
GAN
GAN의 목적함수
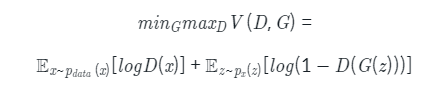
z는 임의 노이즈, D와 G는 Descriminator, Generator
D 모델에서 실제 이미지가 1, 가짜 이미지가 0이면 D는 이 식을 최대화하는게 목표로,
양쪽항에 있는 logD(x)와 log(1-D((G(z)))) 가 모두 1이 되는게 목표
G 모델은 반대로 위 식을 최소화 해야하고, log(1-D(G(z)))만 최소화하면 됨
즉, log 내부가 0이 되도록하며 D(G(z))가 1이 되도록 만듦
cGAN 목적 함수

위에 식과 대체로 동일하며, y라는 조건이 추가됨
MNIST를 학습시키는 경우 y는 0~9까지의 label 정보와 같음, y는 임의 노이즈 입력인 z의 가이드의 일종
GAN Feed forward
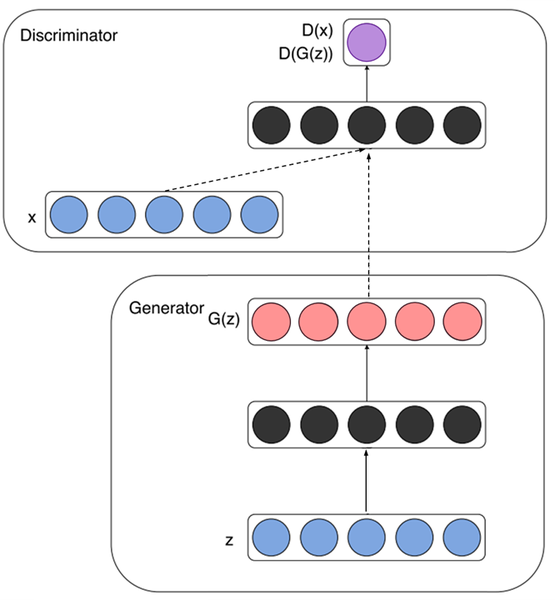
Generator
노이즈 z(파란색)가 입력되고 특정 representation(검정)으로 변환된 후 가짜데이터 G(z) (빨강)를 생성해냄
Deiscriminator
실제 데이터 x와 Generator가 생성한 가짜 데이터 G(z)를 각각 입력받아 D(x) 및 D(G(z))(보라)를 계산하여 식별
cGAN feed forward

Generator
노이즈 z(파랑)와 추가 정보 y(녹색)를 함께 입력받아 Generator 내부에서 결합되어 representation(검정)으로 변환되며 가짜 데이터 (G(z|y)를 생성. MNIST나 CIFAR-10 등의 데이터셋에 학습하는 경우 y는 레이블 정보이며 일반적으로 one-hot 벡터를 입력으로 넣음
Discriminator
실제 데이터 x와 Generator가 생성한 가짜 데이터 G(z | y)를 각각 입력 받으며, 마찬가지로 y정보가 각각 함께 입력되어 진짜와 가짜를 식별함
MNIST나 CIFAR-10등의 데이터셋을 학습하는 경우 실제 데이터 x와 y는 알맞은 한 쌍을 이뤄야 하며, 마찬가지로 Generator에 입력된 y와 Discriminator에 입력되는 y는 동일한 레이블을 나타내야함
cGAN Discriminator 구성하기
cGAN의 Discriminator는 Maxout이라는 특별한 레이어가 사용되는데, 이는 두 레이어 사이를 연결할 때 여러개의 fully-connected 레이어를 통과시켜 그 중 가장 큰 값을 가져오도록 함
2개의 fully-connected 레이어를 사용할 때 Maxout을 식으로 표현하면
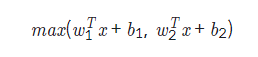
fully-connected 레이러를 2개만 사용하면 다차원 공간에서 2개의 면이 교차된 모양의 activation function처럼 작동
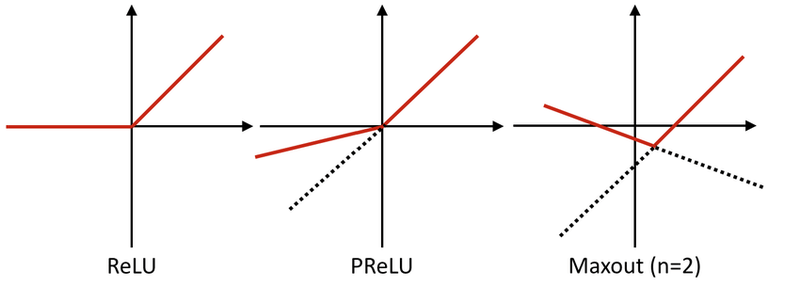
사용하는 fully-connected 레이어 갯수가 늘어나면 점점 곡선 형태 activation이 가능


Pix2Pix
cGAN에서는 작은 조건으로 원하는 클래스의 이미지를 생성할 수 있었는데, 이러한 입력자체가 조건이 된다면?
Pix2Pix는 이미지를 입력으로 하여 원하는 다른 형태의 이미지로 변환시킬 수 있는 GAN 모델

한 이미지의 픽셀에서 다른 이미지의 픽셀로 변환한다는 뜻에서 Pix2Pix라는 이름으로 불리며 GAN 기반의 Image-toImage 작업에서 가장 기초가 되는 연구
Pix2Pix2는 이미지에 효율적인 convolution 레이어를 활용

Encoder에서 이미지(x)를 입력 받으면 단계적으로 down-sampling 하면서 중요한 representation을 학습하며
Decoder에서는 이를 반대로 다시 이미지를 up-sampling해서 동일한 크기의 변환된 이미지(y)를 생성해냄
모두 conv 레이어로 진행하며 여기서 Encoder의 최종 출력은 bottleneck이라고 불리는 이 부분이 x의 가장 중요한 특징을 담고 있음

bottleneck이 이미지를 생성하는데 충분한 정보를 제공하도록 Generator 구조를 하나 더 제안함
레이어마다 Encoder, Decoder가 연결(skip connection)되어 있으며, Decoder가 변환된 이미지를 더 잘 생성하도록 Encoder로부터 추가정보를 이용하는 방법이며, U-Net구조의 Generator를 사용하면 더 좋은 결과를 얻을 수 있음

U-Net 논문 리뷰 — U-Net: Convolutional Networks for Biomedical Image Segmentation
딥러닝 기반 OCR 스터디 — U-Net 논문 리뷰
medium.com
Generator만으로 이미지 변환이 가능하지 않을까?
출력된 이미지와 실제 이미지의 차이로 손실 계산 후 역전파하여 네트워크를 학습시키면 가능하긴 함
그러나 품질의 차이가 커짐

L1이라 쓰인 Generator만으로 생성된 결과는 흐릿함. 이는 Generator가 단순히 이미지의 평균 손실만을 줄이고자 파라미터를 학습하기 때문
반면 cGAN은 훨씬 세밀한 정보를 잘 표현함. Discriminator를 잘 속이려면 진짜 같은 이미지를 만들어야 하기 때문
논문에서는 L1손실과 GAN손실을 같이 사용하면 더 좋은 결과를 얻을 수 있음
Pix2Pix (Discriminator)

DCGAN의 Discriminator는 이미지를 입력받아 conv 레이어로 크기를 줄여나가며, 이미지에 대해 확률값을 출력
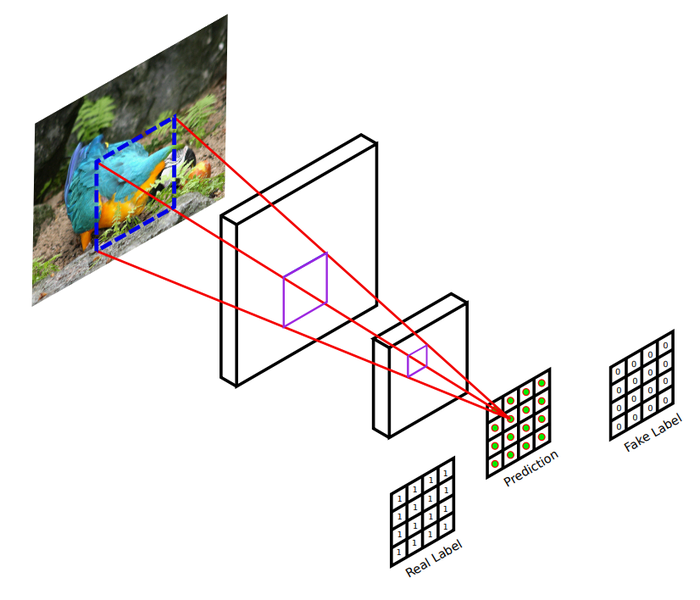
이미지를 입력받아 conv 레이어를 거쳐 여러 개의 예측값을 내놓음
전체 영역이 아닌 일부 영역에 대해서만 참 거짓을 판별하는 확률값 도출
이후 다른 확률 값들을 평균하여 최종 Discriminator 출력을 생성, 일부 영역(patch)을 활용한다고 해여 PatchGan으로도 불림
일반적으로 이미지에서 거리가 먼 두 픽셀은 연관이 없기 때문에 일부 영역에서 세부적으로 판별하는 것이 Generator에게 진짜같은 이미지를 만들게 할 수 있음

많은 patch를 사용할 수록 결과가 좋아지는 모습
Generator 구성
pix2pix

encoder의 C64는 어떠한 하이퍼 파라미터를 가진 레이어의 조합인가?
64개의 4x4 필터에 stride 2를 적용한 Convolution -> 0.2 slope의 leakyReLU (BatchNorm 사용 x)
decoder의 CD512는 어떠한 하이퍼파라미터를 가진 레이어의 조합인가?
512개의 4x4 필터에 stride 2를 적용한 Convolution -> BatchNorm -> 50% Dropout -> ReLU
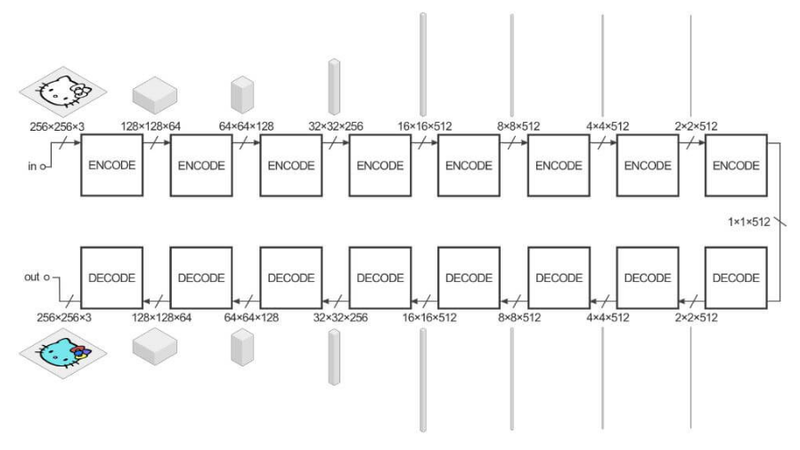
각 블록을 지나면서 입출력의 크기가 달라지며 최종적으로 1이 되고 채널의 수는 512까지 늘어남
Pix2Pix의 Generator

skip connection으로 연결한 U-Net구조가 훨씬 더 실제 이미지에 가까운 품질을 보임
Discriminator

최종 출력이 sigmoid인점이 특별한 점

2개 입력을 받아 CONCAT 후 Encode 블록 5개를 통과하며 이후 4개 블록은 C64-C128-C256-C512 마지막은 1채널차원 출력을 위한 블록
최종 출력은 30으로 출력크기가 1씩 감소하는 것이 특징
출력크기를 30으로 맞추는 이유는 70x70PatchGan을 사용할 때 각 픽셀의 receptive field 크기를 (70,70)으로 맞추기 위함
Understanding PatchGAN
Hi Guys! In this blog, I am going to share my understanding of PatchGAN (only), how are they different from normal CNN Networks, and how…
sahiltinky94.medium.com
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| -45일차- 감성분류 with sentencepiece (0) | 2022.03.16 |
|---|---|
| -44일차- 텍스트 데이터 전처리 기법들 (0) | 2022.03.15 |
| -41일차- 뉴스기사 크롤링과 분류 (0) | 2022.02.25 |
| -40일차- OCR(Optical Character Recognition) (0) | 2022.02.24 |
| -39일차- 멀티태스킹 (0) | 2022.02.23 |