![[upstage] 캐글 그랜드 마스터 발표 정리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fng2OW%2FbtrqRTAISRg%2FAAAAAAAAAAAAAAAAAAAAALOTzQtvJI5seQISOe96qsOXxKM4muDMb77YbB8swi0k%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DQsjkKVu4gPj5lGnUVCZefLwSeDg%253D)
본 글은 해당 유튜브를 보고 앞으로 캐글 도전에 앞서 참고하기 위해 정리하는 글입니다

그 또한 코드 조차 모르던때가 있었으나 앤드류 응 교수님의 강의 및 Coursera 강의 위주로
지식을 습득하셨고 시작은 19년도 1월부터..
기초는 코세라 강의를 통해 습득하고 이후 바로 대회를 시작하며 이후에는 필요한 지식에 한해서 인터넷에서 찾아봄
-> 필요할 때 찾아보기 때문에 효과적
Global Residency

좋은 장비 : 좋은 장비 부분에서 위와 같이 활용이 불가하다면 Colab Pro에서 TPU를 활용할 것을 추천
좋은 팀원 : 이 부분은 따라할 수가 없는 부분
다만 커뮤니티 채널을 열어두고 아이디어가 떠오를 때마다 공유하고 개선하는 점은 좋은 점이었음

의외로 수학은 나와있지 않다. 물론 서울대 출신이고 하니 기본적은 수학은 잘해서이기도 하겠지만..
기초:
성윤님이 말하는 핵심은 기본적인 영어가 되어야 영어로된 품질 좋은 데이터를 읽을 수 있음
코세라에 퀄리티 좋고 준비된 강의가 많음(앤드류 응 교수님 강의 한번 더 언급)
구글링은 두말할게 없음
그다음
열정 : 재미에서 오는 열정 -> 새로운 것을 만들고 결과(순위)가 나오는 것 ->실패를 극복하는 열정 끈기
시간 : 전세계 개발자들과 경쟁하며 준비해야함. 2년간 머릿속에서 캐글이 가장 큰 부분을 차지했다
장비 : 1일 걸릴거 4시간, 큰모델은 메모리 적으면 터진다. Colab pro TPU로 1위 하시는 분들도 있다
훌륭한 팀원 : 혼자할 때보다 동기부여도 되고 더 많은 시도를 하게 된다, 확률이 높아진다
솔로 : 솔로로 좋은 성적 거둘경우 외부에 명확하게 알릴 수 있다
Why Kaggle?

마지막이 핵심. 재미있다!
대회에서의 매달 시스템 설명

메달에 관한 설명인데, 생각보다 메달을 주는 기준이 후하다는 점을 말씀해주시고 있는 중
이 정도면 못해도 동매달은 따볼만하지 않을까?
티어

매달 획득 등 각종 업적에 따라서 티어를 올릴 수 있다
확실한 것은 매달의 갯수겠지만 대회 외에 활동으로도 티어를 올릴 수 있다
디스커션 참여, 데이터셋, 노트북 공유 등등
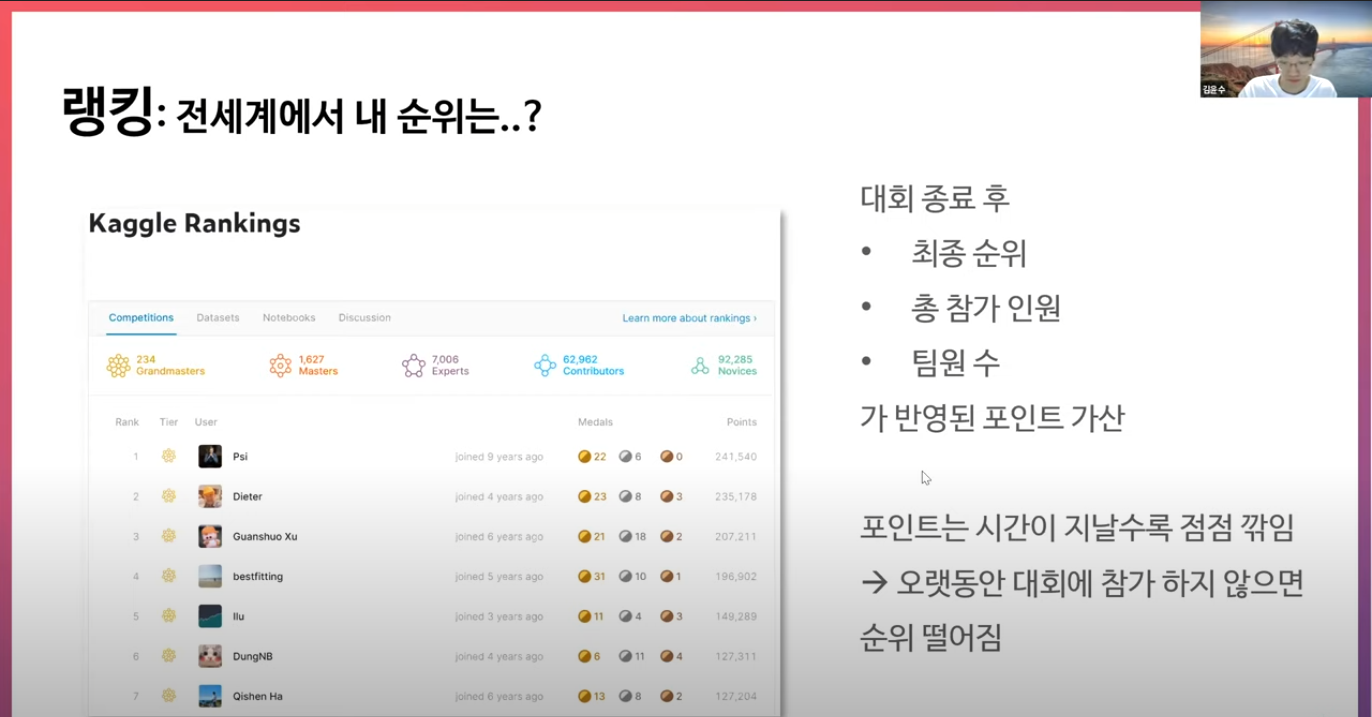
랭킹 시스템
캐글의 4가지 분야

Competitions
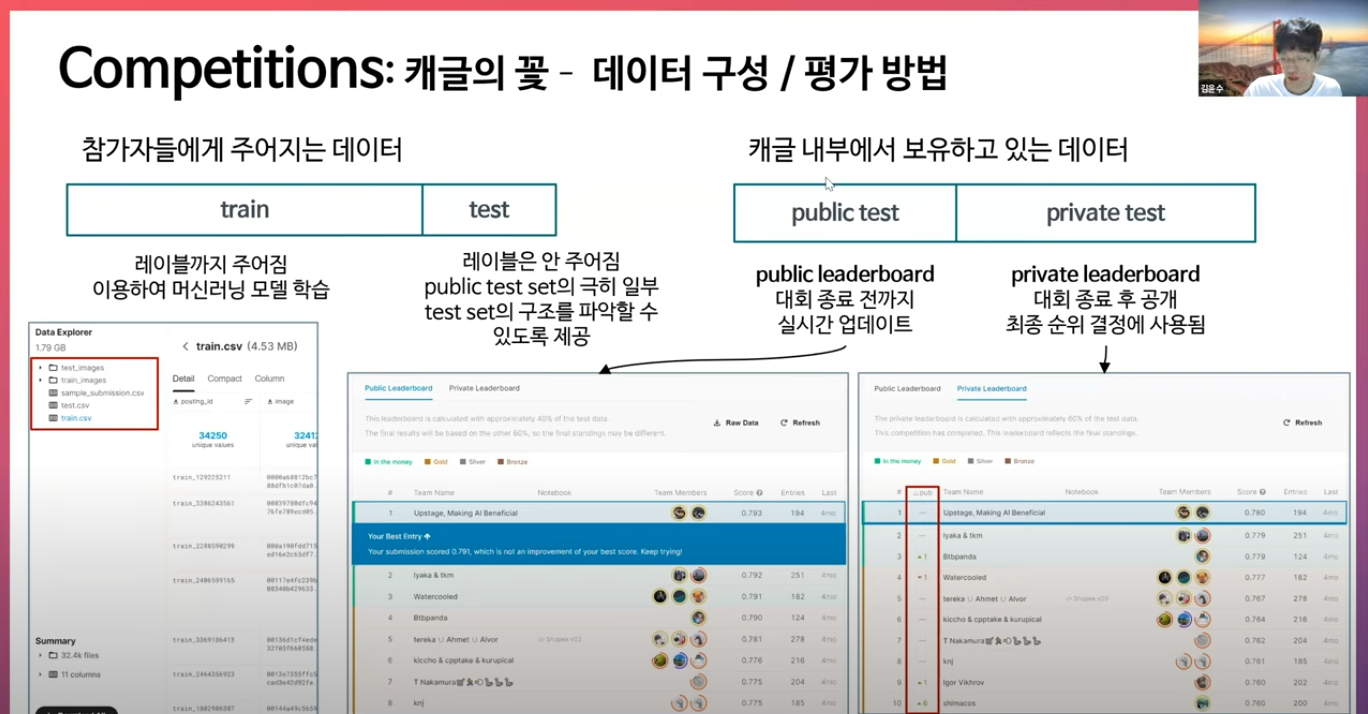
핵심은 캐글이 test 셋을 public 용과 private 용으로 따로 있기 때문에 대회가 끝날 때 private test를 통해서 결과가
나오기 때문에 public에서 나온 결과가 뒤바뀌게 될 수도 있음
캐글 노트북과 구글 코랩의 비교
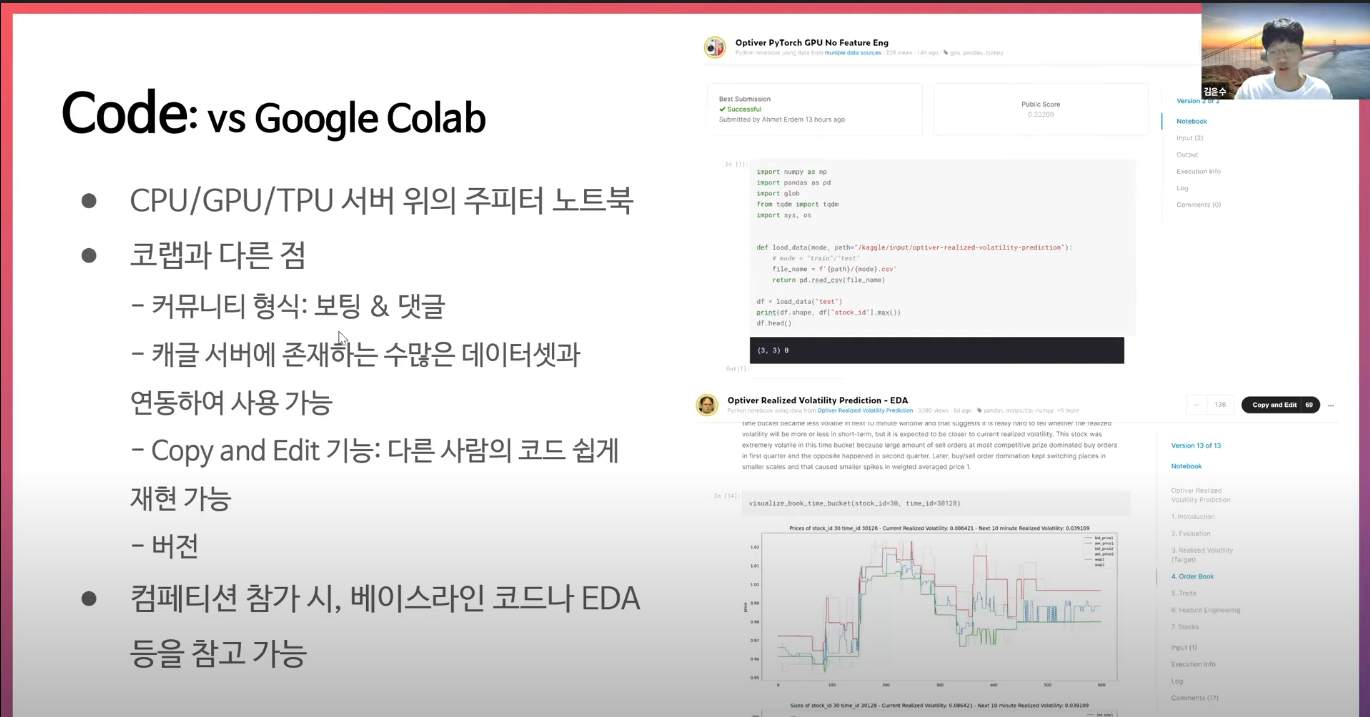
Competition에 참가하는 입장에서는 데이터와 노트북 모두 쉽게 불러 올 수 있기 때문에 활용하는게 유리해보인다
Discussion
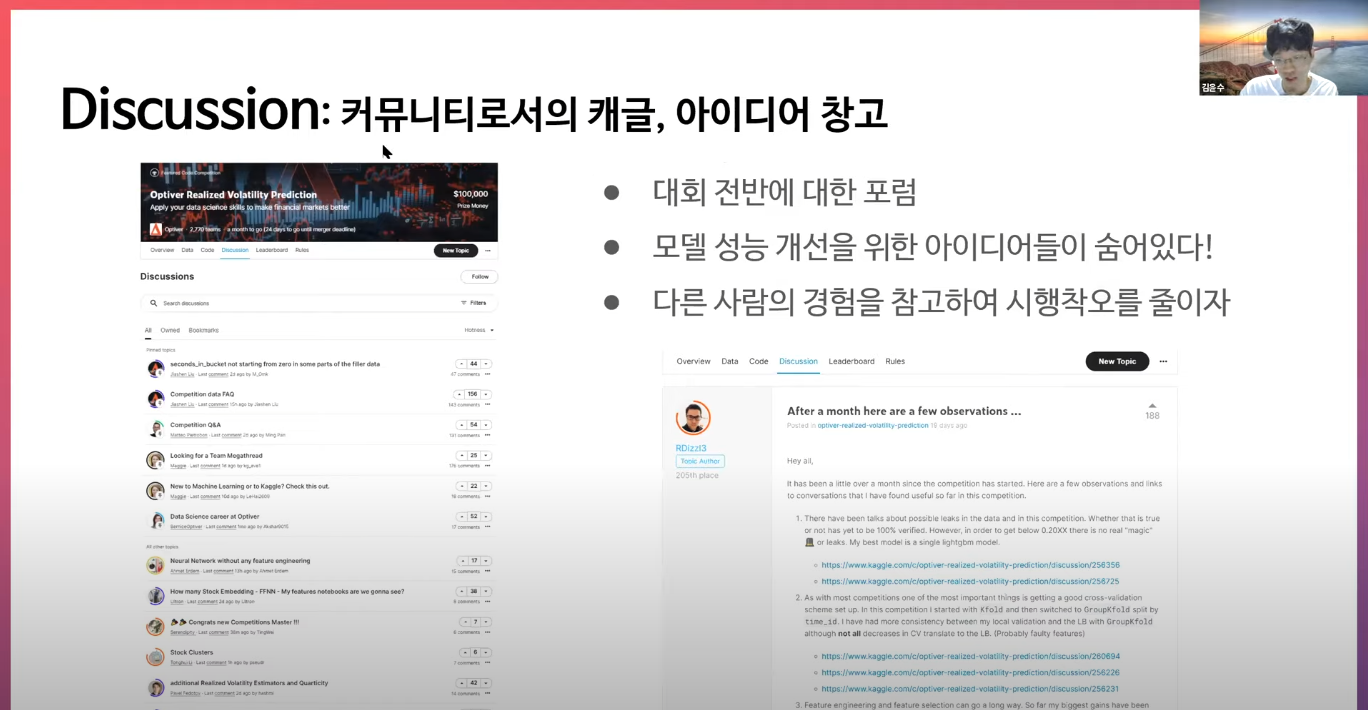
Discussion탭에는 성능을 올릴 아이디어가 숨어있다는 것이 핵심
Datasets
이런게 있다 정도로 언급
캐글에서 좋은 성적 얻기 위한 꿀팁

public test에서 높은 성적인데 private 가면서 성적이 나빠지는 경우가 있음
이런 경우는 대회 자체의 데이터셋 구성에 이상이 있을 수도 있다
그래서 이런 경우가 안생기려면 제공하는 train, public test셋과의 cross validation - lb 상관관계를 확인해야함
검증 방법
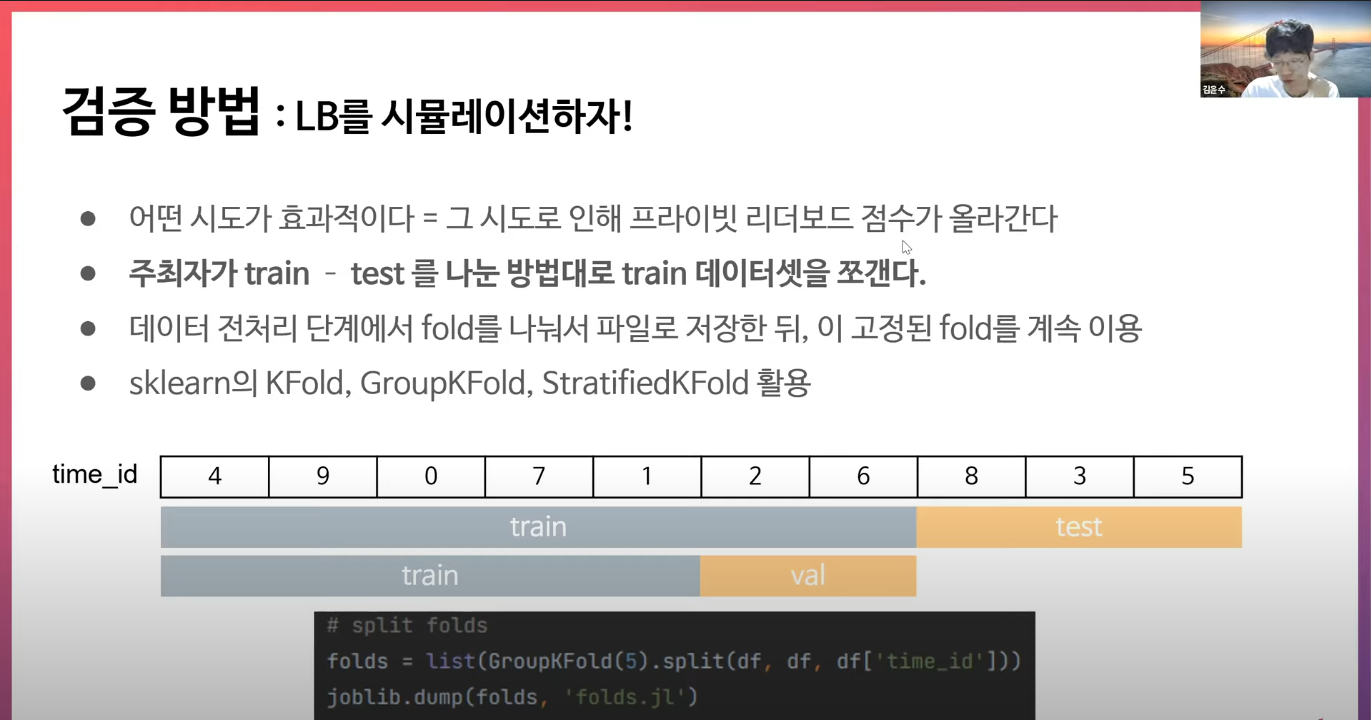
주최자가 train-test 나눈 방법과 최대한 비슷하게 쪼갠다
데이터 전처리 단계에서 쪼갠 fold대로 파일을 저장하고 고정된 fold를 활용한다
사이킷런의 KFold, GroupKFold, StratifiedKFold
예) train과 test셋에서 time_id가 겹치지 않는다면 우리가 하는 train과 valid set에서도 겹치지 않게 한다
(아래에 코드는 이해가 안되서 직접 쳐봐야 알 것 같다..)
OOF, 5fold

장점 :
- 하나의 fold 보다 5배가 많다
- 더 많은 데이터로 검증하고 안정적인 데이터를 뽑아낸다
- 2차 모델의 input으로도 넣을 수 있다
- 5개의 모델을 앙상블해서 사용할 수도 있다
대부분 5fold를 사용하는데 만약 데이터가 너무 많으면 그냥 1fold로 하다가 마지막 제출 때만 5fold를 하기도 한다
시계열 데이터라면 split4만 제대로된 테스트 환경이 가능하다
베이스라인 작성

위 내용과 동일

대회 참여할 때 가장먼저 이전 대회에서 사용했던 위의 폴더를 복사해와서 응용한다고 함
적용순서
eda -> preprocess(data loader가기전에 빠르게 처리가 되게끔) -> dataset class 정의(pytorch) -> data_check(dataset 확인) -> model -> train.py, predict.py 부분은 왠만큼 동일해서 크게 손댈게 없음, stack
점수올리기

적절한 모델은 공유된 캐글 노트북을 통해 판단하거나, 이미지 분류등의 Task를 보고 모델을 선정
베이스라인 위에서 위의 싸이클을 반복해야함
아이디어는 논문부터 데이터 특성등 다양한 곳에서 얻어야 함
사소해보이는 차이에서 점수차이가 나오게 되므로 다양하게 시험해봐야함
3549의 실험까지 해봤음 (5Fold라서 700번 가량의 실험이긴 함)
앙상블
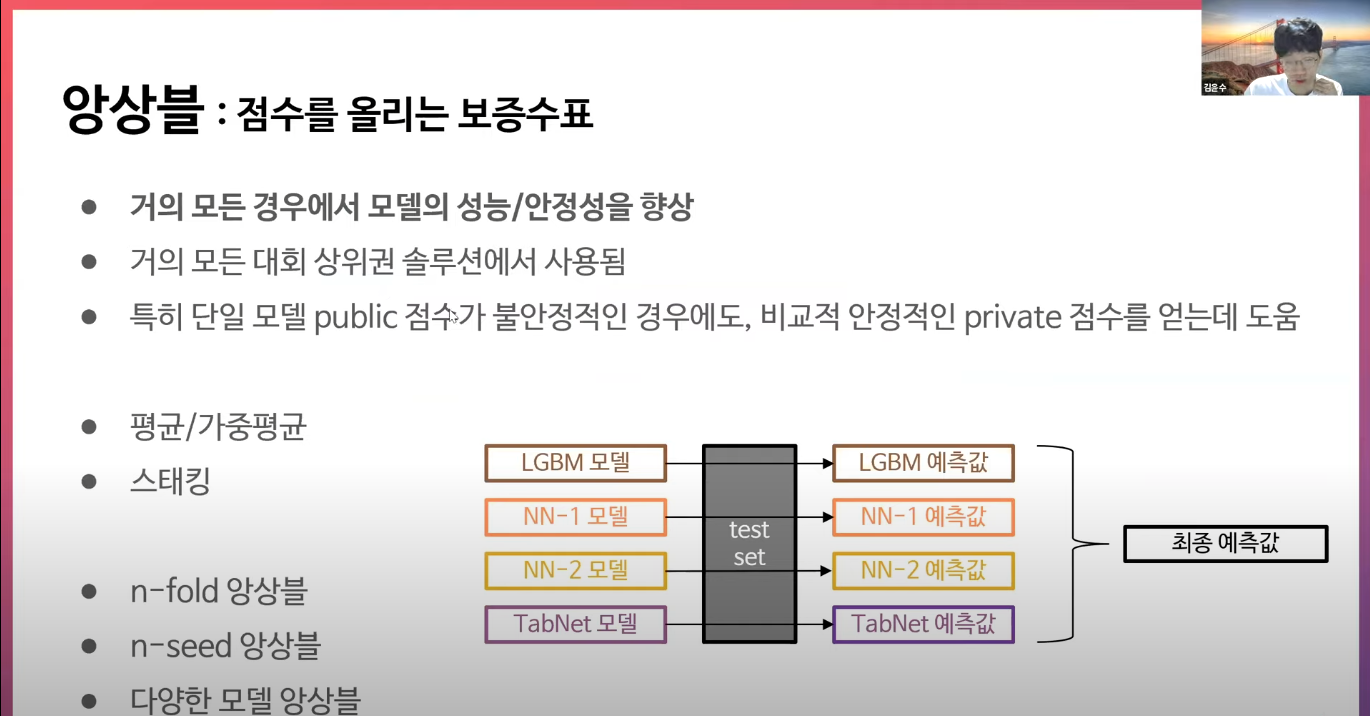
무조건 써먹을 줄 알아야할 기술로 생각이 됨
결합할 때 단순히 평균/가중평균, 또는 스태킹의 방법을 사용하기도 함
학습시킬 때에도 랜덤 시드도 다양하게 해볼 수 있음(이건 좀 노가다네)
예측값의 다양성이 클수록 앙상블의 효과가 큼
라이브러리들

대회에서 필요할 때 습득하면 되기 때문에 어떤 라이브러리인지만 언급
GBM(Gradient Boost Machine): 대세가 딥러닝이 되긴 했지만 아직 앙상블용으로 많이 씀 lightGBM이 성능이 가장 좋고 빠르다고 알려져 있음
딥러닝: pytorch가 최근에 많이 사용되면서 pytorch로 넘어가심, pytorch lightning 리서치 하기에 좋음, 디테일하게 손댈 필요가 없어서 tpu 같은거도 쉽게 쓸 수 있음 코드 구조화 하기에 편함
비전: 최신 모델 바로 업데이트 해주는 깃허브
자연어처리: 크게 언급 없음
WANDB: 하이퍼 파라미터 튜닝하는 곳, OPTUNA 활용을 하심
대회 금메달 솔루션

스킬셋 : 캐글에 자주 쓰이는 기법은 효과도 보증됨, 솔루션에 가장 큰 도움
포럼 : 대회별 디스커션이 아이디어의 원천
이전 대회 솔루션 : 이전 대회의 솔루션 비슷한 대회라면 참고하기 좋음
데이터 특성 : 본인만의 아이디어 첨가
엔지니어링 : train과 test의 환경 맞추기, 사소한 코딩 실수 없애기
논문 : 잘모르는 분야라면 논문을 통해 지식을 습득해야한다
장비 : 큰사이즈의 모델의 경우는 장비가 필수불가결이다
upstage에서 첫번째 대회

문제점을 해결하기 위해 아래의 기법들 시도
리더보드가 불안정할때는 앙상블이 특히 효과, labem smoothing과 pseudo labeling은 좀 더 찾아볼 필요가 있음
upstage에서 두번째 대회
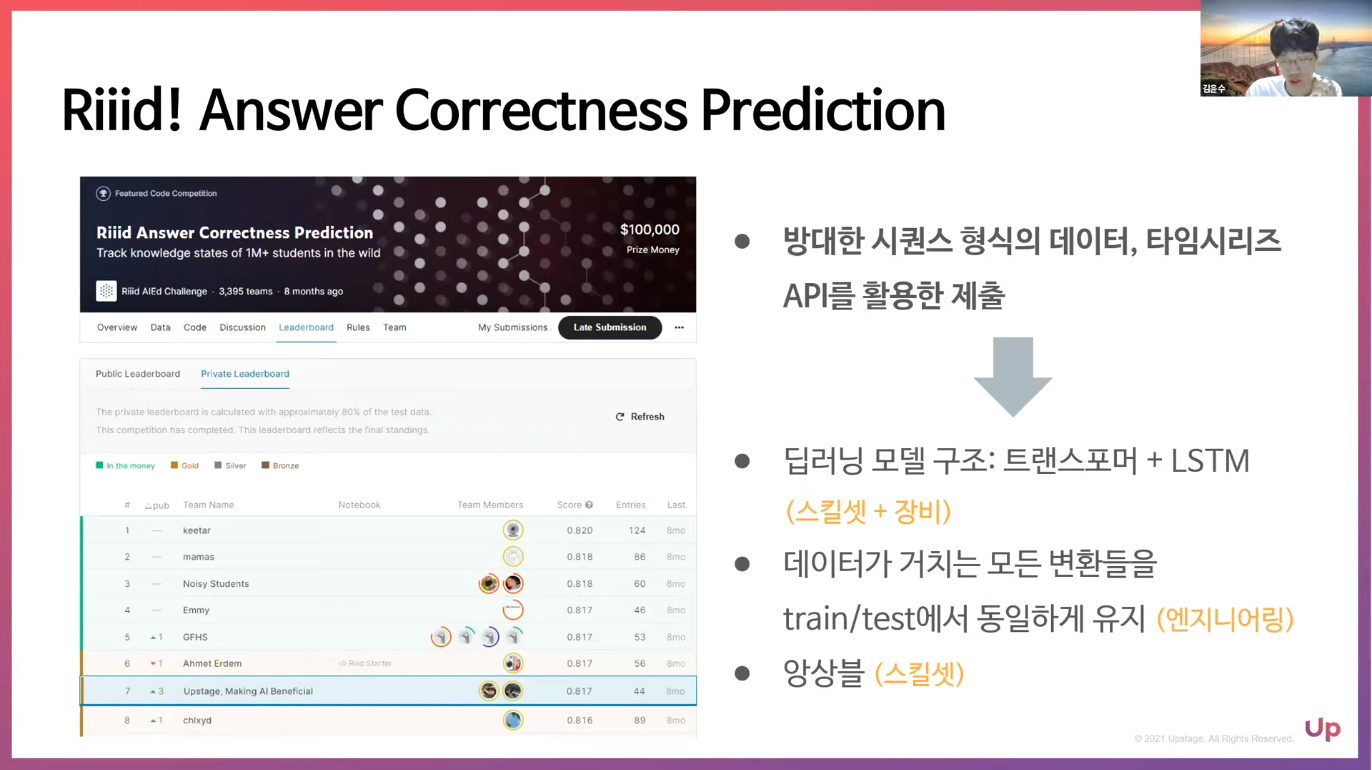
따로 언급하진 않으셨지만 아무래도 직접 밑바닥부터 학습을 시키신 듯한 느낌을 받음
모델 구조 또한 이전부터 활용해오던 것이라는 정도의 언급
upstage에서 세번째 대회(솔로)

고해상도와 큰 모델...
upstage에서 네번째 대회(솔로)

텍스트와/이미지 임베딩 결합했다는게 호기심이 가는 부분
가장 최근 대회

글에 나온 내용대로라서 다른 언급은 X
Q&A
1. 공부는 어떻게 했는지
- 기초는 코세라로, 실전은 캐글로 빡세게
2. 라이브러리는 뭐쓰는지, 결과 어떻게 저장하는지
- 파이토치, 라이트닝, validation score loss, wandb에서 학습시간이나 config logging 사용
- 실험관리 툴 많고 다 써보진 않았음.
- 주피터는 간단한 체크
3. 금메달까지의 대회출전 횟수
- 8~9개 정도 , 금메달 소감 너무 좋았다
4. 혼자서 대회 참가 했을때 컴사양
- 2080ti 1개, ryzen cpu, 램 64GB
5. upstage 인턴과 관하여
- 캐글에서 높은 등수가 목표
- 경력이 없다면 cs와 딥러닝 지식 봄
- 직장인도 되지만 경진대회 참여 및 잠재력을 보여줘야 함
6. 캐린이들에게 조언
- 해보면 재미있을거다 해보시길 추천!
'23년 이전 글 > Kaggle' 카테고리의 다른 글
| NBME Score Clinical Patient Notes 솔루션 분석해보기 -Medical NLP (0) | 2023.01.26 |
|---|---|
| 캐글로 알게 된 10가지 (0) | 2022.03.17 |
| 캐글 대회간 참조할 링크 (0) | 2022.01.18 |