
구조체
하나 이상의 변수를 그룹 지어서 새로운 자료형(복잡한 데이터 표현)을 정의하는 것
- 사용자 정의 자료형 - 사용자가 C언어의 기본 타입을 가지고 새롭게 정의할 수 있음
- 배열은 같은 타입의 변수 집합이지만 구조체는 다양한 타입의 변수 집합을 하나의 타입으로 나타낸 것
- 구조체의 구성 : 구조체의 멤버 / 멤버 변수
구조체 정의와 선언
struct 구조체이름
{
멤버변수1의 타입 멤버변수1의 이름;
멤버변수2의 타입 멤버변수2의 이름;
…………
};
struct 구조체이름
{
멤버변수1의 타입 멤버변수1의 이름;
멤버변수2의 타입 멤버변수2의 이름;
…………
} 구조체 변수 이름; //구조체 선언
구조체 멤버 접근
- 멤버 접근 연산자(.)를 사용하여 구조체에서 구조체 멤버로 접근할 수 있음
- 형식 : 구조체변수이름. 멤버변수이름
구조체 변수 초기화
- 멤버 연산자(.)와 중괄호({})를 사용하여 구조체 변ㅂ수를 초기화할 수 있음
- 형식 : 구조체변수이름 = {. 멤버변수1이름 = 초기값, .멤버변수2이름 = 초기값,...};
typedef문
어떠한 자료형 이름에 대해 새 이름을 부여하는 목적으로 사용
- 이미 존재하는 int, float 등과 같은 자료형을 사용자가 자유롭게 정의할 수 있음
- 구조체에 새로운 이름을 선언하면 매번 struct 키워드를 사용하지 않아도 됨
형식 : typedef struct 구조체 이름 구조체의 새로운 이름. 예 : typedef struct student STD;
#include <stdio.h>
typedef struct
{
char name[20];
int age;
int weight;
} STD;
int main(){
STD s1={"Hong gil dong", 30, 65};
STD s2={.name = "Lee sun sin", .age=45, .weight=60};
printf("첫 번째 학생의 이름은 %s이고, 나이는 %d이며, 몸무게는 %d입니다.\n",s1.name, s1.age, s1.weight);
printf("두 번째 학생의 이름은 %s이고, 나이는 %d이며, 몸무게는 %d입니다.\n",s2.name, s2.age, s2.weight);
return 0;
}
범용 리스트
유한개의 순서가 있는 노드 또는 리스트들로 구성된 집합
- S=(x1, x2, x3....xn) S = 리스트의 이름, n= 리스트의 길이, 원소 xi = 원자(노드) 또는 리스트
- 예) A=(a,(b,c) // 리스트의 길이 = 2, S=((a,b,c), d,(e,f),(),A), T=(A,A,A,A)
활용 예
- 다변수로 구성된 다항식의 표현 - A(x,y,z) = 4x^3 + 3x^2 + 2 + 5y + 7z^3
- 희소행렬
- 특정 PC에서 특정 Web browser를 사용한 기록
- tab별 기록, jump한 기록
용어
- 공백리스트(empty list, 0, nil) -> S=()
- 부분리스트(sublist) -> 임의의 주어진 리스트가 다른 리스트의 노드 또는 리스트
- 헤드(head) : 임의의 주어진 리스트에서 첫 번째에 있는 리스트를 말함
- n>=1인 경우 첫 번째 원소=X1 = head(S)
- 테일(tail) : 임의의 주어진 리스트에서 첫 번째 원소를 제외한 나머지 원소를 말함
- 리스트=(X2,...Xn) = tail(S)
- 순환 리스트(recursive list) : 임의의 주어진 리스트의 항목이 동일한 부분리스트인 경우를 말함
- C=(a,C) = 길이가 2인 순환리스트
- 두 번째 원소 C = 무한리스트(a, (a, (a,...)에 대응
반응형
범용 리스트의 응용 : 다항식/희소행렬
범용리스트로 다항식 표현
- aX^e 형식의 항들의 합으로 구성된 식을 말함

다항식의 ADT
ADT Polynominal
데이터
순서쌍 <ei
, ai
>의 집합으로 표현된 다항식 p(x)=a0xe0+a1xe1+…+anxen
,
ei=음이 아닌 정수
연산자 및 연산내용 //p, p1
, p2∈Polynominal, a∈Cofficient, e∈Exponent
Polynominal zeroP() //다항식 p(x)=0를 반환
Boolean isPzero(p) //다항식 p(x)=0이면 true, 그렇지 않으면 false를 반환
Cofficient coef(p, e) //<다항식 p에서 지수가 e인 항의 계수를 반환
Exponent maxExp(p) //다항식 p에서 최대 차수를 반환
Polynominal addTerm(p, a, e) //다항식 p에 지수가 e인 항이 없는 경우에
// 새로운 항 <e, a>를 추가
Polynominal delTerm(p, e) //다항식에서 지수가 e인 항 <e, a>를 삭제
Polynominal mult(p, a, e) //다항식 p의 모든 항에 axe항을 곱하는 연산
Polynominal addpoly(p1
, p2
) //두 다항식 p1과 p2 를 더하는 연산
Polynominal multpoly(p1
, p2
) //두 다항식 p1 과 p2 를 곱하는 연산
End Polynominal
다항식 리스트 표현
- 모든 항의 지수는 다르기 때문에 지수 내림차순으로 표현할 수 있음
- 각 항의 <지수와 계수> 쌍에 대한 선형 리스트로 표현
- A(x) = 4x^3 + 3x^2 + 2 -> p1 = (3,4,2,3,0,2)
1차원 배열을 이용한 표현
- 차수가 n인 다항식을 (n+1)개의 원소를 가지는 지수 내림차순 1차원 배열 표현할 경우
- 배열 색인 i -> 지수 (n-1)
- 배열 색인 i의 원소 -> 지수 (n-i)항의 계수 저장
- 지수의 항이 없는 원소는 0을 저장


2차원 배열을 이용한 표현
다항식의 계수가 0이 아닌 항만 표현
- 다항식의 각 항에 대한 <지수, 계수>의 쌍을 2차원 배열에 저장
- 2차원 배열의 행의 개수 = 다항식의 항의 개수
- 2차원 배열의 열의 개수 = 2(지수, 계수)

지수내림차순(1차원 배열 이용)과 <지수, 계수>의 쌍 표현 방법 비교
- 좋지 못한 경우 -> degree < (0이 아닌 항의 수) * 2
- 좋은 경우 -> degree > (0이 아닌 항의 수) * 2
다항식 덧셈 알고리즘
addploy(A, B) {
p3=zeroP();
while (!iszeroP(A) && !isPzero(B)) {
case {
maxExp(A) < maxExp(B) :
C=addTerm(C, coef(B, maxExp(B)), maxExp(B));
B=delTerm(B, maxExp(B));
maxExp(A) = maxExp(B) :
sum=coef(A, maxExp(A))+ coef(B, maxExp(B));
A=delTerm(A, maxExp(A);
B=delTerm(B, maxExp(B));
maxExp(A) > maxExp(B) :
C=addTerm(C, coef(A, maxExp(A)), maxExp(A));
A=delTerm(A, maxExp(A));
}
}
if (!iszeroP(A)) A의 나머지 항들을C에 복사
else if (!iszeroP(B) B의 나머지 항들을C에 복사
return C;
}
두개의 다항식 덧셈 : A(x) + B(x) = C(x)
A(x) = 7x^3 + 6x + 1, B(x) = 8x^3 + 2x^2 +1, C(x) = A(x) + B(x)
- 순서대로 A와 B의 각 항 지수를 비교
- 지수가 같으면 배열 A(x)와 B(x)에 있는 각 항 계수를 더해 배열 C(x)로 이동
- 지수가 다르면 A(x)와 B(x) 중에 지수가 큰 항을 C(x)로 이동
- 2개의 다항식에 대해 어느 한쪽의 다항식이 끝날 때까지 계속하고 남은 다항식은 그대로 C(x)로 복사이동

시간복잡도 = while문의 반복 횟수 = O(n+m), n과m은 각각 다항식 A,B의 0이 아닌 항의 개수
A(x)=7x^5+2x^4+3x^3+6x^2+4, B(x)=3x^3+2x^2+1, C(x) = A(x) + B(x) 두 다항식 더하기
#include
<stdio.h>
#define MAX(a, b) ((a>b)?a:b)
#define MAX_DEGREE 50
typedef struct{
int degree;
float coef[MAX_DEGREE];
} polynomial;
polynomial addPoly(polynomial A, polynomial B){
polynomial C;
int A_index=0, B_index=0, C_index=0;
int A_degree=A.degree, B_degree=B.degree;
C.degree=MAX(A.degree, B.degree);
while(A_index<=A.degree && B_index<=B.degree){
if(A_degree > B_degree){
C.coef[C_index++] = A.coef[A_index++];
A_degree--;
}
else if(A_degree == B_degree){
C.coef
[C_index++] = A.coef[A_index++]+B.coef[B_index++];
A_degree--;
B_degree--;
}
else{
C.coef[C_index++] = B.coef[B_index++];
B_degree--;
}
}
return C;
}
void printPoly(polynomial P){ //다항식 출력
inti, degree;
degree=P.degree;
for(i=0;i<=P.degree;i++)
printf("%3.0fx^%d", P.coef[i], degree--);
printf("\n");
}void main(){
polynomial A={5, {7, 2, 3, 6, 0, 4}};
polynomial B={4, {3, 2, 0, 3, 1}};
polynomial C;
C= addPoly(A,B);
printf("\n A(x)="); printPoly(A);
printf("\n B(x)="); printPoly(B);
printf("\n C(x)="); printPoly(C);
}
result
A(x)= 7x^5 2x^4 3x^3 6x^2 0x^1 4x^0
B(x)= 3x^4 2x^3 0x^2 3x^1 1x^0
C(x)= 7x^5 5x^4 5x^3 6x^2 3x^1 5x^0
희소행렬(sparse matrix)
행렬 원소의 값 중에서 0의 값을 비교적 많이 가지는 행렬
- 희소행렬의 0 값의 정도에 대한 정확한 기준이 없음(2/3이상)
- 2차원 배열로 나타낼 때 공간의 낭비가 심함
- 행렬연산(덧셈, 곱셈, 전치행렬등)시 "0"의 값을 기억장소에 저장하는 것은 기억공간의 낭비 초래
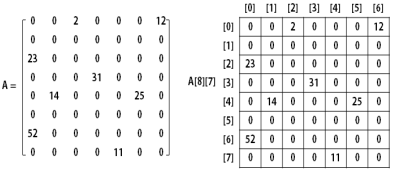
희소행렬의 ADT
ADT SparseMatrix
데이터
3 원소쌍 <i, j, v>의 집합, i∈Row, j∈Column, v∈Value
Row={0, 1, …, n-1}, Column={0, 1, …, n-1}
연산자 및 연산내용 //a, b∈SparseMatrix, c∈Matrix, u, v∈Value,
//i∈Row, j∈Column
SparseMatrix Smcreate(m, n) //비어있는 m×n 희소행렬을 생성
SparseMatrix transpose(a) //희소행렬 a의 전치행렬 c를 반환
Matrix Smadd(a, b) //두 희소행렬 a와 b의 더한 결과를 행렬 c로 반환
//단 a와 b의 차수는 동일
Matrix Smmult(a, b) //두 희소행렬 a와 b의 곱한 결과를 행렬 c로 반환
//단, 희소행렬 a의 Column과 b의 Row가 동일
End SparseMatrix
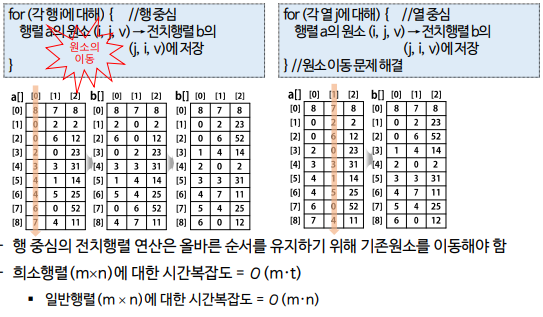
희소행렬에 대한 전치행렬 연산
전치행렬
행렬 A = m * n -> 행렬 At = n*m행렬로 변환
행렬A의 모든 원소의 위치(i,j)를 (j,i)로 교환

희소행렬의 표현(0이 아닌 원소만 저장하는 방법 필요)
배열 및 연결리스트를 이용
- 하나의 원소를 표현하기 위해 3원소 쌍(<행번호, 열번호, 원소값>)으로 배열에 저장
- 2차원인 경우 => 0이 아닌 원소의 개수[행] * 3(v[][])[열], (원 행렬에 대한 정보를 순서쌍으로 작성해 0번행에 저장)
- n차원인 경우 => t * (n+1)(v[][])

전치행렬 알고리즘
smTranspose(a[]){ //행렬a를 전치시켜b를 생성
m=a[0, 0]; n=a[0, 1] //희소행렬a의 행과 열의수
v=a[0, 2]; //희소행렬a의0이 아닌 원소수
b[0, 0]=n; b[0, 1]=m //전치행렬b의 행과 열의 수를 할당
b[0, 2]=v ; //전치행렬의 원소수 할당
if (v > 0) {
p=1;
for (i=0;i<n;i=i+1){ //a의각 열에 대해 반복, 희소행렬a의 열별로 전치 반복 수행
for (j=1; j<=v; j=j+1){ //모든 원소들을 검사, 0이 아닌 원소에 대해 반복
if (a[j, 1]=i){ //현재i열에 속하는 원소가 있으면 b[]에 삽입
b[p, 0]=a[j, 1];
b[p, 1]=a[j, 0];
b[p, 2]=a[j, 2];
p=p+1;
}
}
}
}
return b[];
}
3* 4 행렬에 대한 희소행렬
3(v[][]) 행렬을 구하는 프로그램
#include <stdio.h>
#define MAX 20
void read_matrix(int a[10][10], int row, int column);
void print_sparse(int b[MAX][3]);
void create_sparse(int a[10][10], int row, int column, int b[MAX][3]);
int main(){
int a[10][10], b[MAX][3], row, column;
printf("\n행렬의 크기 입력 : ");
scanf("%d%d", &row, &column);
read_matrix(a, row, column); //matrix를 읽음
create_sparse(a, row, column, b); //sparsematrix를 생성
print_sparse(b);
return 0;
}void read_matrix(int a[10][10], int row, int column){//주어진 행렬을 읽음
int i, j;
printf("\n행렬의 원소 값을 입력\n");
for (i = 0; i < row; i++){
for (j = 0; j < column; j++){
printf("[%d][%d]: ", i, j);
scanf("%d", &a[i][j]);
}
}
}result
행렬의 크기 입력 : 3 4
행렬의 원소 값을 입력 [0][0]: 0
[0][1]: 0
[0][2]: 0
[0][3]: 3
[1][0]: 0
[1][1]: 0
[1][2]: 6
[1][3]: 0
[2][0]: 0
[2][1]: 0
[2][2]: 7
[2][3]: 0 3원소 쌍의 희소행렬 출력
3 4 3
0 3 3
1 2 6
2 2 7void print_sparse(int b[MAX][3]){ //희소행렬 출력
int i, column;
column = b[0][2];
printf("\n3원소 쌍의 희소행렬 출력\n\n");
for (i = 0; i <= column; i++){
printf("%d\t%d\t%d\n", b[i][0], b[i][1], b[i][2]);
}
}
result
행렬의 크기 입력 : 3 4
행렬의 원소 값을 입력 [0][0]: 0
[0][1]: 0
[0][2]: 0
[0][3]: 3
[1][0]: 0
[1][1]: 0
[1][2]: 6
[1][3]: 0
[2][0]: 0
[2][1]: 0
[2][2]: 7
[2][3]: 0 3원소 쌍의 희소행렬 출력
3 4 3
0 3 3
1 2 6
2 2 7열중심의 전치행렬을 구하는 프로그램
Include <stdio.h
>
#define MAX 20
void printsparse
(int[][3]);
void readsparse
(int[][3]);
void transpose(int[][3], int[][3]);
int main(){
int b1[MAX][3],b2[MAX][3], m, n
;
printf(" 행렬의 크기 입력:");
scanf("%d%d",&m, &n);
b1[0][0]=m; //m*n
b1[0][1]=n;
readsparse(b1);
transpose(b1, b2);
printsparse(b2);
}void readsparse
(int b[MAX][3]){ //희소행렬을 읽음
inti, t;
printf("\n0이 아닌 원소의 개수 :");
scanf("%d", &t); //희소행렬 생성
b[0][2]=t;
for(i=1;i<=t;i++){
printf("\n다음3원소 쌍의값(행,렬,값) 입력 :");
scanf("%d%d%d",&b[i][0],&b[i][1],&b[i][2]);
}
}
void printsparse(int b[MAX][3]){//희소행렬 출력
inti, n;
n=b[0][2]; //0이 아닌 원소의 개수
printf("\n전치 후의 행렬\n");
printf("\n행\t\t열\t\t값\n");
for(i=0;i<=n;i++)
printf("%d\t\t%d\t\t%d\n", b[i][0], b[i][1], b[i][2]);
}void transpose(int b1[][3], int b2[][3]){//전치행렬을 구함
int i, j, k, n;
b2[0][0]=b1[0][1];
b2[0][1]=b1[0][0];
b2[0][2]=b1[0][2];
k=1;
n=b1[0][2];
for(i=0; i<b1[0][1]; i++) //행
for(j=1; j<=n; j++) //열
if(i==b1[j][1]){ //열중심 순서 값 검사
b2[k][0]=i;
b2[k][1]=b1[j][0];
b2[k][2]=b1[j][2];
k++;
}
}
result
행렬의 크기 입력 : 3 4
0이 아닌 원소의 개수 : 4
다음 3원소 쌍의 값(행, 렬, 값) 입력 : 1 0 5
다음 3원소 쌍의 값(행, 렬, 값) 입력 : 1 2 3
다음 3원소 쌍의 값(행, 렬, 값) 입력 : 2 1 1
다음 3원소 쌍의 값(행, 렬, 값) 입력 : 2 3 2
전치 후의 행렬
행 열 값
4 3 4
0 1 5
1 2 1
2 1 3
3 2 2
행중심과 열중심의 전치행렬에 대한 비교
학습정리
- 구조체는 프로그램으로 하나 이상의 변수를 그룹 지어서 새로운 자료형(복잡한 데이터 표현)을 정의하는 것으로 구조체를 이용하여 사용자가 C언어의 기본 자료형을 가지고 새로운 자료형을 정의할 수 있다.
- 범용리스트는 유한개의 순서가 있는 노드 또는 리스트들로 구성된 집합으로 다변수로 구성된 다항식의 표현, 희소행렬 표현 등에 활용할 수 있다.
- 다항식을 배열로 표현할 때 degree < (0이 아닌 항의 수) * 2이면 1차원 배열로, degree > (0이 아닌 항의 수) * 2일 경우는 다항식의 각 항에 대한 <지수, 계수>의 쌍을 2차원 배열에 저장하는 것이 좋다.
- 희소행렬은 행렬 원소의값 중에서 `0`의값을 비교적 많이 가지는 행렬로 2차원 배열로 나타낼 때 기억공간의 낭비가 심하기 때문에 희소하지 않은 배열(3원소 쌍)로 표현하여 행렬 연산을 하는 것이 좋다.
반응형
'23년 이전 글 > 자료구조' 카테고리의 다른 글
| 스택 자료구조 (0) | 2022.07.26 |
|---|---|
| 재귀함수 (0) | 2022.07.25 |
| 선형 리스트와 배열 (0) | 2022.07.23 |
| 추상 자료형, 알고리즘 (0) | 2022.07.06 |
| 자료구조 종류와 표현 방법 (0) | 2022.07.06 |