
자연 언어와 프로그래밍 언어
1 자연언어와 인공언어 의 처리
자연 언어 란? 몇만년건 인류는 흩어져 살게되고, 나름대로 문화를 발전시켜 왔고, 빈약한 통신 수단의 이유로 긴 세월동안 지역별로 다양하게 발전됨 오늘날 200가지가 넘는 언어 존재 이 중 40
dukeyang.tistory.com
자연어 처리의 어려움을 말해주는 글
Announcing SyntaxNet: The World’s Most Accurate Parser Goes Open Source
Posted by Slav Petrov, Senior Staff Research Scientist At Google, we spend a lot of time thinking about how computer systems can read and ...
ai.googleblog.com
전처리

예외적으로 변형되는 여지가 다분한 언어 표현
- 불완전한 문장으로 구성된 대화의 경우
- 문장의 길이가 길거나 짧은 경우
- 채팅 데이터에서 문장 시간 간격이 너무 긴 경우
- 바람직하지 않은 문장의 사용
문장부호
문장 부호 양쪽에 공백을 추가하는 방법
def pad_punctuation(sentence, punc):
for p in punc:
sentence = sentence.replace(p, " " + p + " ")
return sentence
sentence = "Hi, my name is john."
print(pad_punctuation(sentence, [".", "?", "!", ","]))
#result
Hi , my name is john .대소문자
sentence = "First, open the first chapter."
print(sentence.lower())특수문자
import re
sentence = "He is a ten-year-old boy."
sentence = re.sub("([^a-zA-Z.,?!])", " ", sentence)
print(sentence)
#result
He is a ten year old boy.
희소표현
희소표현(Sparse representation)이라는 것이 있고 분산표현(distributed representation)이 있음
희소표현은 벡터의 각 차원마다 단어의 특정 의미 속성을 대응시키는 방식


1) 코사인 유사도(Cosine Similarity)
BoW에 기반한 단어 표현 방법인 DTM, TF-IDF, 또는 뒤에서 배우게 될 Word2Vec 등과 같이 단어를 수치화할 수 있는 방법을 이해했다면 이러한 표현 방법에 대 ...
wikidocs.net
남자와 사과의 경우, 공유하는 의미속성이 없어 내적이 0이 되므로 코사인 유사도 또한 0이 됨
주로 Embedding 레이어를 사용해 단어가 몇차원의 속성을 가질지 정의하는 방식으로 분산표현을 구현

토큰화
문장을 어떤 기준으로 쪼개었을 때, 쪼개진 단어들을 토큰이라고 하며, 쪼개는 기준은 토큰화 기법에 따라 정해짐
공백 기반의 토큰화
corpus = \
"""
in the days that followed i learned to spell in this uncomprehending way a great many words , among them pin , hat , cup and a few verbs like sit , stand and walk .
but my teacher had been with me several weeks before i understood that everything has a name .
one day , we walked down the path to the well house , attracted by the fragrance of the honeysuckle with which it was covered .
some one was drawing water and my teacher placed my hand under the spout .
as the cool stream gushed over one hand she spelled into the other the word water , first slowly , then rapidly .
i stood still , my whole attention fixed upon the motions of her fingers .
suddenly i felt a misty consciousness as of something forgotten a thrill of returning thought and somehow the mystery of language was revealed to me .
i knew then that w a t e r meant the wonderful cool something that was flowing over my hand .
that living word awakened my soul , gave it light , hope , joy , set it free !
there were barriers still , it is true , but barriers that could in time be swept away .
"""
tokens = corpus.split()
print("문장이 포함하는 Tokens:", tokens)
형태소 기반 토큰화
형태소란, 뜻을 가진 가장 작은 말의 단위
대표적인 형태소 분석기는 KoNLPy
KoNLPy: 파이썬 한국어 NLP — KoNLPy 0.4.3 documentation
KoNLPy: 파이썬 한국어 NLP KoNLPy(“코엔엘파이”라고 읽습니다)는 한국어 정보처리를 위한 파이썬 패키지입니다. 설치법은 이 곳을 참고해주세요. NLP를 처음 시작하시는 분들은 시작하기 에서 가
konlpy-ko.readthedocs.io
형태소 분석기 비교
한국어 형태소 분석기 성능 비교
korean-tokenizer-experiments 형태소 분석기 비교실험 환경하드웨어 (MacBook Pro Mid 2015)소프트웨어데이터실험 내용실행 시간 비교로딩 시간형태소 분석 시간문장 분석 품질 비교띄어쓰기가 없는 문장자
iostream.tistory.com
속도에서는 mecab이 가장 뛰어나며, 데이터의 특성(말투, 파생어 등)에 따라 성능의 격차가 다소 발생할 수 있음
사전에 없는 단어 처리
사전에 없는 단어는 <unk>등의 단어로 치환해버리며, 이는 문제가 발생할 수 있음
OOV(Out-Of-Vocabulary)라고 하며 새로운 단어에 약함.
Byte Pair Encoding(BPE)
기존에는 데이터의 압축을 위해 생겨났으며, 가장 많이 등장하는 바이트 쌍을 새로운 단어로 치환하여 압축하는 작업을 반복하는 방식으로 동작

import re, collections
# 임의의 데이터에 포함된 단어들입니다.
# 우측의 정수는 임의의 데이터에 해당 단어가 포함된 빈도수입니다.
vocab = {
'l o w ' : 5,
'l o w e r ' : 2,
'n e w e s t ': 6,
'w i d e s t ': 3
}
num_merges = 5
def get_stats(vocab):
"""
단어 사전을 불러와
단어는 공백 단위로 쪼개어 문자 list를 만들고
빈도수와 쌍을 이루게 합니다. (symbols)
"""
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols) - 1): # 모든 symbols를 확인하여
pairs[symbols[i], symbols[i + 1]] += freq # 문자 쌍의 빈도수를 저장합니다.
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out, pair[0] + pair[1]
token_vocab = []
for i in range(num_merges):
print(">> Step {0}".format(i + 1))
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get) # 가장 많은 빈도수를 가진 문자 쌍을 반환합니다.
vocab, merge_tok = merge_vocab(best, vocab)
print("다음 문자 쌍을 치환:", merge_tok)
print("변환된 Vocab:\n", vocab, "\n")
token_vocab.append(merge_tok)
print("Merge Vocab:", token_vocab)
#result
>> Step 1
다음 문자 쌍을 치환: es
변환된 Vocab:
{'l o w ': 5, 'l o w e r ': 2, 'n e w es t ': 6, 'w i d es t ': 3}
>> Step 2
다음 문자 쌍을 치환: est
변환된 Vocab:
{'l o w ': 5, 'l o w e r ': 2, 'n e w est ': 6, 'w i d est ': 3}
>> Step 3
다음 문자 쌍을 치환: lo
변환된 Vocab:
{'lo w ': 5, 'lo w e r ': 2, 'n e w est ': 6, 'w i d est ': 3}
>> Step 4
다음 문자 쌍을 치환: low
변환된 Vocab:
{'low ': 5, 'low e r ': 2, 'n e w est ': 6, 'w i d est ': 3}
>> Step 5
다음 문자 쌍을 치환: ne
변환된 Vocab:
{'low ': 5, 'low e r ': 2, 'ne w est ': 6, 'w i d est ': 3}
Merge Vocab: ['es', 'est', 'lo', 'low', 'ne']아무리 큰 데이터도 OOV 문제 없이 사전을 정의할 수 있음
Embedding 레이어는 단어개수 x Embedding 차원 수의 Weight를 생성하기 대문에 단어의 개수가 줄면 메모리를 절약할 수 있음
Wordpiece Model(WPM)
구글에서 BPE를 변형해 제안한 알고리즘으로 두가지 차별성이 존재
- 공백 복원을 위해 단어의 시작 부분에 언더바 _를 추가
- 가능도(Likelihood)를 증가시키는 방향으로 문자 쌍을 합침
여기에서 한국어에 대해 연구를 했다는 점에서 조사, 어미 등의 활용이 많고 복잡한 한국어 모델의 토크나이저로
WPM은 좋은 대안이 될 수 있음
WPM은 어떤 언어든 적용 가능한 language-neutral하고 ggeneral한 기법으로 한국어에만 적용되는 형태소 분석기처럼 한국어에만 적용 가능한 기법보다 활용도가 큼
가능도에 대한 설명 참조
확률(probability)과 가능도(likelihood) 그리고 최대우도추정(likelihood maximization)
* 우선 본 글은 유투브 채널StatQuest with Josh Starmer 님의 자료를 한글로 정리한 것 입니다. 만약 영어듣기가 되신다면 아래 링크에서 직접 보시는 것을 추천드립니다. 이렇게 깔끔하게 설명한 자료
jjangjjong.tistory.com
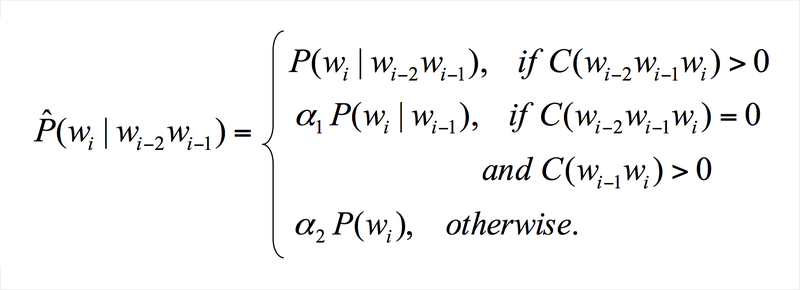
WPM은 공개가 안되어 있으나, SentencePiece라이브러리로 고성능의 BEP를 사용할 수 있음
GitHub - google/sentencepiece: Unsupervised text tokenizer for Neural Network-based text generation.
Unsupervised text tokenizer for Neural Network-based text generation. - GitHub - google/sentencepiece: Unsupervised text tokenizer for Neural Network-based text generation.
github.com
soynlp
한국어를 위한 토크나이저로 단어 추출, 품사 판별, 전처리 기능 제공
GitHub - lovit/soynlp: 한국어 자연어처리를 위한 파이썬 라이브러리입니다. 단어 추출/ 토크나이저 /
한국어 자연어처리를 위한 파이썬 라이브러리입니다. 단어 추출/ 토크나이저 / 품사판별/ 전처리의 기능을 제공합니다. - GitHub - lovit/soynlp: 한국어 자연어처리를 위한 파이썬 라이브러리입니다.
github.com
학습데이터를 이용하지 않고 단어 분해, 품사 판별을 하는 비지도학습 접근법을 지향하는 라이브러리
통계적인 방법을 사용하기 때문에 통계기반 토크나이저로 보기도 함
Word2Vec
02) 워드투벡터(Word2Vec)
앞서 원-핫 벡터는 단어 벡터 간 유의미한 유사도를 계산할 수 없다는 단점이 있음을 언급한 적이 있습니다. 그래서 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 ...
wikidocs.net
CBOW, Skip-gram 두가지가 존재
은닉층이 1개인 경우 Shallow Neural Network이므로, 딥러닝 모델이 아님
FastText
Word2Vec에서 최악의 경우 한번의 연산만 거쳐 좋은 결과를 보지 못하는 결과를 해결하기 위해 등장
BPE와 비슷한 아이디어를 적용
한국어를 위한 어휘 임베딩의 개발 -1-
한국어 자모의 FastText의 결합 | 이 글은 Subword-level Word Vector Representations for Korean (ACL 2018)을 다룹니다. 두 편에 걸친 포스팅에서는 이 프로젝트를 시작하게 된 계기, 배경, 개발 과정의 디테일을 다
brunch.co.kr
한 단어를 n-gram의 집합이라고 보고 단어를 쪼개어 각 n-gram에 할당된 Embedding의 평균값을 사용
ELMo - the 1st Contextualized Word Embedding
주변 단어 정보를 사용해 Embedding을 구축하는 개념을 소개
전이 학습 기반 NLP (1): ELMo
Deep Contextualized Word Representations | 2018년은 기계학습 기반 자연어 처리 분야에 있어서 의미 있는 해였습니다. 2015년 이후로 컴퓨터 비전 분야에서 전이 학습(transfer learning)이 유행하기 시작한 이후
brunch.co.kr
입력 토큰의 word vector, 순방향 LSTM의 hidden state vector, 역방향 LSTM의 hidden state vector를 concatenate한 벡터가 ELMo의 Contextual Word Embedding, BERT에 쓰이고 있음
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| 텍스트의 벡터화 (0) | 2022.03.21 |
|---|---|
| -45일차- 감성분류 with sentencepiece (0) | 2022.03.16 |
| -43일차- 생성모델 판별모델 (0) | 2022.03.14 |
| -41일차- 뉴스기사 크롤링과 분류 (0) | 2022.02.25 |
| -40일차- OCR(Optical Character Recognition) (0) | 2022.02.24 |