
큐의 응용
응용 분야
FIFO 구조, 즉 먼저 요청한 작업에 대해 먼저 처리해주는 형태로 동작하는 큐의 특징을 직간접적으로 다양한 분야에 응용할 수 있음
- 컴퓨터 운영체제에서 실행을 요청한 작업들을 순서 대로 처리하기 위해서 큐(버퍼 큐와 프로세스 스케줄링 큐)를 사용함
- 산업공학분야에서 최적의 시스템을 설계하기 위한 시뮬레이션에서 대기행렬 큐를 사용함(공항에서 비행기들의 이륙, 은행에서 고객의 대기열)
- 실시간 시스템에서 인터럽트를 제어(first come firsst served)하는데 사용함
- 통신에서 데이터 패킷들의 모델링, 콜센터의 고객응대 시스템 등에서 사용함
- 프로그래머의 도구 및 많은 알고리즘에서 사용함
운영체제 작업 큐
프린터 버퍼 큐(buffer queue)
인쇄 작업에서 cpu에 비해 프린터의 느린 인쇄 작업이 진행 중일 때 기다리지 않고, 다음 데이터를 버퍼 큐(주기억장치 내)에 삽입하여 버퍼 큐에 있는 데이터를 순서대로 출력하게 함 - cpu에서 프린터로 보낸 데이터를 순서대로 프린터에서 출력
writeline(){ //CPU 작업
if (출력할 내용이 있음 and 프린터 버퍼가 가득 차 있지 않음 & 프린터 버퍼가
바쁘지 않음)
then 프린터 버퍼 큐에 출력할 내용을 입력
}
readline(){ //프린터 작업
if (프린터 버퍼가 비어있지 않음 and 프린터 버퍼가 바쁘지 않음)
then 프린터 버퍼의 내용을 출력
}
스케쥴링 큐(scheduling queue)
스케쥴링 정책 - 메모리에 적재된 다수의 프로세스 중 어떤 프로세스에게 자원을 할당할 것인가에 대한 순서를 결정하는 것 => CPU와 같은 자원의 효율적인 사용
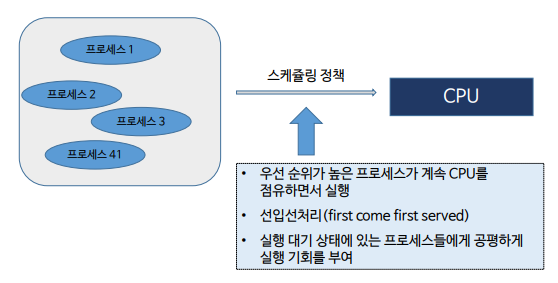
CPU를 사용하고자 요청하는 프로세스들에 대한 CPU 사용 스케줄을 관리 ( 자원의 할당과 회수, 스케쥴러 역할)을 하기 위해 사용되는 큐를 말함
준비 큐와 대기 큐로 구성되어 있음
- 사용하고자 하는 프로세스를 순서대로 준비 큐에 삽입하면 그 순서대로 준비 큐에서꺼내어 CPU를 사용함
- CPU를 사용하던 프로세스가 다른 처리를 기다리는 대기 상태가 되면 대기 큐에 삽입하여 대기 상태의 프로세서들을 순서대로 관리함

메시지 큐(message queue)
- 메시지 형태의 데이터를 넣어두고 FIFO(선입선출) 방식으로 메시지를 추출하여 대상 시스템의 데이터베이스, 파일저장, 응용프로그램 입력 값으로 처리하기 위해 사용된 큐를 말함
- 메시지 큐는 윈도우즈 시스템의 모든 스레드(프로세스 내에서 실행되는 흐름의 단위)에 존재함
- 사용자가 윈도우즈에서 어떤 조작을 수행하면 해당 입력은 메시지로 전달되며 프로세스가 메시지 큐에서 해당 입력에 대응하는 메시지를 읽어서 처리함
- 예를 들어, 사용자가 마우스를 움직이는 경우(사용자가 취한 행동)에 마우스 움직임을 의미하는 메시지인 WM_MOUSEMOVE가 메시지 큐에 저장되며 프로그램은 메시지 루프(메시지를 받아들이는 부분)를 통해 이에 대응하는 처리를 함

대기행렬 이론(queueing theory)
시뮬레이션
- 실제로 실행하기 어려운 실험을 간단히 행하는 모의실험을 뜻함
- 특히 컴퓨터를 이용하여 모의실험을 할 때는 컴퓨터 시뮬레이션이라고 함
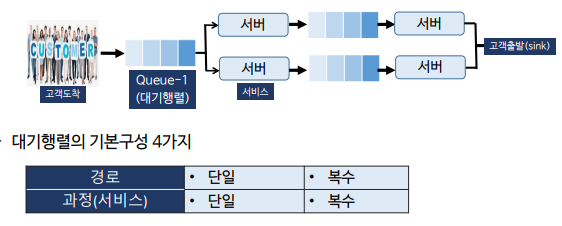
대기행렬(queue, waiting line)
- 은행의 창구, 마트의 계산대, 공항의 입국심사 창구의 수 등에서와 같이 대기행렬에 도착하는 것과 대기하는 것 그리고 서비스 되는 일련의 프로세스들에 대한 모델링에 사용되는 통계적인 이론으로 수학적, 확률적 분석을 가능하게 해줌
- 즉 시스템의 평균 대기시간, 서비스의 예측 등을 현재 상태를 기반으로 한 시스템의 확률을 기반으로 하여 성능을 측정하는데 유용하게 활용할 수 있음
대기행렬 큐
- 여러 상황에 대해 최적의 시스템을 설계하기 위한 시뮬레이션에서 사용하는 큐로서 서비스를 받기 위해 기다리는 대기행렬과 대기시간을 모델링하는데 사용됨
- 예를 들어, 공항에 도착하는 입국자는 큐로 만든 대기행렬에 순서대로 들어가고, 입국 심사관은 큐에 있는 입국자들을 순서대로 처리하게 됨
우선순위(다중) 큐
다중큐(multi-queue)는 여러 개의 큐(multiple queue)들로 구성된 자료구조라 할 수 있음

- 우선순위 큐는 삽입된 순서에 상관없이 일정한 순서(우선순위)에 의해 삭제되는 자료구조로 각각의 우선순위에 따라 여러 개의 큐로 구성할 수 있음
- 원소마다 우선순위(priority)가 존재 => 보통 key 값으로 우선순위를 표현함
- 원소의 우선순위 연산
- 큐에 있는 가장 낮은(높은) 우선순위를 갖는 원소를 먼저 처리(삭제)함 - Min Priority Queue, Max Priority Queue
- 동일한 우선순위를 갖는 요소가 두 개 이상 => FIFO 방식으로 처리함
스택과 큐 또한 우선순위 큐의 일종
스택 : 삽입시간이 가장 짧은 원소에 가장 높은 우선순위를 부여한 우선순위 큐
큐 : 삽입시간이 가장 오래된 원소에 가장 높은 우선순위를 부여한 우선순위 큐
우선순위 큐 구현
- 배열 - 간단하게 구현이 가능하지만 데이터 삽입과 삭제 과정에서 데이터를 한 칸씩 이동해야 하는 연산이 필요하며, 삽입의 위치를 찾기 위해 배열에 저장된 모든 데이터와 우선순위를 비교해야함

- 연결리스트 - 삽입의 위치를 찾기 위해 첫 번째 노트부터 시작해 마지막 노드에 저장된 데이터와 우선순위 비교를 진행할 필요가 있음(성능 저하 초래)
- 힙(heap) - 구현이 어렵지만 연산이 가장 효율적임
힙 구조의 우선순위 큐

- 삽입할 원소는 완전 이진트리를 유지하는 형태로 순차적으로 삽입됨
- 삽입 이후에는 근노드까지 거슬러 올라가면서 최대 힙을 구성함 - 부모노드와 비교를해서 부모노드가 삽입한 노드의 값보다 작다면 교체해야함
- 시간복잡도 - O(log N)
우선순위 큐 ADT
ADT PriorityQueue
데이터
0개 이상의 원소를 가진 유한 순서리스트
연산자 및 연산내용 // q∈PQueue, e∈Element
PQueue createpq() //하나의 공백 우선순위 큐를 생성
Number currentSize(q) //q의 원소의 수를 반환
PQueue addpq(q, e) //q에 새로운 원소 e를 rear를 통해 삽입
Element deletepq(q) //q가 공백이면 underflow, 그렇지 않으면 q로부터
//가장 작은(큰) 키 값의 원소를 삭제 후 반환
End PriorityQueue
우선순위 큐에 있는 원소들의 순서쌍 관계
우선순위 큐의 전체순서(total order)관계가 성립할 경우 => 우선순위 큐의 모든 원소들은 우선순위에 따라 정렬이 됨

우선순위 큐(priority queue)의 삽입/삭제
삽입 알고리즘
addpq(pq, i, e) {
rear[i] = (rear[i]+1) % n;
if (front [i] ==rear [i]) queue-full;
else pq[i] [rear [i] = e;삭제 알고리즘
deletepq(pq, i) {
if (front[i] ==rear[i]) queue-empty;
else {
front[i] = (front[i] + 1) % n;
e = pq[i] [front[i]];
return e;
우선순위 큐(priority queue)의 구현
2차원 배열을 이용한 순차 표현
char queue[5][5];
int front[5]; //5개의 우선순위 큐에 대한 front 포인터
int rear[5]; //5개의 우선순위 큐에 대한 rear 포인터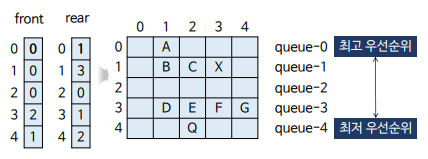
배열을 이용한 구현
1차원 배열을 이용한 우선순위 큐의 생성/삽입/삭제 프로그램
GitHub - dlfrnaos19/algorithm_with_c: learning algorithm
learning algorithm. Contribute to dlfrnaos19/algorithm_with_c development by creating an account on GitHub.
github.com
데크
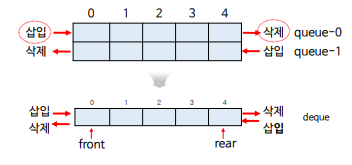
- 데크(double-ended queue)에서 의미하듯 큐 2개를 반대로 붙여서 만든 자료구조임
- 큐와 스택의 중간 정도의 특징을 가지며 두 가지로 분류
- L-pointer(front) => 데크의 왼쪽 끝을 가리키며, 삽입과 삭제가 이루어짐
- R-pointer(rear) => 데크의 오른쪽 끝을 가리키며, 삽입과 삭제가 이루어짐
- 종류 - scroll(입력제한 데크), shelf(출력제한 데크)
- 오버플로우를 방지하기 위해 중앙에서 삽입(이동현상 초래) => 환형으로 처리가 필요함
데크 ADT
ADT Deque
데이터 0개 이상의 원소를 가진 유한 순서리스트
연산자 및 연산내용 // dq∈DQueue, e∈Element
DQueue createdq() //하나의 공백 데크를 생성
DQueue addfirstdq(dq, e) //dq의 처음에 새로운 원소e를 삽입
DQueue addlastdq(dq, e) //dq의 끝에 새로운 원소e를 삽입
Boolean isEmpty(dq) //dq가 공백이면 true, 그렇지 않으면 false를 반환
Element deletefirstdq(dq)) //dq가 공백이면 underflow,
//그렇지 않으면 dq의 처음 원소를 삭제후 반환
Element deletelastdq(dq)) //dq가 공백이면 underflow,
//그렇지 않으면 dq의끝 원소를 삭제후 반환
Element lastdq(dq)) //dq의끝 원소를 반환
Element firstdq(dq)) //dq의 처음 원소를 반환
End Deque데크 구현
두개의 포인터를 이용한 데크의 생성/삽입/삭제(환형 배열 고려)


GitHub - dlfrnaos19/algorithm_with_c: learning algorithm
learning algorithm. Contribute to dlfrnaos19/algorithm_with_c development by creating an account on GitHub.
github.com
'23년 이전 글 > 자료구조' 카테고리의 다른 글
| 연결구조, 환형 연결리스트, 이중 연결리스트, 환형 이중 연결리스트 (0) | 2022.08.15 |
|---|---|
| 연결구조, 연결리스트, 단일 연결리스트 (0) | 2022.08.07 |
| 스택 자료구조 (0) | 2022.07.26 |
| 재귀함수 (0) | 2022.07.25 |
| 구조체와 범용 리스트 (0) | 2022.07.24 |