
귀무가설과 대립가설
통계적 가설
통계학에서 사용하는 용어로, 하나의 특정 주장을 모수를 이용해 나타낸 형태를 지칭
귀무가설(null hypothesis, 기호 Ho), 영가설
통계학에서 처음부터 버릴 것을 예상하는 가설 ex) 새로운 감기약을 투여한 환자 평균 치료 기간에 변화가 없다
대립가설(alternative hypothesis, 기호 H1), 연구가설
연구자가 연구를 통해 입증되기를 기대하는 예상이나 주장하는 내용 ex) 새로운 감기약 투여한 환자 평균 치료 기간의 변화가 있다
- 단측 대립가설 : 관련성을 검정할 때, 그 방향이 미리 어느 한쪽으로 결정되어 있는 경우
- 양측 대립가설 : 차이가 존재하는가? 라는 면에서만 관심, 그 방향은 따지지 않는 가설
귀무가설 채택 시 대립가설은 기각, 귀무가설 기각 시 대립가설이 채택
유의확률(Significance probability, p-value)
실제로는 차이가 없는데 우연히 집단 간의 차이가 있는 데이터가 추출되었을 확률
- 유의확률이 크면 집단 간 차이가 통계적으로 유의하지 않다고 해석-> 귀무가설 채택, 대립가설 기각
- 유의확률이 작다면 집단 간 차이가 통계적으로 유의하다고 해석-> 귀무가설 기각, 대립가설 채택
- 유의확률 판단 기준
유의수준(significance level)
- 일반적으로 0.05, 0.01까지 쓰는 곳도 존재함
- 1-유의수준(1-α) 신뢰구간 또는 신뢰수준
- 0.05가 유의수준이라면 95% 신뢰 수준을 기준으로 한다는 의미
t-검정
가설검정
모집단에 대한 가설을 설정한 후에 표본 관찰을 통해 그 가설의 채택 여부를 결정하는 분석 방법
- 귀무가설과 대립가설 중에 하나를 선택하는 과정
- 귀무가설이 옳다는 전제하에 p-value를 구한 후 유의수준보다 크면 귀무가설 채택, 작으면 귀무가설 기각
t-검정(t-test)
두 집단이 유의하게 차이가 있는지를 판별할 때 표본의 평균값을 활용하는 검정
- 관찰 대상 전체에 해당하는 모집단의 관측값을 수집하는 것은 불가능한 경우가 대다수이므로 표본을 추출하고, 그 표본의 평균을 이용하여 모집단 간 차이를 검증
- 비교 대상이 같은 집단 -> 대응 이표본 t-검정(Dependent t-test for paired samples)
- 비교 대상이 다른 집단 -> 독립 이표본 t-검정(Independent two-sample t-test)
- 하나의 모집단에서 추출한 표본으로 모집단의 모수 추정 -> 일표본 t-검정(One-sample)
t-검정의 가정
두 모집단은 정규분포를 따른다
t-검정의 과정
- t-value와 자유도(n-1)를 구한다. 여기에서 n은 표본의 수를 의미
- 자유도(n-1)의 t-분포를 구한다.
- t-분포에서 t-value의 위치를 찾아 p-value를 계산한다
- p-value를 유의수준(0.05)와 비교한다.(유의수준이 0.05라면 5%를 기준으로 특이케이스로 판단한다는 의미)
예제) 다이어트 약에 대한 효과 판정하기
p-value가 0.02라면 다이어트약을 먹지 않은 사람들 중 2%에만 발생하고, 98%에는 발생하지 않는 케이스로 판단가능
즉 다이어트 복용하지 않은 자연스러운 체중 감소 현상이라고 보기 어려우므로 이 다이어트약은 효능이 있다고 말할 수 있음
p-value가 0.02로 유의수준 0.05보다 작으므로 귀무가설은 기각되고, 대립가설이 채택됨
ANOVA(ANalysis of VAriance)
집단 간 차이를 검정하는데 표본의 분산을 활용하는 검정

집단 간 분산 외에 집단 내의 분산도 검정에 활용
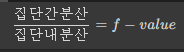
F-value
집단 간 분산과 집단 내 분산의 비를 f-value(f 통계량)라고 하고 이를 f-검정에서 활용함
분산분석 기본 가정
- 가정 1 : 각 집단에 해당되는 모집단의 분포가 정규분포다.
- 가정 2 : 각 집단에 해당되는 모집단의 분산이 같다.
- 가정 3 : 각 모집단 내에서의 오차나 모집단 간의 오차는 서로 독립적이다.
f-검정의 과정
- f-value와 자유도(n-1)을 구한다. 여기에서 n은 표본의 수를 의미한다
- 자유도(n-1)의 f-분포에서 f-value의 위치를 찾아 p-value를 계산한다
- p-value의 값을 유의수준(0.05)과 비교한다.
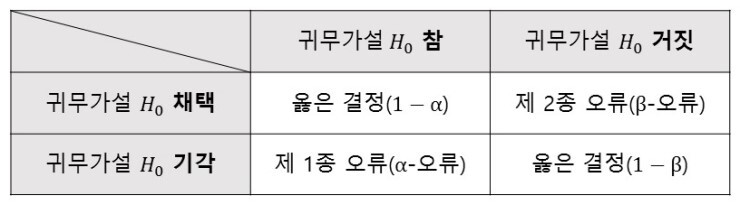
가설 검정의 결과와 오류
1종 오류 : 귀무가설(H0)이 사실인데 귀무가설을 기각했을 때의 오류
2종 오류 : 반대로 대립가설(H1)이 사실인데 귀무가설을 채택했을 때 오류
'23년 이전 글 > 통계' 카테고리의 다른 글
| 통계 변수 (0) | 2022.06.06 |
|---|---|
| 통계학이란? (0) | 2022.06.06 |
| 정규분포와 표준화 (0) | 2022.06.06 |
| 확률 이론 (0) | 2022.06.05 |
| 기초 통계량, 확률 (0) | 2022.06.05 |