-27일차- 딥러닝 레이어의 이해
딥러닝 모델 속 각 레이어의 동작 방식 이해하기
데이터의 형태들
(2,3,6)의 매트릭스 형태를 띄는 데이터

이미지, (1920,1080,3)의 매트릭스 형태의 의미지(Width,Height,Channel)

레이어?
레이어는 하나의 물체가 여러개의 논리적인 객체들로 구성되어 있는 경우, 이러한 각각의 객체를 레이어라 한다
Linear 레이어
Fully Connected Layer,등등 여러가지 이름으로 불리지만 결국은 Linear 레이어이며,
선형대수학에서 쓰이는 용어 중 선형변환이란 용어가 있는데 그것과 동일한 기능을 하는 레이어
Linear 레이어는 선형변환을 활용해 데이터를 특정 차원으로 변환하는 기능을
100 -> 300차원이면 데이터 표현이 풍부해지고 10차원으로 변환하면 데이터를 집약
코드로 표현해보기
import tensorflow as tf
batch_size = 64
boxes = tf.zeros((batch_size, 4, 2)) # Tensorflow는 Batch를 기반으로 동작하기에,
# 우리는 사각형 2개 세트를 batch_size개만큼
# 만든 후 처리를 하게 됩니다.
print("1단계 연산 준비:", boxes.shape)
first_linear = tf.keras.layers.Dense(units=1, use_bias=False)
first_out = first_linear(boxes)
first_out = tf.squeeze(first_out, axis=-1) # (4, 1)을 (4,)로 변환해줍니다.
# (불필요한 차원 축소)
print("1단계 연산 결과:", first_out.shape)
print("1단계 Linear Layer의 Weight 형태:", first_linear.weights[0].shape)
print("\n2단계 연산 준비:", first_out.shape)
second_linear = tf.keras.layers.Dense(units=1, use_bias=False)
second_out = second_linear(first_out)
second_out = tf.squeeze(second_out, axis=-1)
print("2단계 연산 결과:", second_out.shape)
print("2단계 Linear Layer의 Weight 형태:", second_linear.weights[0].shape)
# result
1단계 연산 준비: (64, 4, 2)
1단계 연산 결과: (64, 4)
1단계 Linear Layer의 Weight 형태: (2, 1)
2단계 연산 준비: (64, 4)
2단계 연산 결과: (64,)
2단계 Linear Layer의 Weight 형태: (4, 1)

코드로 표현해보기
import tensorflow as tf
batch_size = 64
boxes = tf.zeros((batch_size, 4, 2))
print("1단계 연산 준비:", boxes.shape)
########
first_linear = tf.keras.layers.Dense(3, use_bias=False)
first_out = first_linear(boxes)
########
print("1단계 연산 결과:", first_out.shape)
print("1단계 Linear Layer의 Weight 형태:", first_linear.weights[0].shape)
print("\n2단계 연산 준비:", first_out.shape)
# Dense = Linear
second_linear = tf.keras.layers.Dense(units=1, use_bias=False)
second_out = second_linear(first_out)
second_out = tf.squeeze(second_out, axis=-1)
print("2단계 연산 결과:", second_out.shape)
print("2단계 Linear Layer의 Weight 형태:", second_linear.weights[0].shape)
print("\n3단계 연산 준비:", second_out.shape)
########
third_linear = tf.keras.layers.Dense(units=1, use_bias=False)
third_out = third_linear(second_out)
third_out = tf.squeeze(third_out,axis=-1)
########
print("3단계 연산 결과:", third_out.shape)
print("3단계 Linear Layer의 Weight 형태:", third_linear.weights[0].shape)
########
total_params = first_linear.count_params() + second_linear.count_params() + third_linear.count_params()
########
print("총 Parameters:", total_params)
이런 코드로 데이터를 활용해서 가장 적합한 Weight를 찾아가는 과정이 학습이며, 학습 과정에서 지나치게 많은 Parameter는 과적합을 일으킬 수 있음에 유의해야함
편향(Bias)
선현변환된 값에 편향값을 더함으로 원점을 평행이동하는 것만으로 해결할 수 없을 때 사용
Convolution 레이어
입체적인 형태의 데이터를 만난다면?
1단계: (1920, 1080, 3) → (1920 x 1080 x 3, )
2단계: (6220800, ) x [6220800 x 1 Weight] = (1, )
620만개의 파라미터가 생성되며 모든 픽셀을 한줄씩 살펴야하기 때문에 비효율적
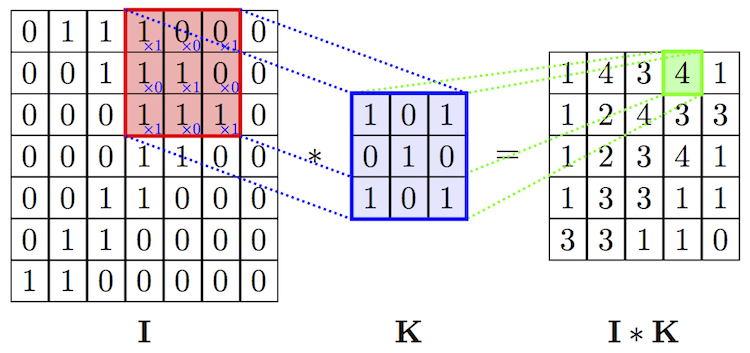

Stride
이미지를 필터로 훑을 때 몇칸씩 이동할지 정하는 값
Padding
입력의 테두리에 0을 추가해서 입력의 형태를 유지하는 기술
Padding은 왜 할까?
Convolution 과정에서 Padding은 반드시 필요하다. 왜 그러한지 살펴보도록 하자. Convolution Filter를 통과하게 되면 Input 이미지가 작아진다. Padding을 이용하면 그대로 유지할 수 있다 예를 들어 6x6
brunch.co.kr
필터의 역할

1단계: (1920, 1080, 3) x [3 x 16 x 5 x 5 Weight & Stride 5] = (384, 216, 16)
2단계: (384, 216, 16) → (384 x 216 x 16, )
3단계: (1327104, ) x [1327104 x 1 Weight] = (1, )
16개의 5 x 5 필터를 가진 convolution 레이어를 정의해서 stride 5로 이미지를 지나가며
1차원으로 펼쳐 Linear레이어로 정보를 집약
convolution 레이어의 파라미터는 3 x 16 x 5 x 5 = 1200개
주의사항
해당 구조는 입력데이터의 크기가 커서 5x5 필터로 원하는 물체를 판별할만큼 크기가 적절하지 않을 수 있으며 이를 위해 입력의 크기를 줄이거나 필터크기의 조절이 필요
필터의 크기와 Stride의 크기가 같으면 경계선에 물체가 걸릴 경우 인식을 못할 수도 있으므로 Stride를 줄여 자세히 이미지를 탐색하도록 구조에 대한 고민이 필요
import tensorflow as tf
batch_size = 64
pic = tf.zeros((batch_size, 1920, 1080, 3))
print("입력 이미지 데이터:", pic.shape)
conv_layer = tf.keras.layers.Conv2D(filters=16,
kernel_size=(5, 5),
strides=5,
use_bias=False)
conv_out = conv_layer(pic)
print("\nConvolution 결과:", conv_out.shape)
print("Convolution Layer의 Parameter 수:", conv_layer.count_params())
flatten_out = tf.keras.layers.Flatten()(conv_out)
print("\n1차원으로 펼친 데이터:", flatten_out.shape)
linear_layer = tf.keras.layers.Dense(units=1, use_bias=False)
linear_out = linear_layer(flatten_out)
print("\nLinear 결과:", linear_out.shape)
print("Linear Layer의 Parameter 수:", linear_layer.count_params())
Pooling 레이어

Max Pooling레이어를 통해 효과적으로 Receptive Field를 키우고 정보 집약효과를 극대화할 수 있음
2x2 영역안에 가장 큰 값을 뽑고 나머지는 무시
힘들게 연산하여 나온 숫자들을 왜 다시 무시하는걸까?
translational invariance 효과
인접한 영역 중 가장 특징이 두드러진 영역 하나를 뽑는 것은 시프트 효과에도 불구하고 동일한 특징을 안정적으로 잡아낼 수 있는 긍정적 효과가 있음
Non-linear 함수와 동일한 피처 추출 효과
Relu와 같은 Non-linear 함수처럼 하위 레이어 연산결과를 무시하는 효과가 있지만 가장 중요한 피처만 상위 레이어로 올림으로써 결과적으로 분류기의 성능을 증진시키는 효과가 생김(Min/Max)동일
Receptive Field 극대화 효과
Max pooling 없이 Receptive Field를 크게하려면 Convolutional 레이어를 많이 쌓아야 하는데 그럴 경우 큰 파라미터 사이즈로 인한 오버피팅, 연산량 증가, Gradient Vanishing등의 문제를 감수해야함
이럴때 효과적으로 해결할 수 있는 방법이 Max Pooling레이어 이며 추가적인 요소로는
Dilated Convolution이 있음. 참조
receptive field(수용영역, 수용장)과 dilated convolution(팽창된 컨볼루션)
receptive field 는 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기이다. 그림 1) 일반...
blog.naver.com
정보 복원 Deconvolution 레이어
Convolution의 결과를 역재생해서 원본이미지와 최대한 유사한 정보를 복원하는 Auto Encoder
import numpy as np
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import mnist
import json
import matplotlib.pyplot as plt #for plotting
# MNIST 데이터 로딩
(x_train, _), (x_test, _) = mnist.load_data() # y_train, y_test는 사용하지 않습니다.
x_train = np.expand_dims(x_train, axis=3)
x_test = np.expand_dims(x_test, axis=3)
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
# AutoEncoder 모델 구성 - Input 부분
input_shape = x_train.shape[1:]
input_img = Input(shape=input_shape)
# AutoEncoder 모델 구성 - Encoder 부분
encode_conv_layer_1 = Conv2D(16, (3, 3), activation='relu', padding='same')
encode_pool_layer_1 = MaxPooling2D((2, 2), padding='same')
encode_conv_layer_2 = Conv2D(8, (3, 3), activation='relu', padding='same')
encode_pool_layer_2 = MaxPooling2D((2, 2), padding='same')
encode_conv_layer_3 = Conv2D(4, (3, 3), activation='relu', padding='same')
encode_pool_layer_3 = MaxPooling2D((2, 2), padding='same')
encoded = encode_conv_layer_1(input_img)
encoded = encode_pool_layer_1(encoded)
encoded = encode_conv_layer_2(encoded)
encoded = encode_pool_layer_2(encoded)
encoded = encode_conv_layer_3(encoded)
encoded = encode_pool_layer_3(encoded)
# AutoEncoder 모델 구성 - Decoder 부분
decode_conv_layer_1 = Conv2D(4, (3, 3), activation='relu', padding='same')
decode_upsample_layer_1 = UpSampling2D((2, 2))
decode_conv_layer_2 = Conv2D(8, (3, 3), activation='relu', padding='same')
decode_upsample_layer_2 = UpSampling2D((2, 2))
decode_conv_layer_3 = Conv2D(16, (3, 3), activation='relu')
decode_upsample_layer_3 = UpSampling2D((2, 2))
decode_conv_layer_4 = Conv2D(1, (3, 3), activation='sigmoid', padding='same')
decoded = decode_conv_layer_1(encoded) # Decoder는 Encoder의 출력을 입력으로 받습니다.
decoded = decode_upsample_layer_1(decoded)
decoded = decode_conv_layer_2(decoded)
decoded = decode_upsample_layer_2(decoded)
decoded = decode_conv_layer_3(decoded)
decoded = decode_upsample_layer_3(decoded)
decoded = decode_conv_layer_4(decoded)
# AutoEncoder 모델 정의
autoencoder = Model(input_img, decoded)
autoencoder.summary()
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
x_test_10 = x_test[:10] # 테스트 데이터셋에서 10개만 골라서
x_test_hat = autoencoder.predict(x_test_10) # AutoEncoder 모델의 이미지 복원생성
x_test_imgs = x_test_10.reshape(-1, 28, 28)
x_test_hat_imgs = x_test_hat.reshape(-1, 28, 28)
plt.figure(figsize=(12,5)) # 이미지 사이즈 지정
for i in range(10):
# 원본이미지 출력
plt.subplot(2, 10, i+1)
plt.imshow(x_test_imgs[i])
# 생성된 이미지 출력
plt.subplot(2, 10, i+11)
plt.imshow(x_test_hat_imgs[i])
이미지 복원에 사용된 레이어가 Encoder에서 사용한것과 동일한 레이어인데, 채널 개수만 늘어난 상태로 정보 집약이 안되어 있는 상태
Upsamling 레이어
Max Pooling이 레이어를 통해 Downsampling 시도했던 것에 비해 이제는 Upsampling레이어를 통해 반대작업을 수행
- Nearest Neighbor : 복원해야 할 값을 가까운 값으로 복제
- Bed of Nails : 복원해야 할 값을 0으로 처리
- Max Unpooling : Max Pooling때 무시한 값을 기억했다가 복원
[신경망] 18. Deconvolution
안녕하세요, 이번 포스팅에서는 Deconvolution에 대해서 배워보도록 하겠습니다. 우선 Deconvolution이 무엇이기를 알기 전에, 어떠한 목적을 가지고 탄생되었는지를 알아야 합니다. 그러기 위해서는 Im
analysisbugs.tistory.com
Transposed Convolution
Up-sampling with Transposed Convolution 번역
Naoki Shubuya님의 Up-sampling with Transposed Convolution을 허락받고 번역한 글입니다. 번역이 어색한 경우엔 영어 표현을 그대로 사용했으며, 의역이 존재할 수 있습니다. 피드백 언제나 환영합니다!
zzsza.github.io
from tensorflow.keras.layers import Conv2DTranspose
# Conv2DTranspose를 활용한 AutoEncoder 모델
# AutoEncoder 모델 구성 - Input 부분
input_shape = x_train.shape[1:]
input_img = Input(shape=input_shape)
# AutoEncoder 모델 구성 - Encoder 부분
encode_conv_layer_1 = Conv2D(16, (3, 3), activation='relu')
encode_pool_layer_1 = MaxPooling2D((2, 2))
encode_conv_layer_2 = Conv2D(8, (3, 3), activation='relu')
encode_pool_layer_2 = MaxPooling2D((2, 2))
encode_conv_layer_3 = Conv2D(4, (3, 3), activation='relu')
encoded = encode_conv_layer_1(input_img)
encoded = encode_pool_layer_1(encoded)
encoded = encode_conv_layer_2(encoded)
encoded = encode_pool_layer_2(encoded)
encoded = encode_conv_layer_3(encoded)
# AutoEncoder 모델 구성 - Decoder 부분 -
decode_conv_layer_1 = Conv2DTranspose(4, (3, 3), activation='relu', padding='same')
decode_upsample_layer_1 = UpSampling2D((2, 2))
decode_conv_layer_2 = Conv2DTranspose(8, (3, 3), activation='relu', padding='same')
decode_upsample_layer_2 = UpSampling2D((2, 2))
decode_conv_layer_3 = Conv2DTranspose(16, (3, 3), activation='relu')
decode_upsample_layer_3 = UpSampling2D((2, 2))
decode_conv_layer_4 = Conv2DTranspose(1, (3, 3), activation='sigmoid', padding='same')
decoded = decode_conv_layer_1(encoded) # Decoder는 Encoder의 출력을 입력으로 받습니다.
decoded = decode_upsample_layer_1(decoded)
decoded = decode_conv_layer_2(decoded)
decoded = decode_upsample_layer_2(decoded)
decoded = decode_conv_layer_3(decoded)
decoded = decode_upsample_layer_3(decoded)
decoded = decode_conv_layer_4(decoded)
# AutoEncoder 모델 정의
autoencoder = Model(input_img, decoded)
autoencoder.summary()