_y, threshold=0.5, three_d=True)
ax5 = plt.subplot(3,2,5)
ax5.set_title('predict XOR gate')
ax5 = scatter_plot(ax5, test_X, pred_xor_y, threshold=0.5)
ax6 = plt.subplot(3,2,6, projection='3d')
ax6.set_title('predict XOR gate 3D')
ax6 = scatter_plot(ax6, test_X, pred_xor_y, threshold=0.5, three_d=True)
plt.show()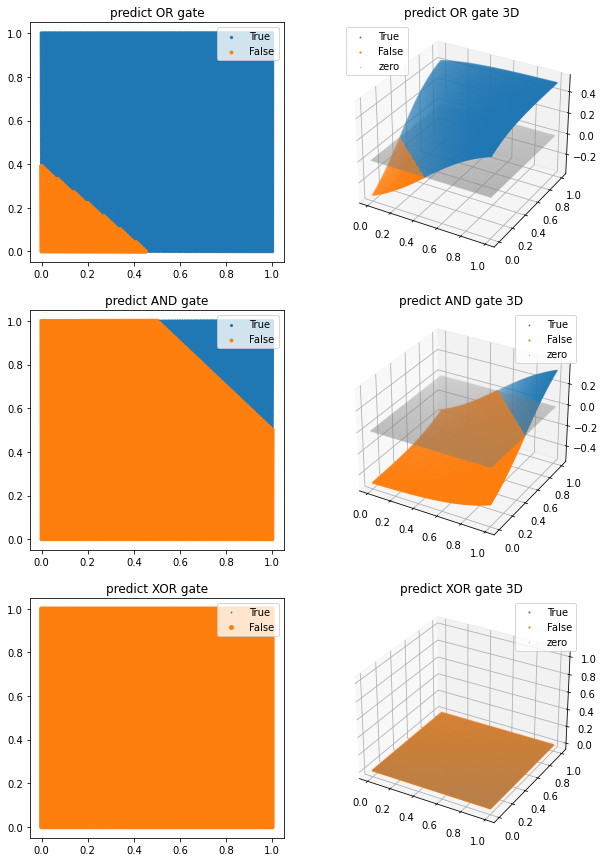
XOR gate가 제대로 구현되지 않음
Solving XOR with a single Perceptron
Advocating for polynomial transformations as a way to increase the representational power of artificial neurons.
medium.com
2차 다항식을 추가한 시그모이드 함수의 사용
# 레이어를 추가했을 때
# XOR gate
xor_sigmoid_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(2,)),
tf.keras.layers.Dense(2, activation='sigmoid'), # 2 nodes로 변경
tf.keras.layers.Dense(1)
])
xor_sigmoid_model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), metrics=['accuracy'])
xor_sigmoid_model.fit(X, xor_y, epochs=1000, verbose=0)
plt.figure(figsize=(10,5))
pred_xor_y = xor_sigmoid_model(test_X)
ax1 = plt.subplot(1,2,1)
ax1.set_title('predict XOR gate')
ax1 = scatter_plot(ax1, test_X, pred_xor_y, threshold=0.5)
ax2 = plt.subplot(1,2,2, projection='3d')
ax2.set_title('predict XOR gate 3D')
ax2 = scatter_plot(ax2, test_X, pred_xor_y, threshold=0.5, three_d=True)
plt.show()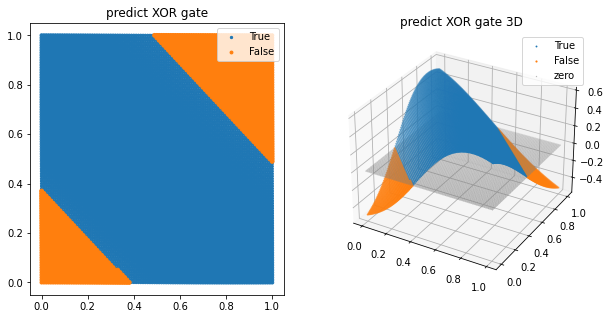
Softmax
시그모이드는 Binary classification 참과 거짓을 분류할때 쓰이는 반면
softmax는 10가지, 100가지 class등 각 class의 확률을 구할 때 쓰임
모든 클래스의 확률을 더하면 1이 됨
하이퍼볼릭 탄젠트
쌍곡선 함수 중 하나
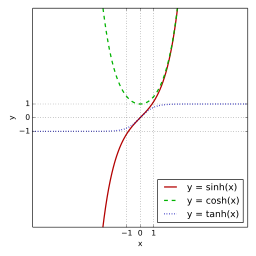
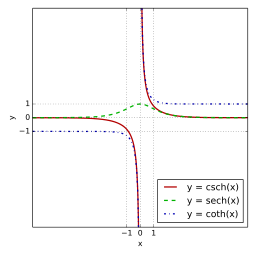
하이퍼볼릭 탄젠트 함수의 표시
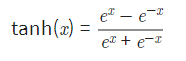
하이퍼볼릭 탄젠트 함수의 치역은 (-1,1), 즉, -1<sigma(x)<1
하이퍼볼릭 탄젠트 함수는 0을 중심으로 설정
하이퍼볼릭 탄젠트 함수를 시그모이드 함수를 이용한 표현
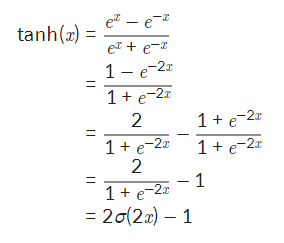
하이퍼볼릭 탄젠트 함수의 미분
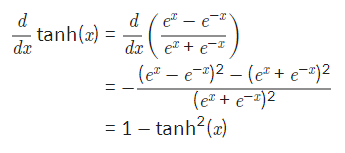
import os
img_path = os.getenv('HOME')+'/aiffel/activation/jindo_dog.jpg'
# 하이퍼볼릭 탄젠트 함수
def tanh(x):
return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
def dev_tanh(x):
return 1-tanh(x)**2
# 시각화
ax = plot_and_visulize(img_path, tanh, dev_tanh)
ax.show()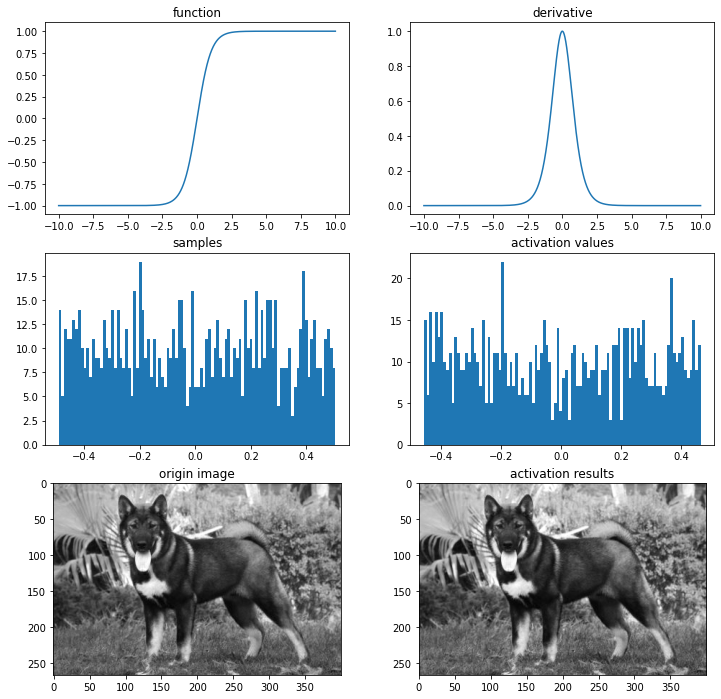
하이퍼볼릭 탄젠트 함수의 단점
-1과 1에서 포화
ReLU
ReLU(rectified linear unit)함수는 최근 가장 많이 사용되는 활성화 함수
f(x)=max(0,x)
import os
img_path = os.getenv('HOME')+'/aiffel/activation/jindo_dog.jpg'
# relu 함수
def relu(x):
return max(0,x)
# 시각화
ax = plot_and_visulize(img_path, relu)
ax.show()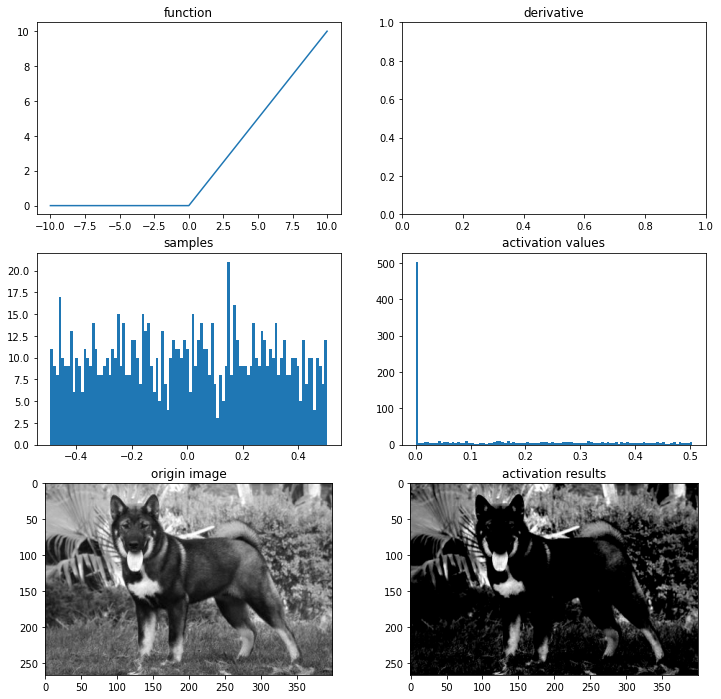
렐루 함수의 치역은
하이퍼볼릭 탄젠트 함수에 비해 7배정도 빠르게 에러비율이 감소하며, 연산 비용이 훨씬 적고, 처리속도가 빠름
0을 제외한 구간에서 미분이 가능

0에서 미분이 안되는 이유


ReLU 함수는 곡선이 아닌데 비선형적인 데이터의 특징을 잡아낼 수 있을까?
수학적인 증명
ReLU Deep Neural Networks and Linear Finite Elements
In this paper, we investigate the relationship between deep neural networks (DNN) with rectified linear unit (ReLU) function as the activation function and continuous piecewise linear (CPWL) functions, especially CPWL functions from the simplicial linear f
arxiv.org
q_X = np.array([-10+x/100 for x in range(2001)])
q_y = np.array([(x)**2 + np.random.randn(1)*10 for x in q_X])
plt.scatter(q_X, q_y, s=0.5)
approx_relu_model_p = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1,)),
tf.keras.layers.Dense(6, activation='relu'), # 6 nodes 병렬 연결
tf.keras.layers.Dense(1)
])
approx_relu_model_p.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=0.005), metrics=['accuracy'])
approx_relu_model_p.fit(q_X, q_y, batch_size=32, epochs=100, verbose=0)
approx_relu_model_s = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1,)),
tf.keras.layers.Dense(2, activation='relu'),# 2 nodes 직렬로 3번 연결
tf.keras.layers.Dense(2, activation='relu'),
tf.keras.layers.Dense(2, activation='relu'),
tf.keras.layers.Dense(1)
])
approx_relu_model_s.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(learning_rate=0.005), metrics=['accuracy'])
approx_relu_model_s.fit(q_X, q_y, batch_size=32, epochs=100, verbose=0)
approx_relu_model_p.summary()
approx_relu_model_s.summary()
q_test_X = q_X.reshape((*q_X.shape,1))
plt.figure(figsize=(10,5))
ax1 = plt.subplot(1,2,1)
ax1.set_title('parallel')
pred_y_p = approx_relu_model_p(q_test_X)
ax1.plot(q_X, pred_y_p)
ax2 = plt.subplot(1,2,2)
ax2.set_title('serial')
pred_y_s = approx_relu_model_s(q_test_X)
ax2.plot(q_X, pred_y_s)
plt.show()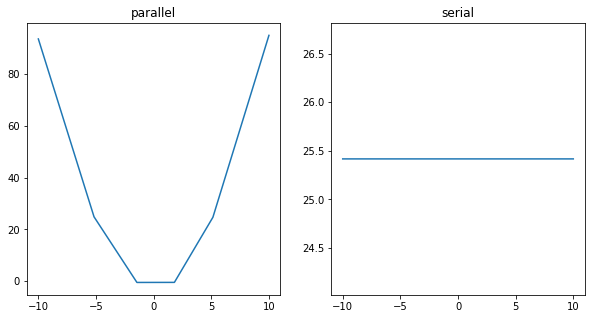
충분히 비선형적 데이터를 예측할 수 있으며, 파라미터 수가 같더라도 병렬로 연결된 노드가 훨씬 좋은 효과를 가짐
ReLU 함수의 단점
출력값이 0이 중심이 아닌점
Dying ReLU 현상

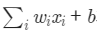
해당값이 가중치 w값에 의해 입력값 x에 상관없이 0 이하로 나오게 되면 그래디언트가 0
학습률을 크게 잡을 때 자주 발생하므로 학습률을 줄여준다면 문제가 덜 발생함
Leaky ReLU
ReLU함수의 Dying ReLU를 해결하기 위한 시도
f(x)=max(0.01x,x)
import os
img_path = os.getenv('HOME')+'/aiffel/activation/jindo_dog.jpg'
# leaky relu 함수
def leaky_relu(x):
return max(0.01*x,x)
# 시각화
ax = plot_and_visulize(img_path, leaky_relu)
ax.show()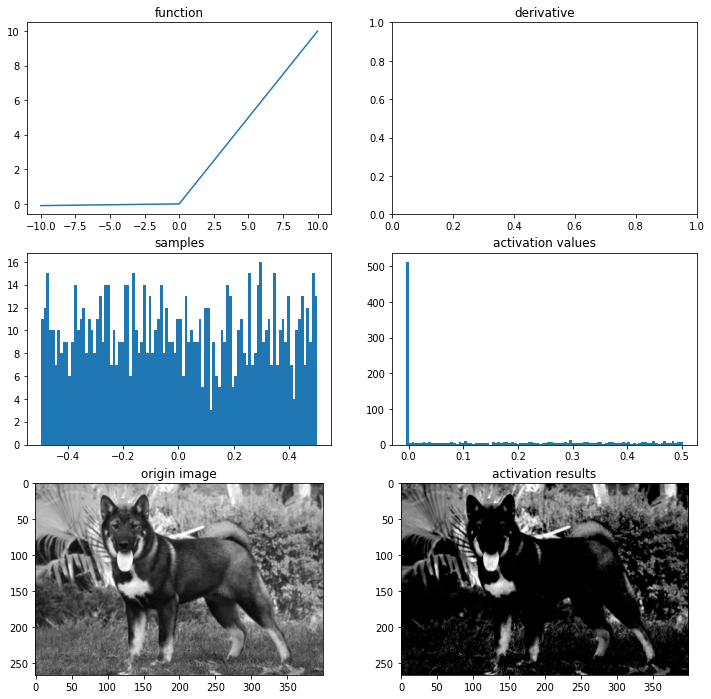
아주 작은 음수값의 추가
PReLU
Leaky ReLU와 유사하지만 새로운 파라미터를 추가하여 0미만일 때의 기울기가 훈련되게 추가
f(x)=max(αx,x)
# PReLU 함수
def prelu(x, alpha):
return max(alpha*x,x)
# 시각화
ax = plot_and_visulize(img_path, lambda x: prelu(x, 0.1)) # parameter alpha=0.1일 때
ax.show()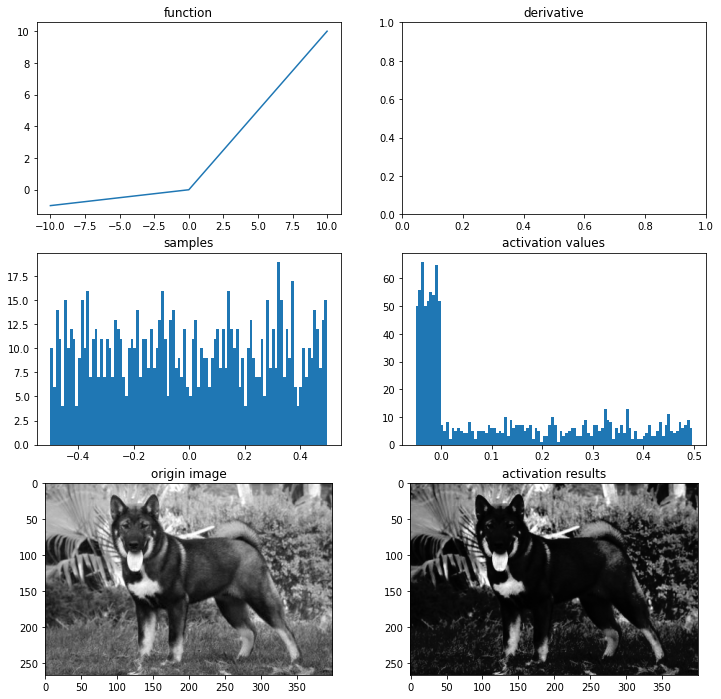
ELU
ReLU의 장점을 포함하며, 0이 중심점이 아니었던 단점, Dying ReLU 문제를 해결한 활성화 함수

# elu 함수
def elu(x, alpha):
return x if x > 0 else alpha*(np.exp(x)-1)
def dev_elu(x, alpha):
return 1 if x > 0 else elu(x, alpha) + alpha
# 시각화
ax = plot_and_visulize(img_path, lambda x: elu(x, 1), lambda x: dev_elu(x, 1)) # alpha가 1일 때
ax.show()
단점
exponential 연산이 들어가면서 계산 비용이 다소 높아짐
오늘 배운것들을 한방에 살펴보기
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| -34일차- Likelihood(MLE, MAP) (0) | 2022.02.16 |
|---|---|
| -33일차- 트랜스포머로 대화형 챗봇 만들기 (0) | 2022.02.15 |
| -31일차- 정규화와 정칙화 (0) | 2022.02.11 |
| -30일차- 시계열 예측 ARIMA (0) | 2022.02.10 |
| -29일차- 딥러닝 레이어 이해하기 2 (0) | 2022.02.09 |