
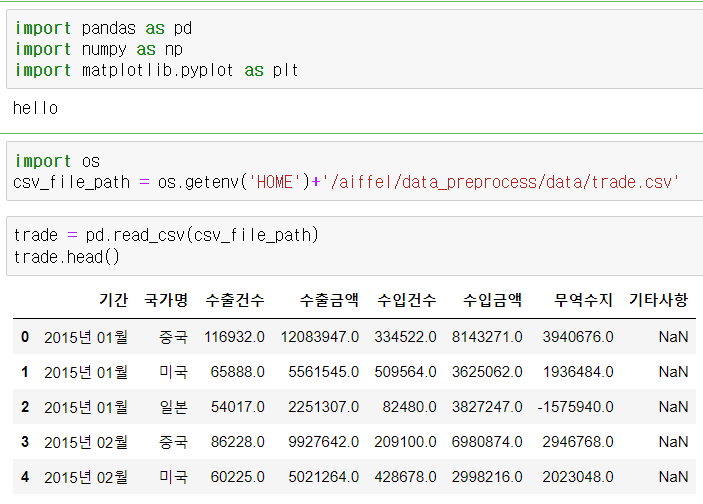
예제데이터
관세청 수출입 무역 통계 가공 데이터
결측치(Missing Data) 구하기
데이터 수집 과정에서 누락된 데이터가 존재할 수 있다
이를 처리하는 예제
#전체 데이터 개수 - 실제 데이터양
len(trade) - trade.count()
기타사항의 경우 데이터가 아예 존재하지않음.
# 결측치만 존재하는 컬럼 제거
trade = trade.drop('기타사항', axis=1) #ex) df.drop('column name', axis= 1 for column)
결측치가 존재하는 행 찾기
isnull() 함수와 any()의 조합
isnull : 데이터마다 결측치 여부를 True, False로 반환
any : 행마다 하나라도 True가 있으면 True, 아니면 False를 반환
#trade 데이터 프레임에 결측치를 찾는 조건식 삽입
trade[trade.isnull().any(axis=1)
결측치만 존재하는 데이터 행의 삭제
how='all' (선택한 컬럼 전부가 결측치인 행을 삭제)
subset = [컬럼리스트]
inplace = True면 데이터프레임에 바로 적용
trade.dropna(how='all', subset=['수출건수', '수출금액', '수입건수', '수입금액', '무역수지'], inplace=True)
결측값의 대치 (평균대치법)
trade.loc[[188,191,194]]
# 3월과 5월의 수출금액 평균을 4월에 입력
trade.loc[191, '수출금액'] = (trade.loc[188, '수출금액'] + trade.loc[194, '수출금액'] )/2
trade.loc[[191]]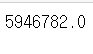
#수출금액이 나왔으므로 무역수지는 수출금액 - 수입금액으로 구할 수 있음
trade.loc[191,'무역수지'] = trade.loc[191,'수출금액'] - trade.loc[191,'수입금액']
중복데이터의 처리
중복데이터 확인하기
trade[trade.duplicated()]
# 기간과 국가명이 동일한 행을 찾는 조건식
trade[(trade['기간']=='2020년 03월')&(trade['국가명']=='중국')]
중복 데이터 제거
trade.drop_duplicates(inplace=True)행 삭제시 index가 틀어지므로 재설정에 유의
#reset_index는 현재행에 맞는 index 재설정함, 동시에 기존의 index행은 index column을 가지고 나오게됨
#따라서 drop으로 제거
trade.reset_index(inplace=True)
trade.drop('index',inplace=True, axis=1)
이상치(Outlier)의 처리
z-score method
# z-score 방법에 의한 이상치 측정 함수
# 절대값(수치 - 수치평균 / 표준편차) > z-score
def outlier(df,col,z):
return df[abs(df[col]-df[col].mean()/df[col].std()) > z].indexz와의 판별식을 반대로하면 이상치외의 정상적인 데이터만 추리는 조건식이 됨
trade.loc[not_outlier(trade,'무역수지',1.5)]
IQR method(Interquartile range) 사분위 범위수
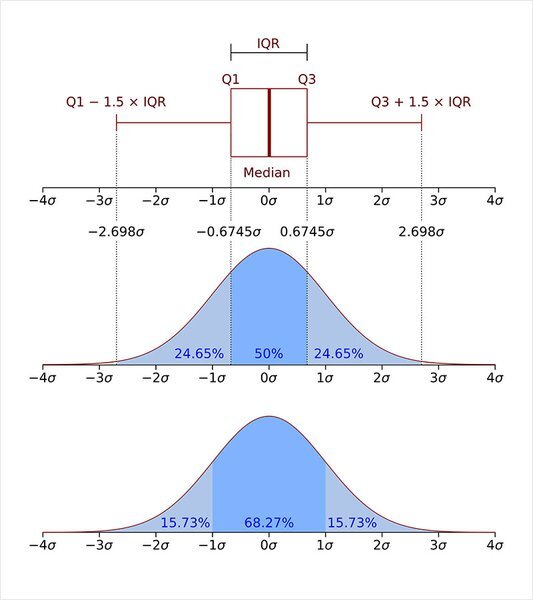
#Q1, Q3 값 구하기
Q3, Q1 = np.percentile(data, [75,25])
#IQR값 구하기
IQR = Q3 - Q1
#이상치 구하는 조건식
data[(Q1-1.5*IQR > data)|(Q3+1.5*IQR < data)]예제 데이터에서의 응용
Q3, Q1 = np.percentile(trade['무역수지'],[75,25])
IQR = Q3 - Q1
trade[(Q1-1.5*IQR < trade['무역수지'])|(Q3+1.5*IQR > trade['무역수지'])]
z-score 방법의 한계
z-score는 평균과 표준편차를 사용해서 이상치를 구한다
그러나 문제는 평균과 표준편차라는 요소는 이상치에 가장 영향을 받는 요소다.
그리고 데이터셋이 적으면 이상치를 찾기 난해하며, 그 값이 12개 이하라면 찾을 수 없다
정규화(Normalization)
데이터간의 범위값이 다를 경우, 값이 큰 컬럼 위주로 파라미터나
기타 데이터의 왜곡이 생길 가능성이 있음 (선형 회귀 등의 분석에서)
따라서 데이터의 정규화가 요구됨
정규화 예제를 위한 샘플 데이터
x = pd.DataFrame({'A':np.random.randn(100)*4+4,'B':np.random.randn(100)-1})
Standaridization

x_stan = (x-x.mean())/x.std()
x_stan
예제 데이터에 적용 해보기
cols = ['수출건수','수출금액','수입건수','수입금액','무역수지']
trade_Stan = (trade[cols]-trade[cols].mean())/trade[cols].std()
trade_Stan.head()
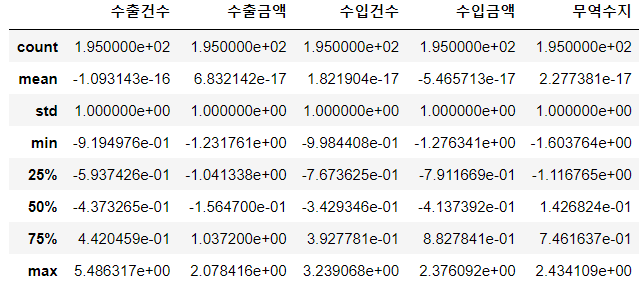
trade_Stan.describe()
Min-Max Scaling

x_min_max = (x-x.min())/(x.max()-x.min())
x_min_max
예제데이터에 적용해보기
trade[cols] = (trade[cols]-trade[cols].min())/(trade[cols].max()-trade[cols].min())
trade.head()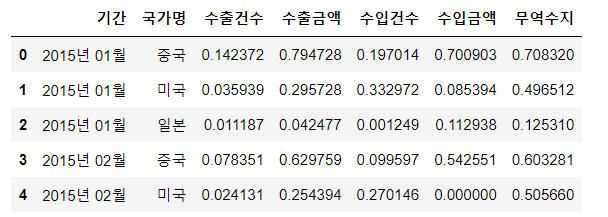
주의사항
Train데이터를 정규화시킨 기준은 Test 데이터에도 똑같이 정규화해야함
sciket-learn의 StandardScaler, MinMaxScaler 사용도 가능
from sklearn.preprocessing import MinMaxScaler
train = [[10, -10], [30, 10], [50, 0]]
test = [[0, 1]]
scaler = MinMaxScaler()
scaler.fit_transform(train)
scaler.transform(test)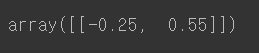
정규화의 필요성을 잘 설명해주는 링크
원 핫 인코딩(One - Hot Encoding)
원-핫 인코딩은 카테고리별 이진 특성을 만들어 해당하는 특성만 1
나머지는 0으로 만드는 방법
예제에 응용하기
#trade 데이터의 국가명 컬럼 원본
print(trade['국가명'].head())
# get_dummies를 통해 국가명 원-핫 인코딩
country = pd.get_dummies(trade['국가명'])
country.head()
이를 통해 컴퓨터가 해당 정보가 어느 나라에 대한 건지 알 수 있음
구간화(Binning)
예제 데이터 생성
salary = pd.Series([4300, 8370, 1750, 3830, 1840, 4220, 3020, 2290, 4740, 4600,
2860, 3400, 4800, 4470, 2440, 4530, 4850, 4850, 4760, 4500,
4640, 3000, 1880, 4880, 2240, 4750, 2750, 2810, 3100, 4290,
1540, 2870, 1780, 4670, 4150, 2010, 3580, 1610, 2930, 4300,
2740, 1680, 3490, 4350, 1680, 6420, 8740, 8980, 9080, 3990,
4960, 3700, 9600, 9330, 5600, 4100, 1770, 8280, 3120, 1950,
4210, 2020, 3820, 3170, 6330, 2570, 6940, 8610, 5060, 6370,
9080, 3760, 8060, 2500, 4660, 1770, 9220, 3380, 2490, 3450,
1960, 7210, 5810, 9450, 8910, 3470, 7350, 8410, 7520, 9610,
5150, 2630, 5610, 2750, 7050, 3350, 9450, 7140, 4170, 3090])Pandas를 통한 범주형 데이터 변형
bins = [0, 2000, 4000, 6000, 8000, 10000]
ctg = pd.cut(salary, bins=bins)
ctg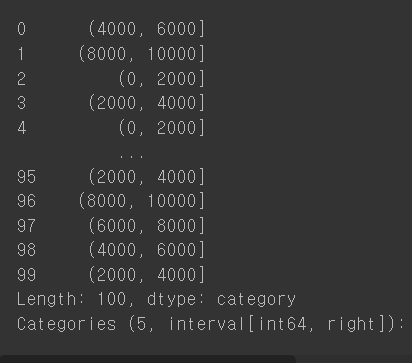
ctg는 범주값을 가지게 됨
ctg.value_counts().sort_index()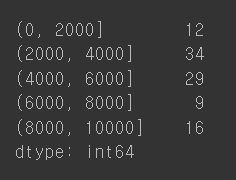
pd.cut의 bins를 개수값으로 넘기는 방법(데이터의 최소 최대를 균등하게 bins개수만큼)
ctg = pd.cut(salary, bins=6)
ctg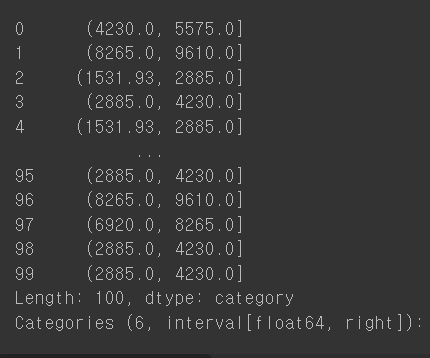
넘긴 숫자에 맞게 스마트하게 구간을 설정함
ctg.value_counts().sort_index()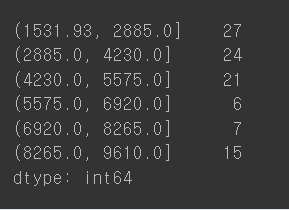
pd.qcut을 사용한 방법 (데이터의 분포를 비슷한 크기의 그룹으로)
ctg = pd.qcut(salary, q=5)
ctg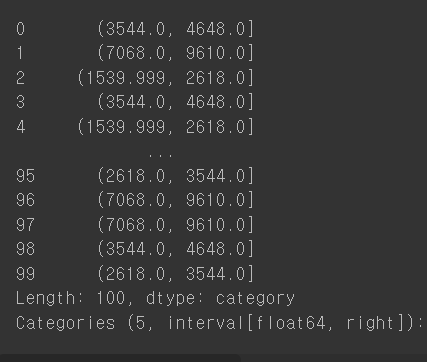
print(ctg.value_counts().sort_index())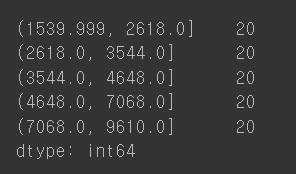
데이터의 개수가 동일하게 분류된 것을 볼 수 있다
'23년 이전 글 > 모두의연구소 아이펠' 카테고리의 다른 글
| -8일차- 데이터 시각화 (0) | 2022.01.05 |
|---|---|
| -7일차- 가위 바위 보 classification task (0) | 2022.01.04 |
| -4일차- 제너레이터, 딕셔너리의 copy (0) | 2021.12.30 |
| -3일차- 아이펠 일일 공부, 새싹 졸업자의 세미나 (0) | 2021.12.29 |
| -2일차- 첫수업, 재귀함수, 부동소수점 (0) | 2021.12.28 |