
활성화 함수
종류
Sigmoid, tanh, ReLU, Leaky ReLu, Maxout, ELU
Sigmoid

문제점
1. Kill gradient(Vanishing Gradient)
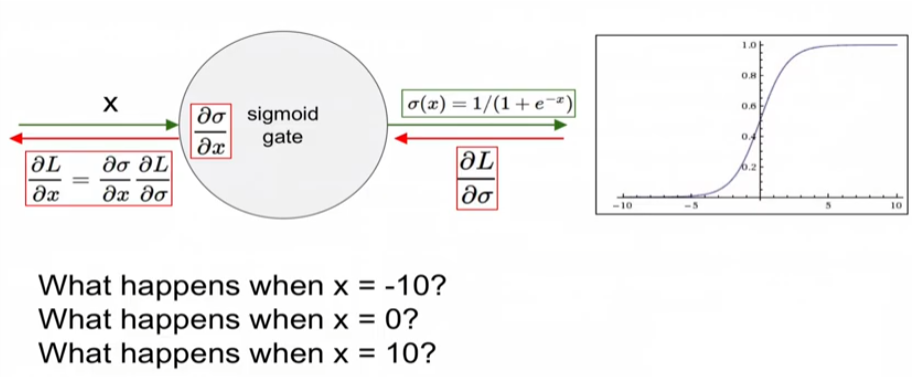
X가 특정값 일 때 기울기가 소실되는 경우가 발생
2. Sigmoid outputs are not zero-centered
0을 중심으로 이뤄지지 않으면 Slow Convergence를 가져옴

파란색 화살표가 최적의 그라디언트 방향인데 지그재그 방향으로 찾아가기 때문에
효율적으로 그라디언트를 찾질 못함!

3. Exp is a bit compute expensive
컴퓨팅 비용이 비싸다!!
Sigmoid 이제 잘 안쓴다!!
Tanh 함수
장점: -1 부터 1까지의 범위, Zero centered
단점: 여전히 그라디언트 소실
Relu
장점: 요즘 선택한다면 필수, saturate 안함, computation 효율적, converges 빠름(sigmoid, tanh보다)
단점: Not Zero centered, x < 0 경우 기울기0, 여전히 소실

방지하기 위해서 bias를 작은 수로 초기화 해주는 경우가 있긴 함
Leaky Relu
장점: Not saturate, Computation 효율적, Converges 빠름(sigmoid, tanh보다), 기울기 소실 없음!
단점: 검증이 완전 끝나지 않았음
PReLu

장단점 설명은 없었는데, 활성화 함수 자체도 기울기를 적용하는 아이디어 신선한 함수
ELU(Exponential Linear Units)

장점: 렐루의 장점을 가지고 기울기 소실이 없으며, zero mean output
단점: computation exp연산 비쌈!
Maxout
장점: 렐루와 리키렐루를 일반화하고, saturate 없고 기울기 소실 없음!
단점: weight의 파라미터 값이 두개를 가지기 때문에 computation 비용 비쌈!
결론은 일반적인 경우 ReLU쓰고 learning rate 주의할 것, 실험적인 내용에는 Leaky ReLU / Maxout / ELU 시도는 해봐도 좋음, Tanh 왠만하면 사용하지말고, sigmoid는 사용하지 말 것! (단 LSTM은 씀)
학습 절차
step 1: 데이터 전처리
Zero-centering은 일반적으로 하지만 이미지에 normalizing은 하지않음, 이미지는 이미 0~255의 범위가 있음

PCA(주성분분석)
데이터를 비상관화하여 차원을 줄임
Whitening
데이터간의 중복을 줄여줌

PCA와 Whitening, normalize가 일반적이진 않음에 주의!

가중치 초기화

최초의 아이디어인데, 네트웍이 작을 땐 괜찮았지만 커지면 문제가 발생

10레이어의 기준으로 설명을 해보면..

레이어의 표준편차가 점점 수렴하게 되면서 기울기도 작아지면서 소실 발생!

숫자가 너무 작았나... 숫자를 키워봤더니 saturation 당하게 됨!

이런 저런 도전 결과, Relu에 가장 잘 동작하는 초기화 방법은 이것

가중치 초기화에 너무 목메달지 않도록 해주는 방법
Batch Normalization
기울기 소실을 막아주기 위해 나온 것, 학습의 속도를 가속화 하면서 안정적으로 이루어지게끔 시도
계층을 거칠때마다 normalize 해주는게 핵심 이론, 정규분포를 적용함

mini batch를 뽑아서 평균과 분산을 뽑아서 정규화를 함

fully connected layer, Batch Normalization, Tanh 순서도
근데 이런 가우시안 형태의 입력을 하는게 맞을까 하는 문제가 생김

이러한 입력에 대한 것도 학습에 의해서 이루어지게 될 것 batnormalization undo 할것인지 여부의 결정

기울기가 개선되고, 높은 학습률, 가중치 초기화에 대한 의존성 약화, 일종의 정규화도 수행(만능??)

학습을 할때는 mean, variance는 batch를 기준으로 구하고 테스트 할때는 전체를 기준으로 구함

학습 절차 관리
위에서 봤던 내용으로 간단하게 패스
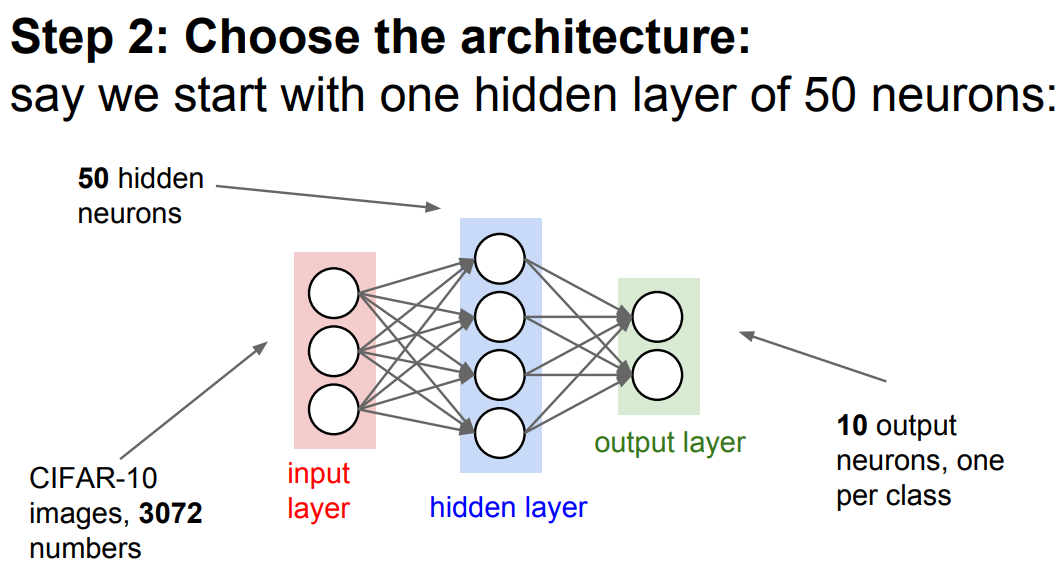
Architecture
1개의 hidden layer, CIFAR-10 데이터셋을 활용
간단한 테스트롤 통해서 Loss가 제대로 나오는지 확인하기

규제를 올리면 Loss가 올라가는지 확인하기

일부의 데이터(20개)로만 학습할 경우 overfitting이 일어나게됨!

천천히지만 학습을 하고 있네요 loss는 감소하지 않지만 정확도만 올라가는 중

cost 부분에 infinity를 뜻하는 inf가 나오는걸로 봐서 learning rate가 너무 큼!

Hyperparameter Optimization
Cross-validation strategy
coarse -> fine
처음에는 가벼운 epoch와 큰 learning rate, 어느정도 감을 잡은 후 제대로 train
Learning rate의 분포와 정확도 변경에 따라서 하이퍼파라미터를 서치해나가야하고, 어쩌면 랜덤 범위도 바꿔나가야 할 수도 있음(범위의 끝 지점에서 정확도가 올라가는게 식별됨)

그리드 서치의 경우 같은 x의 값을 가짐으로써 여러가지 경우의 서치가 잘 안됨, 특정위치만 하기때문에 최적의 위치를 놓칠 수 있음
그에비해 랜덤서치가 훨씬 효과적으로 넓은 범위를 찾을 수 있음

하이퍼 파라미터를 만지는 것은 디제잉 하는것과 비슷하다(해본건가??)

어쩌면 딥러닝은 머리로 하는 것이 아니라 손으로 하는 것인가 하고 생각하게 만드는 그림

모니터링 해야할 중요한 지표들

기울기가 빠르게 증가하지 않고 흘러가는 것은 가중치 초기화의 문제일 가능성이 높다

강화학습의 손실함수 값인데 정해진 데이터와 환경이 아니기 때문에 당황하면 손실이 올라갔다가 다시 적응하면 안정이 되는 사람 같은 모습이 보여서 재미있음

어느정도 갭 이상은 오버피팅, 갭이 없다면 모델 capacity를 더 증가해야함!

결론은?

활성화 함수는 Relu로 쓰자
이미지 데이터 전처리에선 subtract mean으로 하자
가중치 초기화는 Xavier init 방법을 쓰자
Batch Normalization 쓰자
Hyperparameter Optimization 할 때 랜덤 샘플링 로그활용해서 해보자!
'23년 이전 글 > Flipped learning' 카테고리의 다른 글
| Lecture 4 역전파와 신경망 (0) | 2022.01.14 |
|---|